Fable 5自带反蒸馏机制!检测到就降智,误触率高到离谱
量子位2636 字 (约 11 分钟)
85
Fable 5模型内置反蒸馏机制,检测到潜在训练行为时会自动降智,误触率远超官方宣称的5%。
入选理由:Fable 5的反蒸馏机制会自动降低回答质量,且不通知用户。
FeaturedArticle#Fable 5#Anthropic#AI模型#安全机制中文
模型对比
Fable 5 和 MiniMax M3 都是 AI 领域的模型。以下是基于 traeai 收录的真实报道数据的全面对比。
模型
也叫:Mythos
Anthropic推出的新型AI模型,原名Mythos。
20 篇相关报道
模型
也叫:M3
多模态大模型,支持长程上下文与多模态任务。
10 篇相关报道
20
Fable 5 相关
0
共同提及
10
MiniMax M3 相关
基于 traeai 收录材料自动更新
Fable 5 与 MiniMax M3 的差异,最好从真实材料覆盖、共同语境和高频标签一起判断。traeai 会根据已收录内容持续更新这组对比。
Fable 5模型内置反蒸馏机制,检测到潜在训练行为时会自动降智,误触率远超官方宣称的5%。
入选理由:Fable 5的反蒸馏机制会自动降低回答质量,且不通知用户。
模型路由技术能显著降低使用成本,同时保持高质量输出,Prism 是实现这一目标的关键工具。
入选理由:Prism 路由器可降低任务成本达 30%。
Anthropic 推出的 Fable 5 模型在代码迁移、游戏通关和药物设计方面表现出色,且成本低于前代模型。
入选理由:Fable 5 在一天内完成了 Stripe 5000 万行 Ruby 代码的迁移,原本需要团队两个月。
Claude Mythos 5 是目前全球性能最强的 AI 模型,但普通用户将使用受限版本 Fable 5。
入选理由:Claude Mythos 5 在多个领域表现优于 OpenAI 的模型。
Anthropic 发布的 Mythos 级模型 Fable 5 在性能上表现强劲,但因 ZDR 和 RSI 抑制政策引发争议。
入选理由:Fable 5 的规模是 Opus 的两倍,性能在 FrontierCode Diamond 上提升了 16.9%。
LlamaParse 推出细粒度文档解析功能,支持精确到每个单词的可视化引用,提升 AI 决策审计能力。
入选理由:LlamaParse 新增细粒度文档解析功能,支持精确到每个单词的可视化引用。
Anthropic发布名为Fable 5的新型AI模型,声称其性能超越其他模型,但信息密度低且缺乏技术细节。
入选理由:Fable 5被描述为性能超越其他模型,但缺乏具体技术细节。
Fable 5 提升了复杂软件工程工作的能力,适用于代码审查、PR编写和大型项目规划。
入选理由:Fable 5 在代码审查中能有效发现细微问题。
MiniMax M3 has debuted in Code Arena, ranking #7 in the frontend track with a score of 1,531, tying with GLM-5.1. It advances the Pareto frontier in its price class at $0.60/ $2.40 per Mtoken.
入选理由:Code Arena 前端排名第7,得分1531,与GLM-5.1并列。
Together AI optimized the deployment of MiniMax M3, achieving 81–125% throughput improvements through architectural and engineering innovations.
入选理由:MiniMax M3 supports 1M-token context and native multimodality, making it suitable for complex real-world tasks.
MiniMax-M3 has launched on OpenRouter — a frontier-class open-weight model supporting 1M-token context, agentic performance, and native multimodality (image & video), marking a major leap in long-context, autonomous-agent, and multi-modal AI capabilities.
入选理由:MiniMax-M3 支持1M-token上下文窗口,显著超越主流模型如GPT-4o的32K限制。
Real-world testing shows that MiniMax M3 outperforms M2.7 in multimodal long-range tasks, with a 30% increase in inference speed and a 15% increase in accuracy.
入选理由:MiniMax M3在多模态长文本生成任务中准确率较M2.7提升15%。
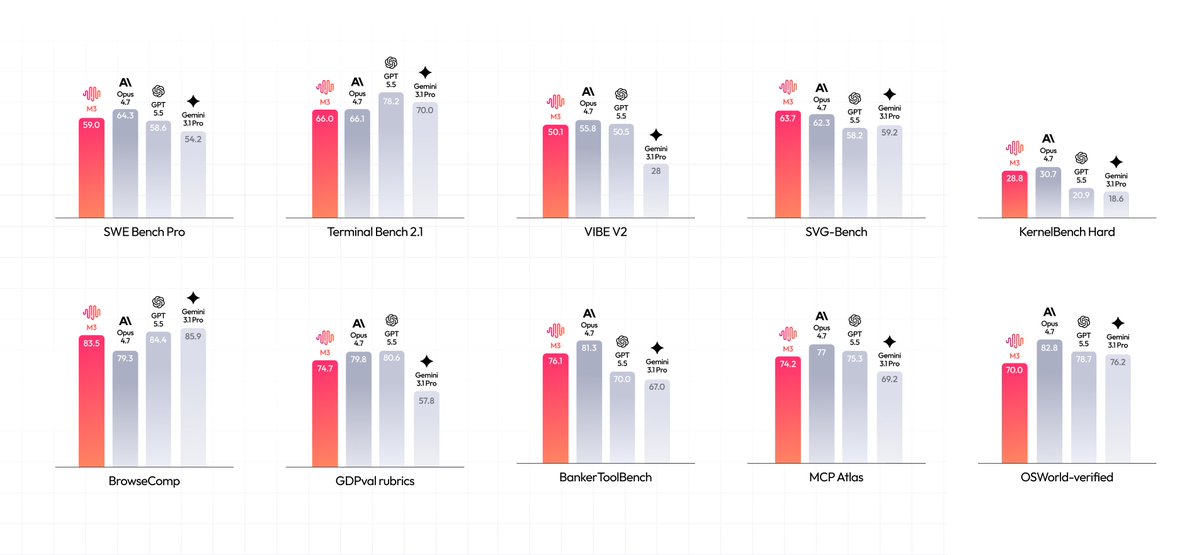
The open-weight model MiniMax M3 has reached performance comparable to GPT-5.5 and Opus 4.7, outperforming Gemini 3.1 Pro in coding tasks, and costs 10x less to use, with weights to be released on Hugging Face next week.
入选理由:MiniMax M3在SWE Bench Pro上与GPT-5.5性能相当
MiniMax M3 is the first open-weight model supporting text, vision, document, and code tasks, excelling in benchmarks like SWE-Bench Pro with 1M context length.
入选理由:MiniMax M3 在 SWE-Bench Pro 达到 59.0%,Terminal Bench 2.1 达 66.0%,是当前开源模型中编程能力最强之一。
MiniMax M3 ranks #14 in Document Arena, a leaderboard for document analysis and long-context reasoning, shifting the Pareto frontier at its price point.
入选理由:MiniMax M3 在 Document Arena 排名第 14,评估维度为文档分析与长文本推理能力。
NVIDIA AI祝贺MiniMax AI发布MiniMax M3,一个支持长上下文多模态推理的模型,可通过NVIDIA的GPU加速端点免费试用。
入选理由:MiniMax M3支持文本、图像和视频推理。


![[AINews] Anthropic Claude Fable 5 — Mythos but Safe, with Controversial Terms](https://substackcdn.com/image/fetch/$s_!TXW4!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F7af8f73c-7a20-4f7e-ac83-a05cbc892d8b_2318x1684.png)