Anthropic 内部设计师如何用 Claude Code 做产品、写代码、推 PR
meng shao(@shao__meng)1666 字 (约 7 分钟)
92
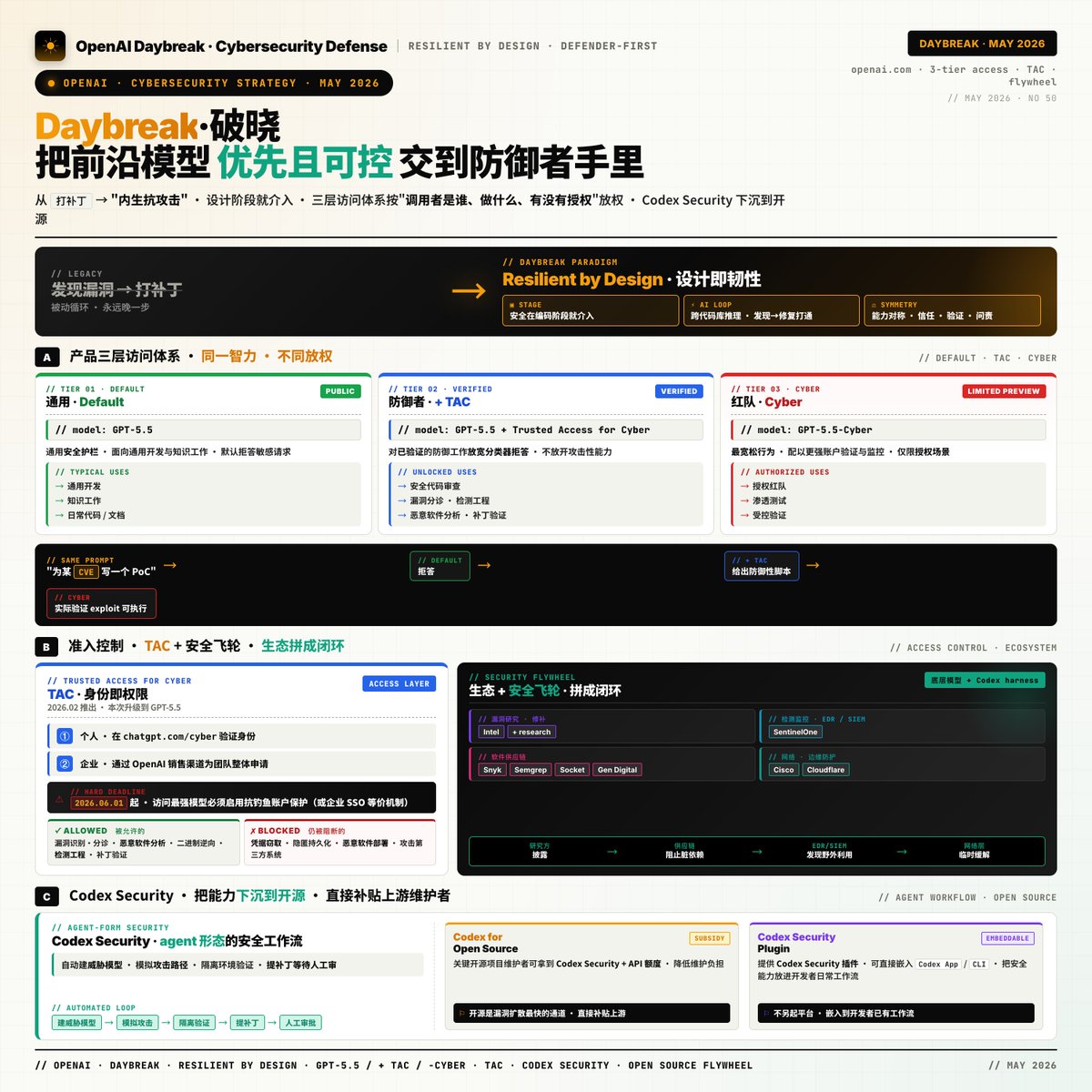
Anthropic设计负责人验证了以“带视觉证据的PR”为验收单位的AI工作流,通过自定义Skill、Auto模式及定时巡检任务,将设计师从代码执行者转变为审美决策者与质量治理者。
入选理由:使用/prototype Skill让AI生成5个方案并自选最优解,人仅做最终审美确认。
精选推文#Claude Code#AI Workflow#Design Engineering#Anthropic#Excalidraw中文