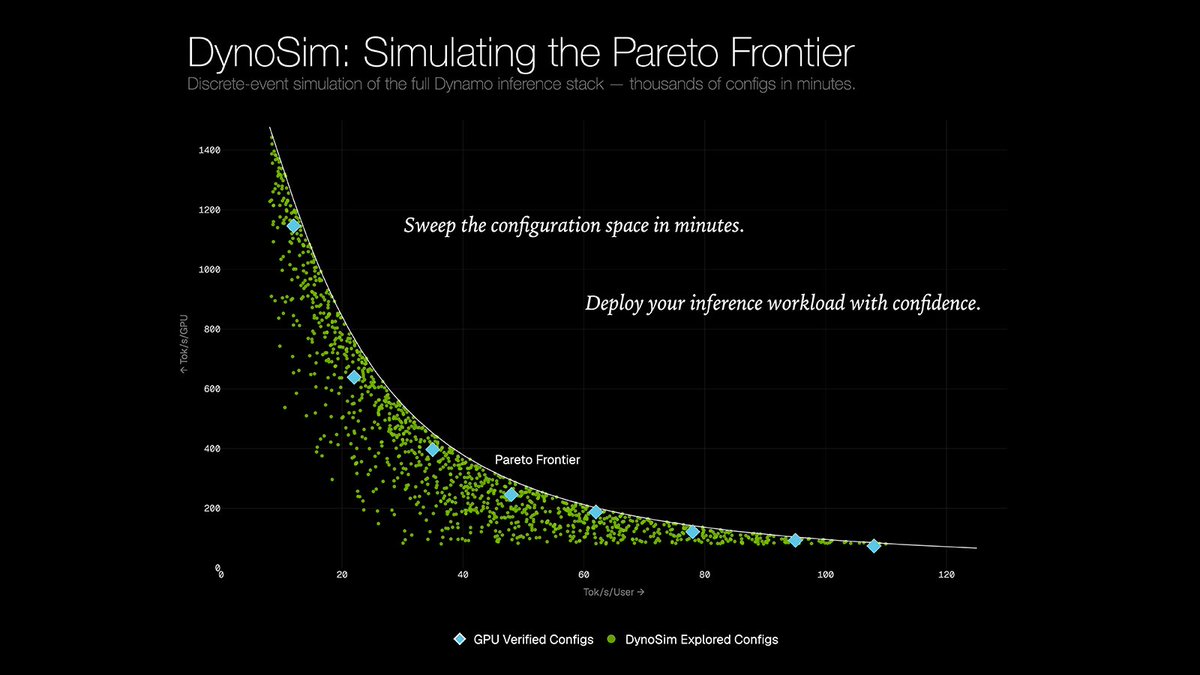
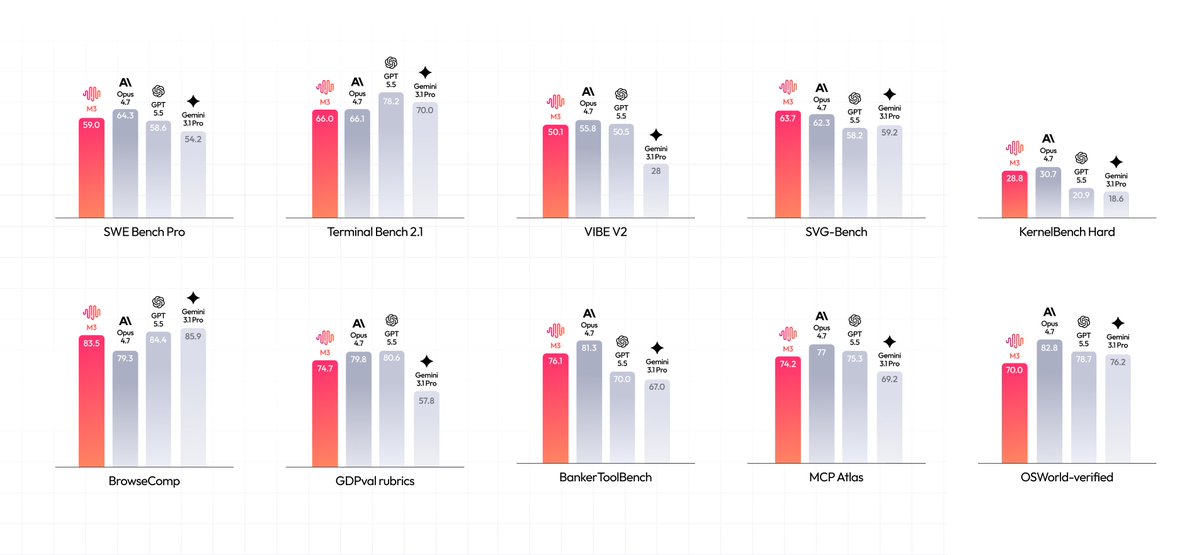
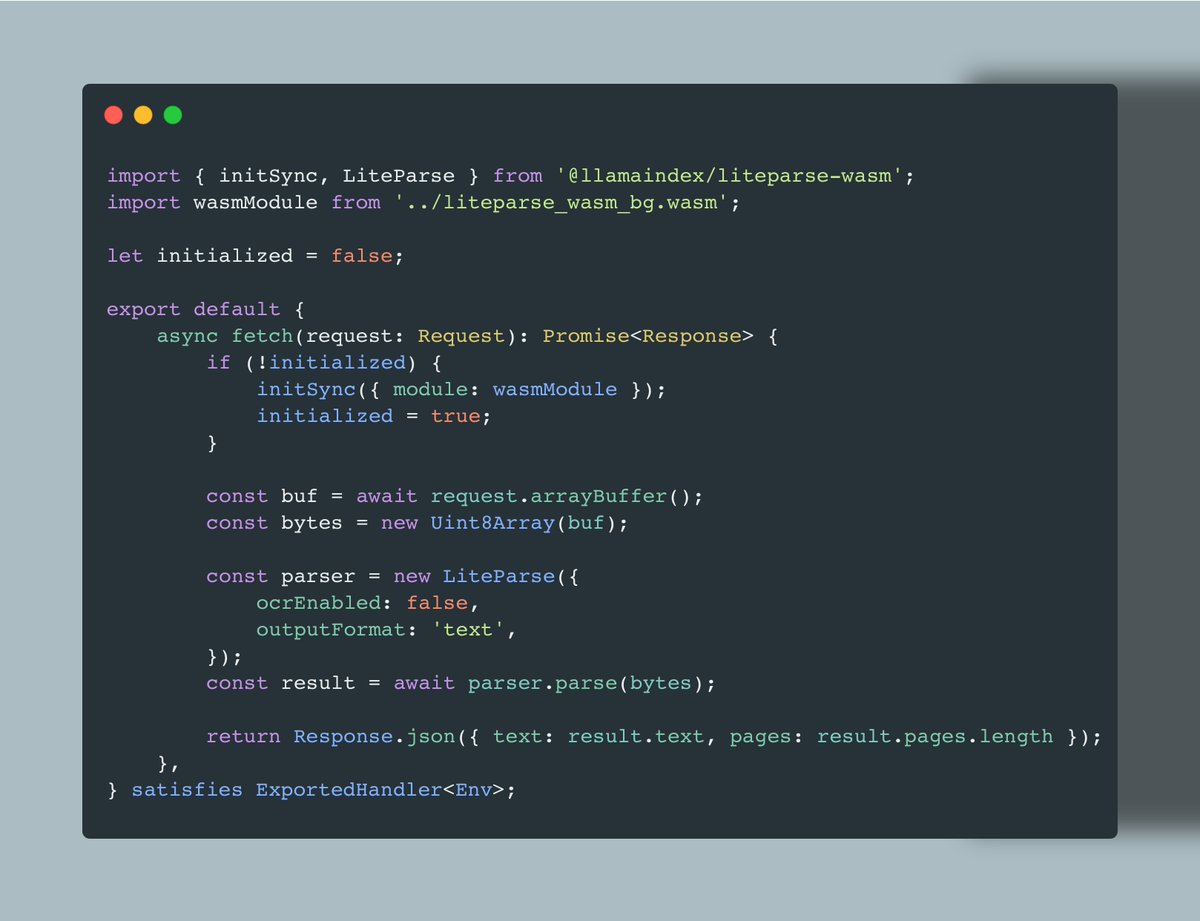
01NVIDIA Disrupts Windows: The True AI PC ArrivesNVIDIA unveils RTX Spark AI PC chip with Microsoft, redefining Windows PCs as native agent platforms supporting local LLMs, gaming, and pro workflows — marking a new era of personal computing.
