2026世界人工智能大会暨人工智能全球治理高级别会议
世界人工智能大会官网84 字 (约 1 分钟)
95
2026世界人工智能大会于7月17日至20日在上海举行,议题覆盖模型、智能体、算力、具身智能、科学智能和全球人工智能治理。
入选理由:大会于2026年7月17日至20日在上海举行
精选文章#WAIC 2026#世界人工智能大会#人工智能全球治理高级别会议#上海中文
traeai 主题雷达
聚合 robotics、具身智能、空间理解、机器人基础模型、仿真训练与产业应用内容。
想追踪机器人和具身智能领域的新模型、新系统和真实应用案例。
具身智能正在把模型能力带入物理世界,是 AI 长周期趋势中最值得持续观察的方向之一。
这个主题可以沿着工具、实践、对比等搜索意图持续扩展,不靠空壳换词,而是用真实材料更新。
持续抓取与 机器人与具身智能 相关的高分文章、播客、视频和推文。
把最近变化、反复出现的观点和争议点整理成稳定摘要。
自动连接相关公司、模型、产品、人物和概念,形成可继续深挖的入口。
按相关度、评分和更新时间筛出的可读内容。
2026世界人工智能大会于7月17日至20日在上海举行,议题覆盖模型、智能体、算力、具身智能、科学智能和全球人工智能治理。
入选理由:大会于2026年7月17日至20日在上海举行
上交x创智x瑞金联合发布CX-Mind,实现胸片诊断进入‘可验证推理’时代,通过多模态大模型和强化学习技术,提升医学影像AI的可解释性与临床实用性。
入选理由:CX-Mind是首个实现胸片诊断进入‘可验证推理链’的多模态大模型,提升医学影像AI的可解释性与临床实用性。
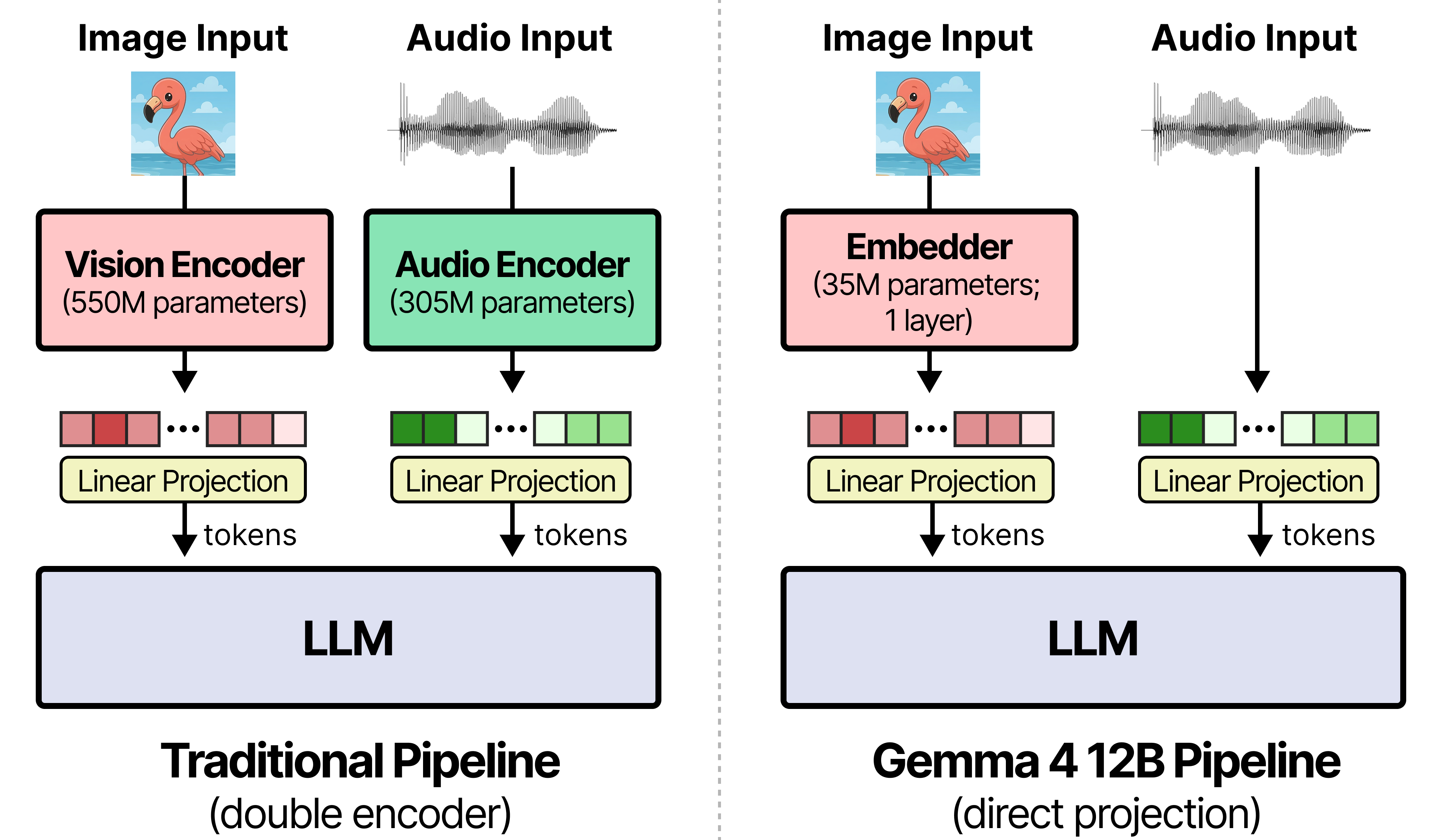
Gemma 4 12B采用无编码器多模态架构,可在16GB显存设备上本地运行并原生支持音频输入。该模型通过移除独立视觉与音频编码器显著降低延迟,配合专用MTP模型提升推理速度,是首个支持macOS桌面端全离线交互的中型多模态模型。
入选理由:Gemma 4 12B移除独立编码器,视觉仅用35M参数嵌入层,音频直接线性投影至LLM输入空间
VAST完成近2亿美元融资并披露Project Eden世界模型路线,首创状态推演与视觉渲染解耦架构,支持多人持久化交互、模块化复用和线性算力扩展,为AI原生沙盒与具身智能仿真提供底层基础设施。
入选理由:VAST获近2亿美元A+/A++轮融资,投资方包括渶策资本、国寿长三角科创基金及荣耀、上汽等产业资本。
NVIDIA Cosmos 3 是首个开源物理AI全能模型,整合世界生成、物理推理与动作生成于单模型,支持机器人、自动驾驶等场景,基于MoT架构并提供Hugging Face集成。
入选理由:Cosmos 3 是首个统一物理AI能力的开源模型,融合世界生成、物理推理与动作生成于单模型。
NVIDIA 推出 Cosmos 3,首个融合语言、视频、声音与动作的多模态统一模型,采用 Mixture of Transformer 架构,支持开源定制与边缘部署,已在多项物理AI基准测试中登顶。
入选理由:Cosmos 3 是首个整合语言/视频/声音/动作输入输出的 omni 模型,基于 Mixture of Transformer 架构。
自变量机器人发布全球首个事件级预测具身智能世界模型WALL-WM,将预测单位从时间帧升级为语义事件(如“抓取”“放置”),显著提升跨场景泛化能力与动作鲁棒性。
入选理由:WALL-WM以语义事件(如抓取、抬升)为建模单元,替代传统固定时长动作块,使动作长度可变且更符合物理逻辑
