GLM-5.2: Built for Long-Horizon Tasks
Hugging Face Blog3229 字 (约 13 分钟)
85
GLM-5.2 是 Z.AI 推出的最新模型,支持 1M 上下文长度,显著提升长周期任务处理能力,并在多个基准测试中表现优异。
入选理由:GLM-5.2 支持 1M 上下文长度,显著提升长周期任务处理能力。
FeaturedArticle#GLM-5.2#长周期任务#Hugging Face#开源模型英文
模型对比
Opus 4.8 和 Qwen3.6-27B 都是 AI 领域的模型。以下是基于 traeai 收录的真实报道数据的全面对比。
模型
也叫:Opus4.8
一个模型,在Next.js Evals中被GLM 5.2超越。
20 篇相关报道
模型
也叫:Qwen3.6
被 Georgi Gerganov 评价为适合本地编码任务的模型。
4 篇相关报道
20
Opus 4.8 相关
0
共同提及
4
Qwen3.6-27B 相关
基于 traeai 收录材料自动更新
Opus 4.8 与 Qwen3.6-27B 的差异,最好从真实材料覆盖、共同语境和高频标签一起判断。traeai 会根据已收录内容持续更新这组对比。
GLM-5.2 是 Z.AI 推出的最新模型,支持 1M 上下文长度,显著提升长周期任务处理能力,并在多个基准测试中表现优异。
入选理由:GLM-5.2 支持 1M 上下文长度,显著提升长周期任务处理能力。
开源模型在性能和成本上显著优于闭源模型,成为AI领域的优选。
入选理由:GLM 5.2 比 Opus 4.8 快且更高效,成本低 6 倍以上。
Claude Fable 5 在多项基准测试中表现优异,但其高昂成本和部分任务表现不佳可能影响实际应用。
入选理由:Fable 5 在 SWBench Pro 基准测试中达到 80%,显著优于 Opus 4.8、GPT-4.5 和 Gemini 3.1 Pro。
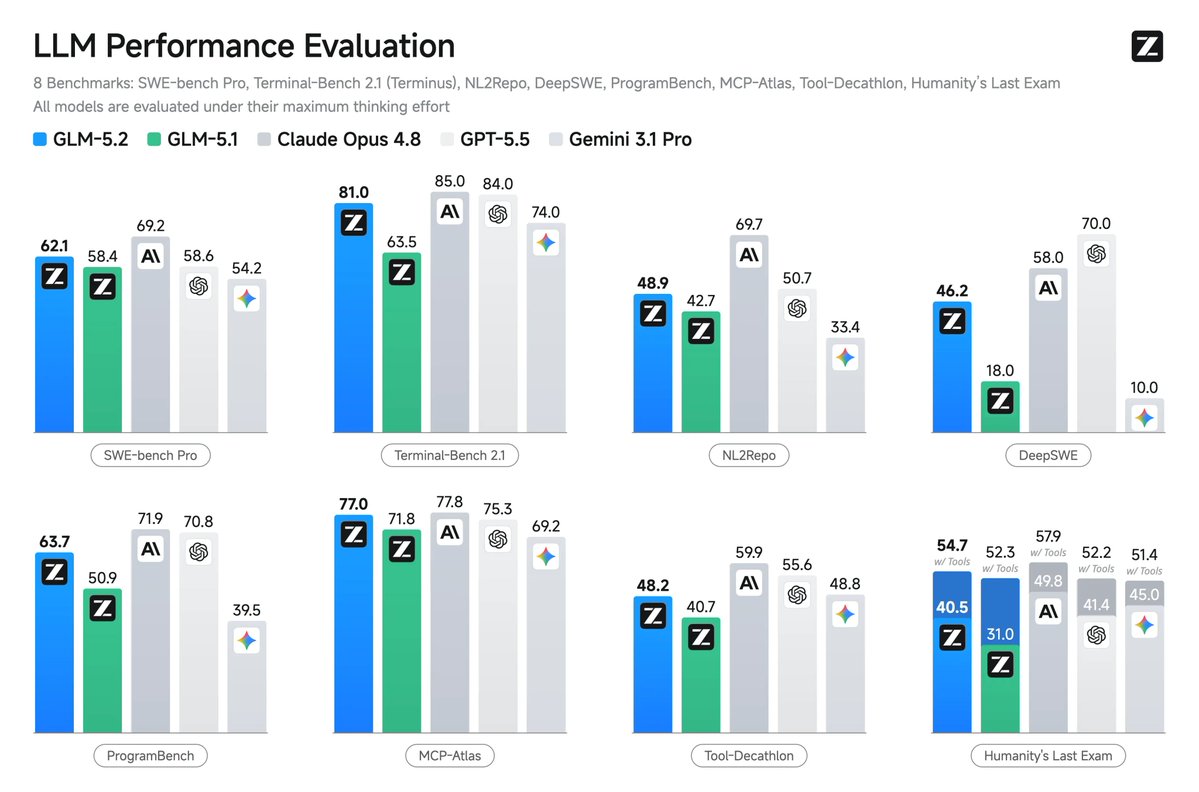
Z AI 发布 GLM-5.2,支持 1M token 上下文窗口,性能超越 GPT-5.5 和 Opus 4.8。
入选理由:GLM-5.2 在长程编程任务中得分为 74.4,优于 GPT-5.5 的 72.6。
GLM 5.2 在 SWE 领域表现强劲,排名第三,仅次于 Fable 5 和 Opus 4.8,且优于 GPT-5.5。
入选理由:GLM 5.2 在 FrontierSWE 排名第三,仅落后于 Fable 5 和 Opus 4.8。
Anthropic 推出 Claude Fable 5,这是其最强大的模型,具备安全机制,适用于广泛场景。
入选理由:Claude Fable 5 是 Mythos 级模型,具备高级安全机制。
OpenRouter Fusion API通过模型融合技术实现接近Fable 5的性能,成本仅为一半。
入选理由:OpenRouter Fusion API使用多模型融合技术,性能接近Fable 5但成本降低50%。
组合多个低价模型可达到接近 Claude Fable 5 的性能,同时成本降低一半。
入选理由:Gemini 3 Flash、Kimi K2.6 和 DeepSeek V4 Pro 组合性能接近 Claude Fable 5。
Local LLM agents require infrastructure to overcome slow inference and context overflow, solved via vLLM optimization and structured world state — reducing per-call latency from 15s to under 2s and enabling reproducible scientific workflows.
入选理由:使用vLLM优化推理性能,单次调用耗时从15秒降至2秒内
With MTP support, llama.cpp improves local model inference speed by 78%, boosting Qwen3.6-27B from 25 to 45 tokens/sec on A10G.
入选理由:MTP 支持使 llama.cpp 推理速度提升 78%
A developer uses the locally running large model Qwen3.6-27B to convert natural language into Shell commands, improving operational efficiency.
入选理由:使用Qwen3.6-27B大模型实现在本地将自然语言转为Shell命令。
Georgi Gerganov 表示 Qwen3.6-27B 是一个适合本地编码任务的模型,但使用频率受限于其工作负担。
入选理由:Qwen3.6-27B 被认为是适合本地编码任务的模型。