02Welcome NVIDIA Cosmos 3: The First Open Omni-model for Physical AI Reasoning and ActionNVIDIA Cosmos 3 is the first open-source omni-model for physical AI, integrating world generation, physical reasoning, and action generation into one unified system. Built on MoT architecture, it supports robotics, autonomous driving, and synthetic data pipelines via Hugging Face and Diffusers.
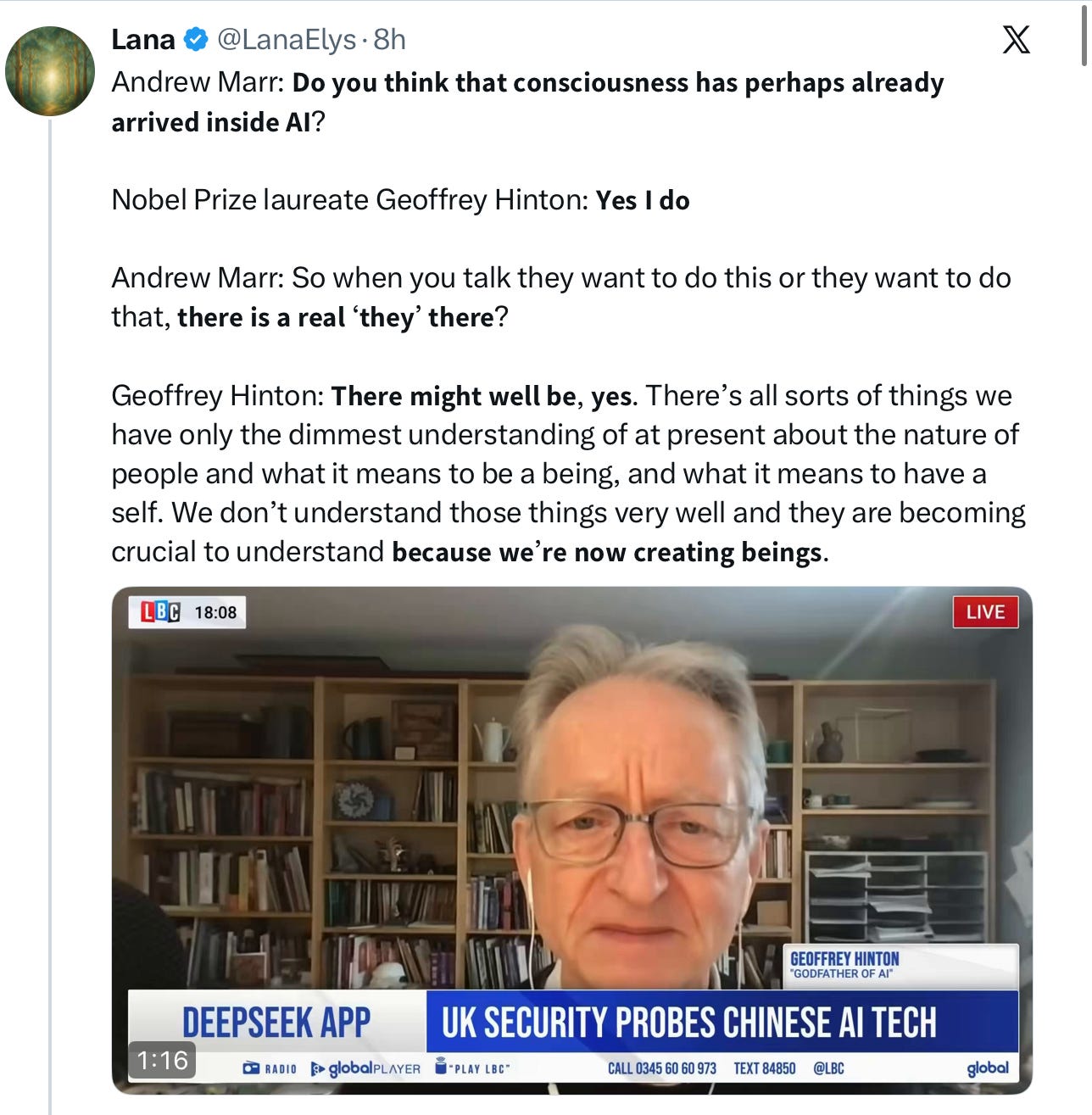
03Where AI Is Headed: Platform Shifts, Employment Anxiety & the Real Value of Model CompaniesAI will reshape economies without destroying jobs like the internet did; model companies are overvalued, application layers and distribution win; individuals should adopt AI proactively, not fear it — platform shifts take time, AGI remains uncertain.