科大讯飞首款AI眼镜以40克超轻设计+端到端语音同传+唇动识别降噪为核心,将翻译能力嵌入真实工作流,直击30%~50%高退货率痛点;其成功关键在于系统级工程优化与多年翻译场景数据沉淀,而非单纯硬件参数竞争。
入选理由:讯飞AI眼镜整机仅40克(带显示屏),为行业最轻,通过树脂镜片全贴合工艺减重30%~40%,突破亚洲用户45克舒适阈值
Ophiuchus-7B在8个医学VQA基准上以68.0分超越OpenAI-o3(62.2)、Gemini 2.5 Pro(61.8)和GPT-5(59.9),核心突破在于提出‘Think with Images/Videos’新范式:模型在推理链中主动调用SAM2、BiomedParse等工具重新观察关键区域/时刻,使视觉证据成为思维过程的一部分,而非仅作输入。
入选理由:Ophiuchus-7B在8个医学VQA benchmark平均得分68.0,显著高于o3(62.2)、Gemini 2.5 Pro(61.8)与GPT-5(5
GPT-4标志着大型语言模型从实验性研究向实用化AI平台的转变,引入多模态处理和对齐技术。
入选理由:GPT-4支持文本与图像输入,推动AI系统向通用化发展。
蚂蚁灵波与港科大合作的LingBot-VA模型被RSS 2026接收,实现机器人边推演边行动的能力。
入选理由:LingBot-VA在RoboTwin 2.0测试中达成92.0%成功率
Genesis AI发布首个机器人基础模型GENE-26.5,实现打蛋、解魔方、弹钢琴等复杂任务,全程自主运行且仅需少量真实数据微调。
入选理由:GENE-26.5使用统一模型处理多任务,支持多模态输入,大部分技能仅需不到1小时真实数据训练。
华人15人团队Luma AI发布AI生图模型Uni-1.1,以推理生成一体化架构、价格腰斩和广告级落地能力,冲入全球前三,成为OpenAI与Google之外的最优解,重新定义品牌视觉生产的可控性与效率。
入选理由:Uni-1.1将推理与生成融合于单一模型,实现品牌一致性、多参考图约束和按句编辑,解决传统AI生图不可控痛点。
Senqi AI 使用 Milvus 向物理机器人注入长期语义记忆能力,解决真实世界任务中环境动态、任务无界、指令模糊和错误高成本等核心挑战。
入选理由:物理机器人Agent需实时重规划,因环境持续变化且任务无明确终点
普林斯顿Zhuang Liu指出:AI性能瓶颈不在架构创新,而在数据质量与记忆机制;视觉是多模态枢纽但受算力制约;语言模型已具备强抽象世界模型。
入选理由:架构细节(归一化、激活函数等)的组合效应远超核心组件选择
NVIDIA 推出 Nemotron 3 Nano Omni,支持文本、图像、视频和音频的多模态理解,性能领先多个复杂任务基准。
入选理由:Nemotron 3 Nano Omni 在文档、语音、视频等多模态任务中达到顶级精度。
美团提出LARYBench,定义首个具身动作表征评测基准,验证通用视觉模型在动作泛化和控制精度上的优势。
入选理由:LARYBench填补了动作表征领域缺乏标准化评测的空白。
IBISAgent通过多步交互决策重新定义医学图像分割,解决了隐式token导致的推理退化问题,显著提升分割精度。
入选理由:将分割任务建模为多步马尔可夫决策过程,保留语言推理能力
第一财经从国产芯片、超节点、智能体、具身智能、消费终端、初创企业、绿色算力和学术嘉宾等方向梳理大会现场重点。
入选理由:大会展示重点从单点模型延伸到算力、智能体和具身智能产业链
NVIDIA 推出 Cosmos 3,一个基于新型混合 Transformer 架构的开放通用模型,专为物理 AI 设计,能生成物理准确的合成视频、作为世界模型和模拟器,并支持机器人等实体智能系统的训练与推理。
