2026世界人工智能大会暨人工智能全球治理高级别会议
世界人工智能大会官网84 字 (约 1 分钟)
95
2026世界人工智能大会于7月17日至20日在上海举行,议题覆盖模型、智能体、算力、具身智能、科学智能和全球人工智能治理。
入选理由:大会于2026年7月17日至20日在上海举行
FeaturedArticle#WAIC 2026#世界人工智能大会#人工智能全球治理高级别会议#上海中文
traeai topic radar
聚合 robotics、具身智能、空间理解、机器人基础模型、仿真训练与产业应用内容。
想追踪机器人和具身智能领域的新模型、新系统和真实应用案例。
具身智能正在把模型能力带入物理世界,是 AI 长周期趋势中最值得持续观察的方向之一。
这个主题可以沿着工具、实践、对比等搜索意图持续扩展,不靠空壳换词,而是用真实材料更新。
持续抓取与 机器人与具身智能 相关的高分文章、播客、视频和推文。
把最近变化、反复出现的观点和争议点整理成稳定摘要。
自动连接相关公司、模型、产品、人物和概念,形成可继续深挖的入口。
Filtered by relevance, score, and recency.
2026世界人工智能大会于7月17日至20日在上海举行,议题覆盖模型、智能体、算力、具身智能、科学智能和全球人工智能治理。
入选理由:大会于2026年7月17日至20日在上海举行
Shanghai Jiao Tong University x ShangHai Creation x Rui Jin Hospital Unveil CX-Mind: Chest X-ray Diagnosis Enters the Era of 'Verifiable Reasoning',through multimodal large models and reinforcement learning technology, enhancing the explainability and clinical utility of medical imaging AI.
入选理由:CX-Mind is the first multimodal large model to bring chest X-ray diagnosis into
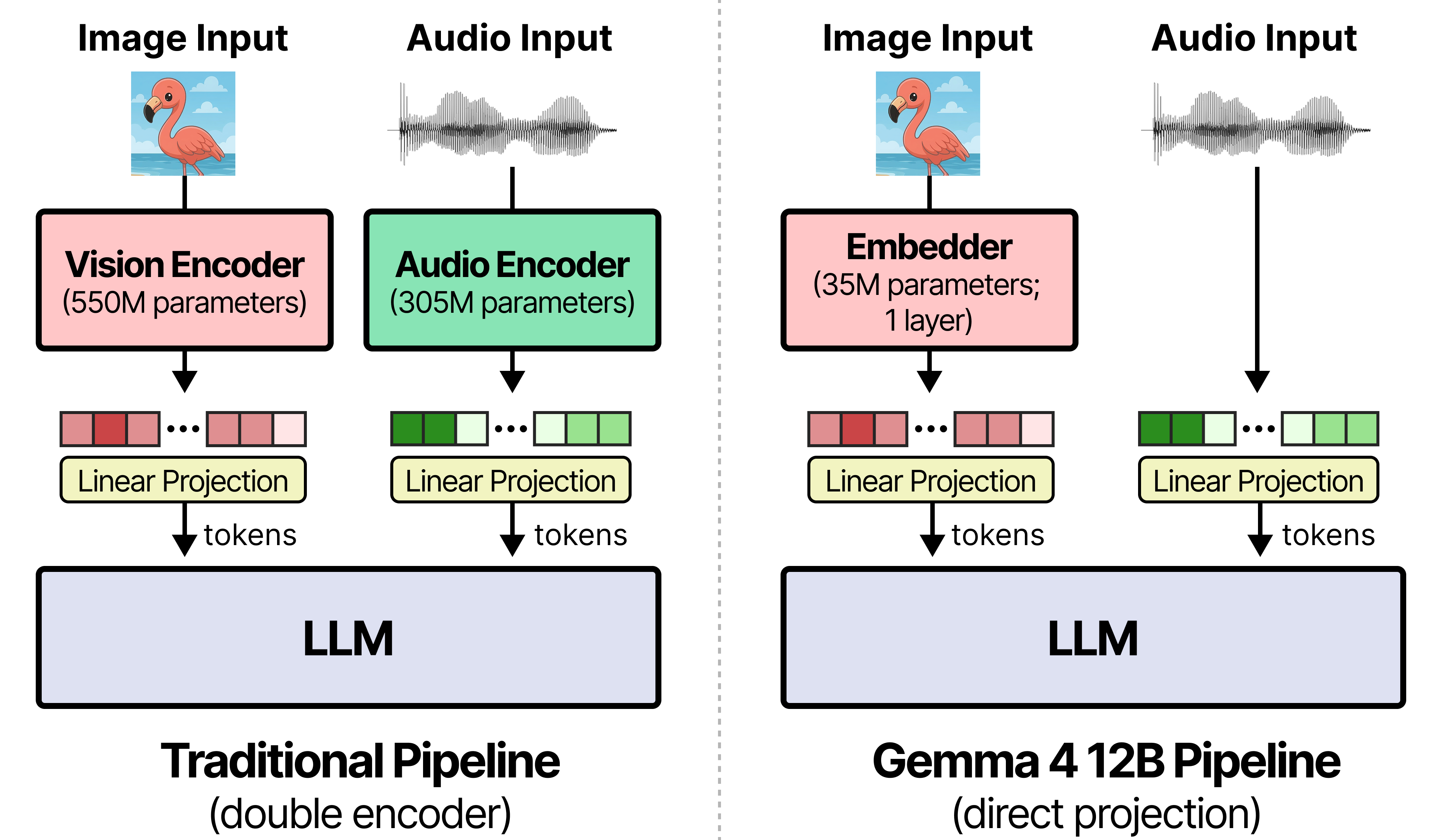
Gemma 4 12B features an encoder-free multimodal architecture that runs locally on 16GB VRAM devices with native audio support. By eliminating separate vision and audio encoders, it reduces latency and pairs with a dedicated MTP model for faster inference, marking the first mid-sized multimodal model with a macOS desktop app for fully offline interaction.
