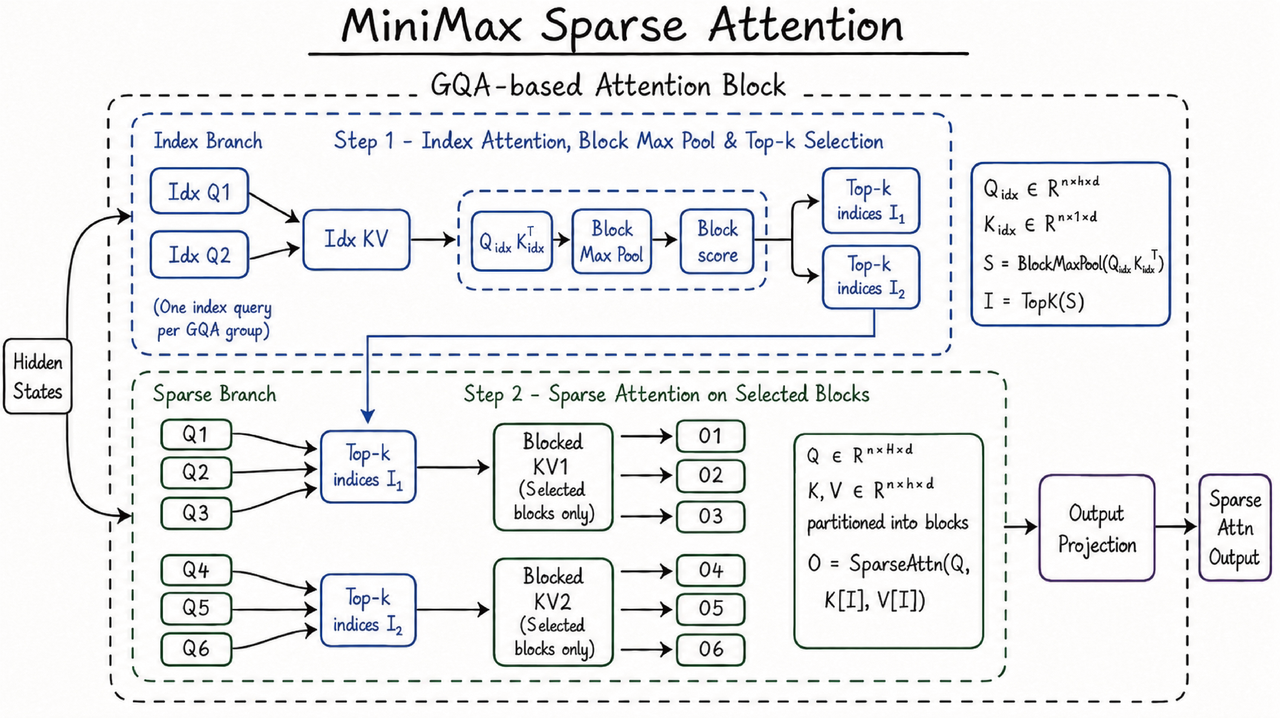
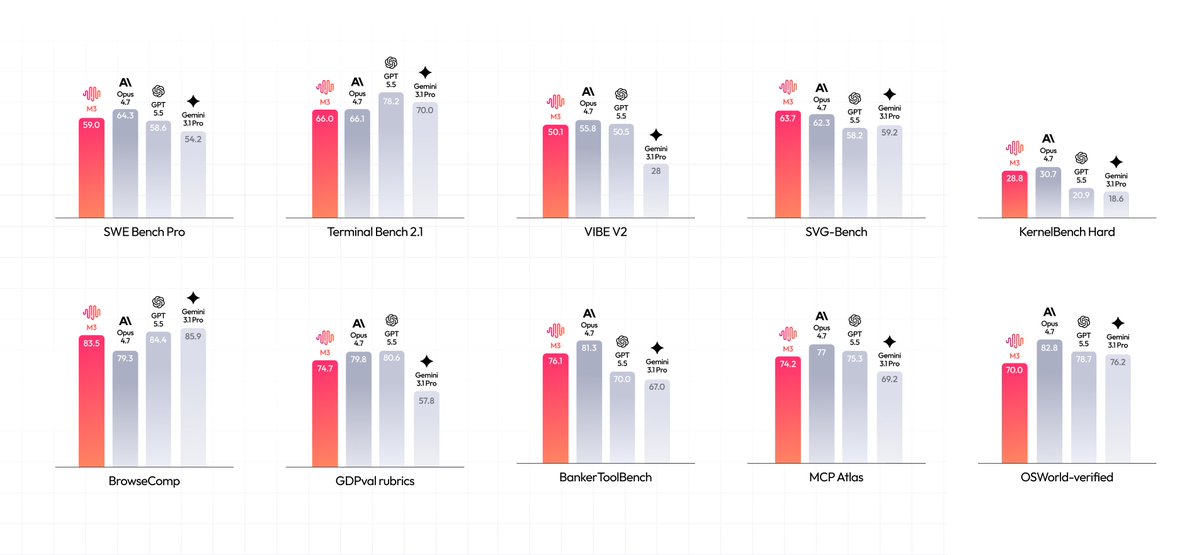
MiniMax M3 has landed in the Arena and has moved the Pareto frontier!
lmarena.ai(@lmarena_ai)175 字 (约 1 分钟)
87
MiniMax M3 has debuted in Code Arena, ranking #7 in the frontend track with a score of 1,531, tying with GLM-5.1. It advances the Pareto frontier in its price class at $0.60/ $2.40 per Mtoken.
入选理由:Code Arena 前端排名第7,得分1531,与GLM-5.1并列。
FeaturedTweet#MiniMax#Code Arena#GLM-5.1#Pareto frontier#Open-Weights英文