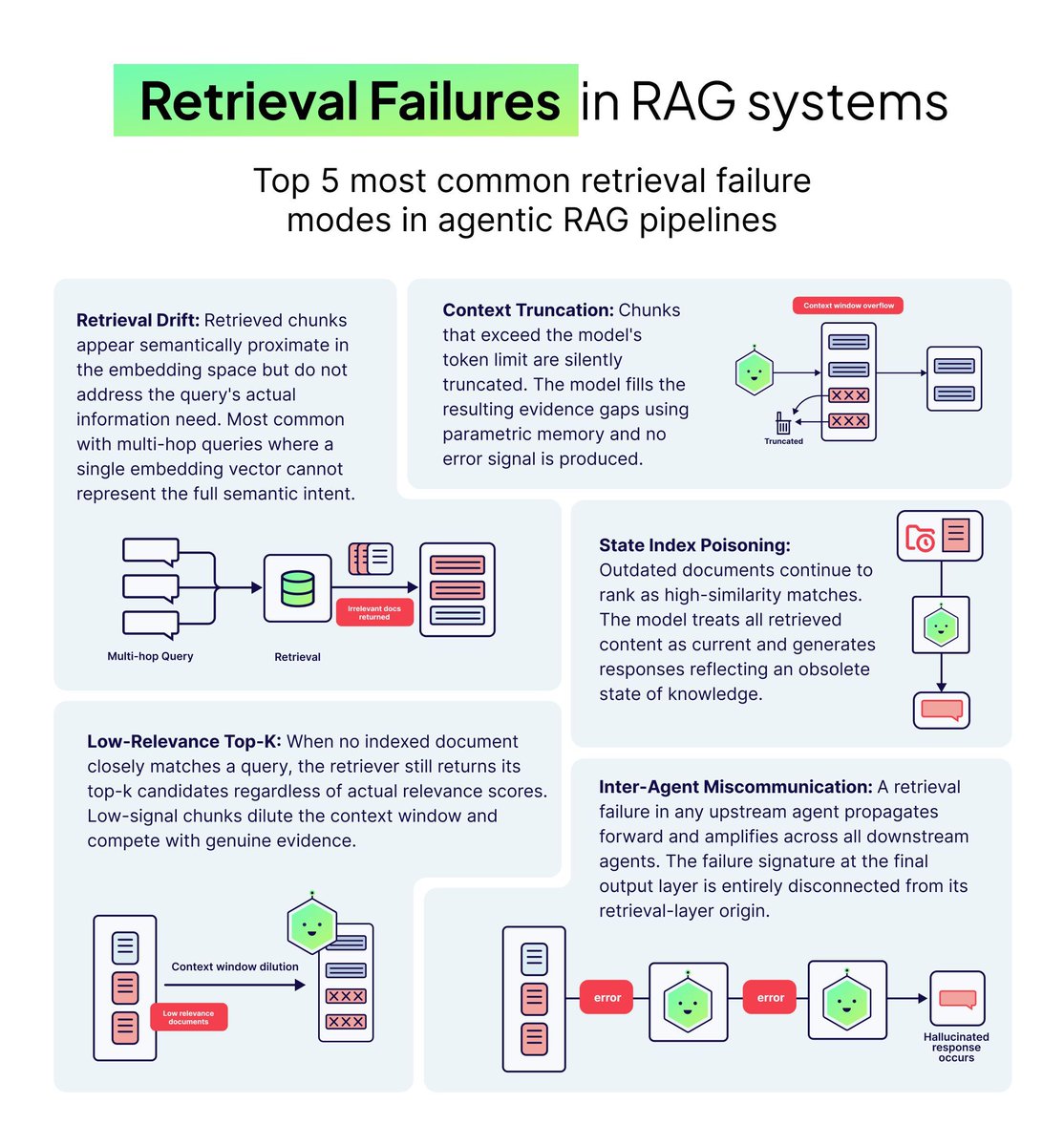
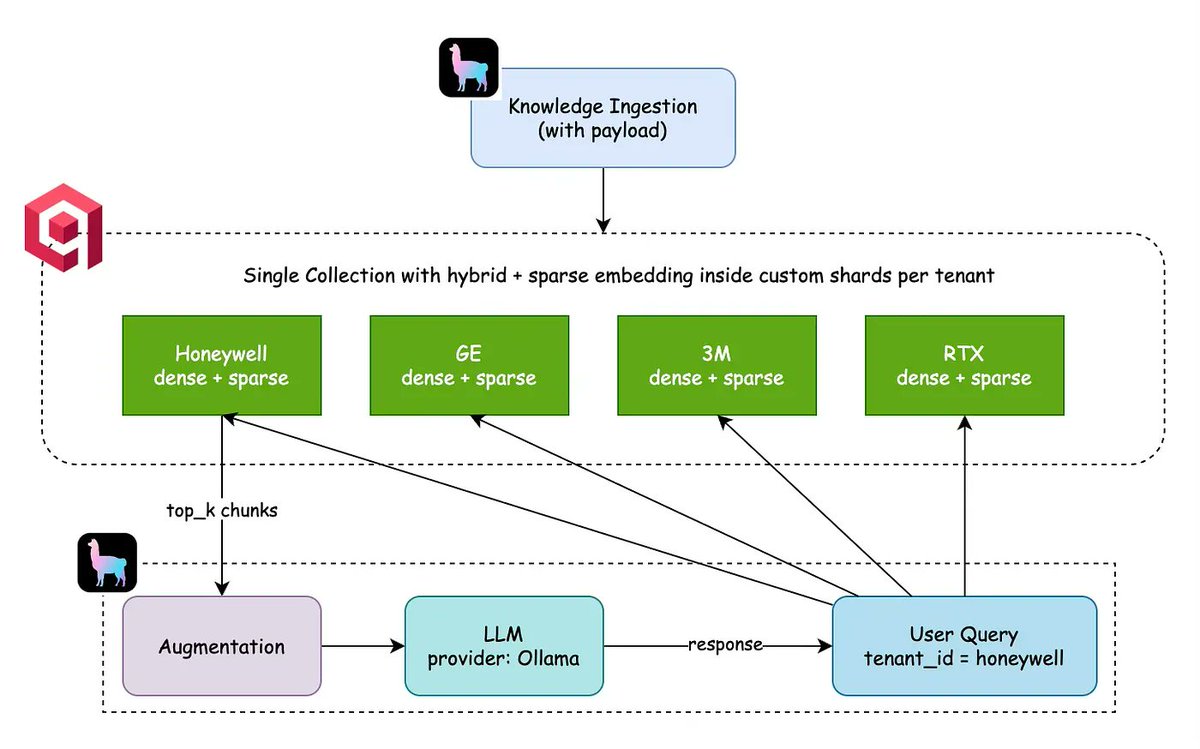
多向量检索策略选型:分离度决定nDCG@10成败
Milvus(@milvusio)340 字 (约 2 分钟)
92
多向量检索中近似策略选择错误会导致nDCG@10下降6倍,影响远超模型升级收益。应通过计算Token向量MaxSim标准差判断嵌入空间分离度:高分散选TokenANN/MUVERA,低分散选LEMUR,避免盲目调优。
入选理由:同模型数据集下,错误近似策略使nDCG@10从0.701跌至0.109,损失超模型升级收益
精选推文#多向量检索#ColBERT#Milvus#近似搜索#RAG英文