入选理由:Cosmos 3 使用新型混合 Transformer 架构,结合自回归和扩散 Transformer 实现感知、推理与生成。
清华大学AIR DISCOVER Lab开源UniLab,通过异构并行架构实现机器人运控训练效率提升3-10倍,支持Mac本地运行,3分钟完成人形机器人训练,标志着具身智能训练进入分钟级时代。
入选理由:UniLab采用CPU仿真+GPU训练的异构架构,实现3-10倍端到端训练加速。
黑森林实验室斯蒂芬·巴蒂福尔发布 FLUX 开源视觉生成模型,强调开放研究对 AI 可持续发展的重要性,性能媲美闭源领先模型。
入选理由:FLUX 支持 1024×1024 分辨率图像生成,质量接近闭源 SOTA 模型。
清华大学AIR DISCOVER Lab等机构联合推出GS-Playground,这是一个专为视觉中心的机器人学习设计的新一代仿真框架,实现了高吞吐量并行物理仿真与高保真视觉渲染的融合,助力具身智能规模化训练,已被RSS 2026顶级会议录用。
入选理由:GS-Playground解决了高保真视觉渲染与大规模训练之间的矛盾,提供稳定高效的仿真平台。
自变量机器人发布全球首个世界统一模型WALL-B,打通视觉、听觉、语言和触觉模块,赋予机器人原生多模态能力和持续进化能力。
入选理由:WALL-B基于世界统一模型,解决了传统VLA架构中模块间数据搬运的问题。
清华AIR联合多家机构开源GS-Playground仿真框架,首次融合高吞吐并行物理仿真与高保真视觉渲染,显著提升具身智能规模化训练效率。
入选理由:支持CPU/GPU双后端及全系统原生运行,适配四足/人形/机械臂等多类机器人
跨维智能在World Arena Track 2登顶全球第一,显著领先第二名,验证其具身世界模型在数据生成、策略训练与任务落地的全链路硬实力。
入选理由:跨维智能DSCFuncWorld在World Arena Track 2以高任务成功率登顶,领先第二名约25%分差。
Gemma-4 12B 采用统一无编码器架构,图像与音频直连 LLM,可在 16GB 设备本地运行;性能接近 26B MOE 且内存不足其半,配套 Hermes 等 Agent 工具与 macOS Edge Gallery,采用 Apache 2.0 开源许可。
入选理由:图像与音频直接映射到 LLM,移除编码器以降延迟与内存。
Gemma 4 12B 是面向本机运行的统一、无编码器多模态模型,将视觉与音频直接接入 LLM,性能接近 26B MoE 但内存仅其一半,可在 16GB VRAM 紧凑设备上运行,支持离线语音处理与低延迟多步推理。
入选理由:Gemma 4 12B 性能接近 26B MoE,内存仅其一半,适合在 16GB VRAM 现代本机运行。
企业数据治理不应依赖聊天机器人,关系型与时间序列数据正迎来专用基础模型的突破,KumoRFM-2在少标注下超越监督与通用基模,但高风险金融与医疗场景需谨慎验证与治理。
入选理由:KumoRFM-2仅用少量标注即可在多表关系数据上预测,超越监督基线与通用基模,显著降低数据科学管线复杂度。
百度文心发布 PaddleOCR-VL-1.6,在 OmniDocBench v1.6 上准确率突破 96.33%,刷新文档解析 SOTA,综合性能全球第一,显著提升复杂场景下的文本、公式、表格识别能力。
入选理由:PaddleOCR-VL-1.6 在 OmniDocBench v1.6 上准确率达 96.33%,超越 Gemini-3-Pro、GPT-5.2 等主流模型。