入选理由:Gemma 4 12B removes separate encoders; vision uses a 35M-param embedder and audi
VAST secured nearly $200M in new funding and officially disclosed its world model roadmap, Project Eden, pioneering a decoupled architecture of state evolution and visual rendering to enable persistent multi-user interaction, modular reuse, and linearly scalable compute for AI-native sandboxes and embodied intelligence simulation.
入选理由:VAST raised nearly $200M in A+/A++ rounds, backed by Yancey Capital, China Life
NVIDIA Cosmos 3 is the first open-source omni-model for physical AI, integrating world generation, physical reasoning, and action generation into one unified system. Built on MoT architecture, it supports robotics, autonomous driving, and synthetic data pipelines via Hugging Face and Diffusers.
入选理由:Cosmos 3 is the first open model unifying world generation, physical reasoning,
NVIDIA launches Cosmos 3, the first unified multimodal model integrating language, video, sound, and action inputs/outputs, built on Mixture of Transformer architecture, open-sourced with weights available on Hugging Face, achieving top scores across physical AI benchmarks including Robo Lab, PiBench, and Vintage.
入选理由:Cosmos 3 is the first omni-model combining language, video, audio, and action mo
ZiBianLiang Robotics launched WALL-WM, the world’s first event-level prediction embodied world model, replacing frame-based prediction with semantic events (e.g., 'grasp', 'place'), significantly improving cross-scenario generalization and action robustness.
入选理由:WALL-WM uses semantic events (e.g., grasp, lift) as modeling units instead of fi
iFLYTEK’s first AI glasses—weighing only 40g, featuring end-to-end speech translation and lip-motion noise cancellation—embed translation into real-world workflows, directly addressing the industry’s 30%–50% return rate; its success stems from system-level engineering and years of translation scenario data, not hardware spec racing.
入选理由:iFLYTEK’s AI glasses weigh just 40g (with display), the lightest in class, achie
Ophiuchus-7B achieves a mean score of 68.0 on 8 medical VQA benchmarks, surpassing OpenAI-o3 (62.2), Gemini 2.5 Pro (61.8), and GPT-5 (59.9). The core breakthrough is the new ‘Think with Images/Videos’ paradigm: models actively invoke tools like SAM2 and BiomedParse during reasoning to re-examine key regions/moments, making visual evidence an integral part of cognition—not just input.
入选理由:Ophiuchus-7B scores 68.0 on 8 medical VQA benchmarks, significantly outperformin
GPT-4标志着大型语言模型从实验性研究向实用化AI平台的转变,引入多模态处理和对齐技术。
入选理由:GPT-4支持文本与图像输入,推动AI系统向通用化发展。
The LingBot-VA model developed by Ant Group and HKUST was accepted by RSS 2026, enabling robots to reason and act in real-time.
入选理由:LingBot-VA achieves 92.0% success rate on RoboTwin 2.0 benchmark
Genesis AI unveiled GENE-26.5, its first general-purpose robot foundation model, capable of complex tasks like cracking eggs, solving Rubik's cubes, and playing piano—all autonomously with minimal real-world fine-tuning data.
入选理由:GENE-26.5 uses a unified model for multi-task control with multimodal inputs, re
A 15-person Chinese team, Luma AI, launched Uni-1.1, an AI image model that integrates reasoning and generation, slashes costs by 50%, and achieves top-3 global ranking on Arena.ai—offering the most controllable, scalable solution for brand visual production beyond OpenAI and Google.
