如何在llama.cpp中运行MTP(多token预测)
Julien Chaumond(@julien_c)255 字 (约 2 分钟)
75
MTP是llama.cpp内置的投机解码新特性,可将大多数用例的token生成速度提升约2倍,通过Dense 27B模型可达~30 tok/sec,MoE模型可达~100 tok/sec。
入选理由:MTP是内置于模型本身的投机解码新特性,可将token生成速度提升约2倍
精选推文#llama.cpp#MTP#投机解码#Qwen#大模型推理优化英文
概念
也叫:投机解码
通过预测多个token来加速LLM推理的技术。
最近变化
2026-05-19 · MTP是内置于模型本身的投机解码新特性,可将token生成速度提升约2倍
speculative decoding 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
已收录 2 篇与「speculative decoding」相关的 AI 资讯和分析。
MTP是llama.cpp内置的投机解码新特性,可将大多数用例的token生成速度提升约2倍,通过Dense 27B模型可达~30 tok/sec,MoE模型可达~100 tok/sec。
入选理由:MTP是内置于模型本身的投机解码新特性,可将token生成速度提升约2倍
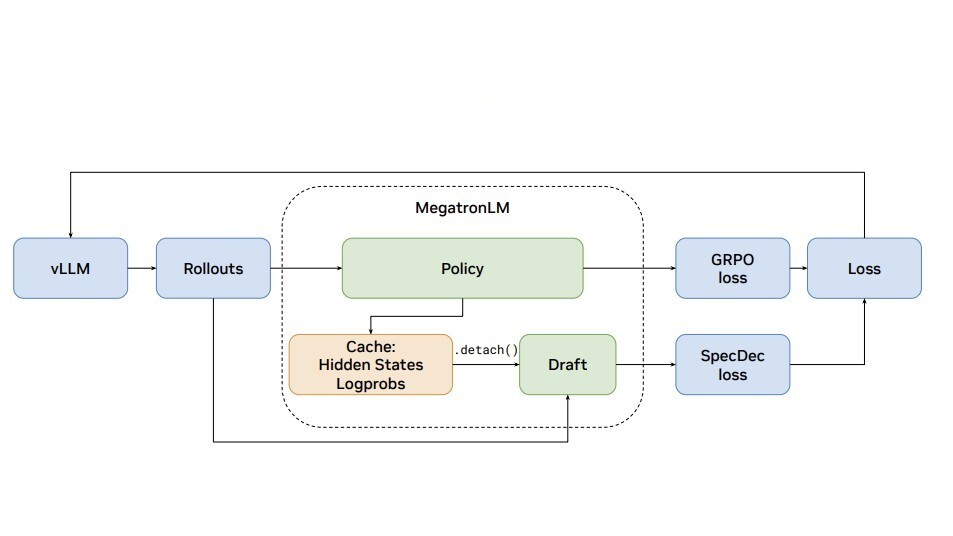
NVIDIA 研究提出将 speculative decoding 引入 NeMo-RL + vLLM 架构,实现 RL 后训练 rollout 阶段无损加速:8B 模型吞吐提升 1.8 倍,235B 模型端到端预计提速 2.5 倍。
入选理由:RLHF/RLAIF 后训练的 rollout 阶段已成为性能瓶颈
与「speculative decoding」经常一起出现的 AI 术语。
💡 想追踪「speculative decoding」的长期趋势?去 实体雷达 · speculative decoding 查看详细分析和跨材料问答。