Introducing the GKE standby buffer: Improve node startup times without blowing your budget
Google Cloud Blog1565 字 (约 7 分钟)
92
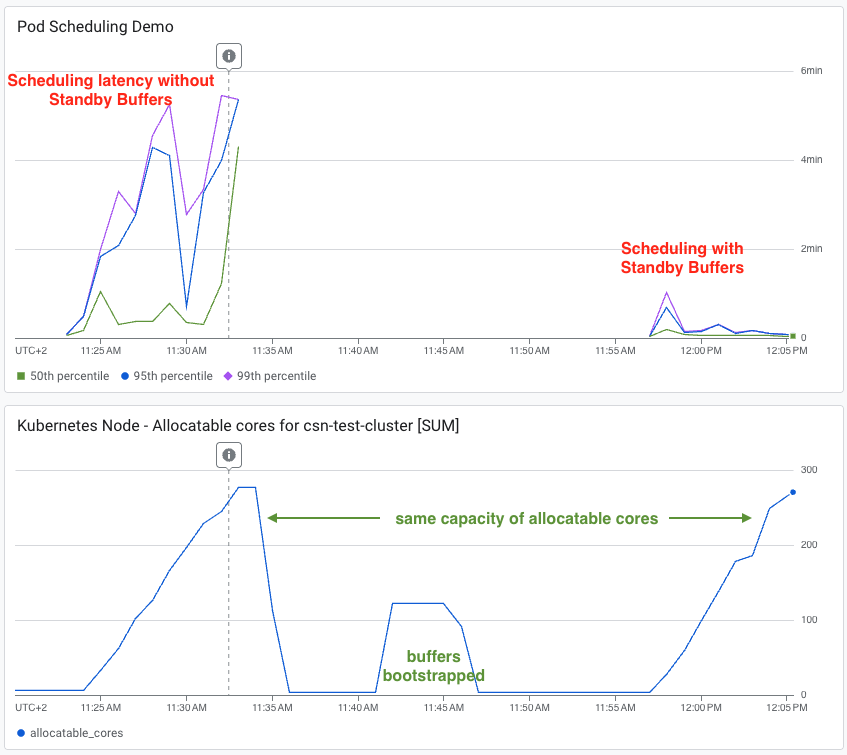
GKE standby buffers reduce node startup time to 2-3x faster than cold starts with <5% cost overhead, cutting P50 latency from minutes to seconds for all workloads.
入选理由:GKE standby buffers add only low single-digit % cost but cut P50 latency from 4-
FeaturedArticle#GKE#Kubernetes#Autoscaling#Google Cloud英文




















![[AINews] NVIDIA Cosmos 3, Nemotron 3 Ultra, and RTX Spark](https://substackcdn.com/image/fetch/$s_!5bzA!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Ff6685277-4569-4135-92cb-e7a645246125_4096x2732.jpeg)