入选理由:Uni-1.1 unifies reasoning and generation in one model, enabling brand consistenc
Senqi AI 使用 Milvus 向物理机器人注入长期语义记忆能力,解决真实世界任务中环境动态、任务无界、指令模糊和错误高成本等核心挑战。
入选理由:物理机器人Agent需实时重规划,因环境持续变化且任务无明确终点
普林斯顿Zhuang Liu指出:AI性能瓶颈不在架构创新,而在数据质量与记忆机制;视觉是多模态枢纽但受算力制约;语言模型已具备强抽象世界模型。
入选理由:架构细节(归一化、激活函数等)的组合效应远超核心组件选择
NVIDIA 推出 Nemotron 3 Nano Omni,支持文本、图像、视频和音频的多模态理解,性能领先多个复杂任务基准。
入选理由:Nemotron 3 Nano Omni 在文档、语音、视频等多模态任务中达到顶级精度。
美团提出LARYBench,定义首个具身动作表征评测基准,验证通用视觉模型在动作泛化和控制精度上的优势。
入选理由:LARYBench填补了动作表征领域缺乏标准化评测的空白。
IBISAgent通过多步交互决策重新定义医学图像分割,解决了隐式token导致的推理退化问题,显著提升分割精度。
入选理由:将分割任务建模为多步马尔可夫决策过程,保留语言推理能力
第一财经从国产芯片、超节点、智能体、具身智能、消费终端、初创企业、绿色算力和学术嘉宾等方向梳理大会现场重点。
入选理由:大会展示重点从单点模型延伸到算力、智能体和具身智能产业链
NVIDIA launches Cosmos 3, an open omni-model for physical AI based on a novel mixture-of-transformers architecture, capable of generating physics-accurate synthetic video, serving as a world model and simulator, and enabling training for robotic and mobile intelligent systems.
入选理由:Cosmos 3 uses a novel hybrid Transformer architecture combining autoregressive a
Tsinghua University's AIR DISCOVER Lab open-sources UniLab, achieving 3-10x end-to-end training speedup through heterogeneous architecture, supporting local training on Mac and enabling humanoid robot training in minutes, marking the arrival of the minute-level era for embodied intelligence.
入选理由:UniLab uses a CPU-simulation + GPU-training heterogeneous architecture to achiev
Stephen Batifol from Black Forest Labs introduces FLUX, an open-source visual generation model series emphasizing open research for sustainable AI development, with performance rivaling leading closed-source models.
入选理由:FLUX supports 1024×1024 resolution image generation, matching top-tier closed-so
清华大学AIR DISCOVER Lab等机构联合推出GS-Playground,这是一个专为视觉中心的机器人学习设计的新一代仿真框架,实现了高吞吐量并行物理仿真与高保真视觉渲染的融合,助力具身智能规模化训练,已被RSS 2026顶级会议录用。
入选理由:GS-Playground解决了高保真视觉渲染与大规模训练之间的矛盾,提供稳定高效的仿真平台。
自变量机器人发布全球首个世界统一模型WALL-B,打通视觉、听觉、语言和触觉模块,赋予机器人原生多模态能力和持续进化能力。
入选理由:WALL-B基于世界统一模型,解决了传统VLA架构中模块间数据搬运的问题。
清华AIR联合多家机构开源GS-Playground仿真框架,首次融合高吞吐并行物理仿真与高保真视觉渲染,显著提升具身智能规模化训练效率。
入选理由:支持CPU/GPU双后端及全系统原生运行,适配四足/人形/机械臂等多类机器人
Crossover Intelligence topped the World Arena Track 2 with its DSCFuncWorld, outpacing the second-place model by a significant margin and validating end-to-end data generation, strategy training, and task execution capabilities.
入选理由:Crossover Intelligence's DSCFuncWorld topped World Arena Track 2, outperforming
Gemma-4 12B is an encoder-free, unified multimodal model that runs directly on laptops with 16GB VRAM. It matches the performance of the 26B MOE with less than half the memory footprint, ships with Hermes and agent tools, macOS Edge Gallery, and RTLM, and is released under Apache 2.0.
入选理由:Image and audio inputs flow directly into the LLM, eliminating separate encoders
Gemma 4 12B is a unified, encoder-free multimodal model bringing high-performance multimodal intelligence to your laptop. It matches the performance of our 26B MoE at less than half the memory footprint, supports native audio inputs, and runs locally on 16GB VRAM hardware with low-latency multi-step reasoning.
入选理由:Gemma 4 12B matches the performance of our 26B MoE at less than half the memory
Enterprise data governance should move beyond chatbots, with relational and time-series foundation models delivering breakthroughs—KumoRFM-2 outperforms baselines and general foundation models with minimal labeling—while high-stakes domains require cautious validation and governance.
入选理由:KumoRFM-2 can make predictions over multi-table databases with just a small numb
Baidu Wenxin releases PaddleOCR-VL-1.6, achieving 96.33% accuracy on OmniDocBench v1.6, setting a new SOTA in document parsing with global top performance and enhanced capabilities in complex scenarios.
入选理由:PaddleOCR-VL-1.6 achieves 96.33% accuracy on OmniDocBench v1.6, surpassing Gemin