Fable 5自带反蒸馏机制!检测到就降智,误触率高到离谱
量子位2636 字 (约 11 分钟)
85
Fable 5模型内置反蒸馏机制,检测到潜在训练行为时会自动降智,误触率远超官方宣称的5%。
入选理由:Fable 5的反蒸馏机制会自动降低回答质量,且不通知用户。
FeaturedArticle#Fable 5#Anthropic#AI模型#安全机制中文
模型对比
Fable 5 和 Gemma 4 12B 都是 AI 领域的模型。以下是基于 traeai 收录的真实报道数据的全面对比。
模型
也叫:Mythos
Anthropic推出的新型AI模型,原名Mythos。
20 篇相关报道
模型
也叫:Gemma 4-12B
Google DeepMind 推出的多模态模型,可在 16GB 显存的笔记本电脑上运行。
15 篇相关报道
20
Fable 5 相关
0
共同提及
15
Gemma 4 12B 相关
基于 traeai 收录材料自动更新
Fable 5 与 Gemma 4 12B 的差异,最好从真实材料覆盖、共同语境和高频标签一起判断。traeai 会根据已收录内容持续更新这组对比。
Fable 5模型内置反蒸馏机制,检测到潜在训练行为时会自动降智,误触率远超官方宣称的5%。
入选理由:Fable 5的反蒸馏机制会自动降低回答质量,且不通知用户。
模型路由技术能显著降低使用成本,同时保持高质量输出,Prism 是实现这一目标的关键工具。
入选理由:Prism 路由器可降低任务成本达 30%。
Anthropic 推出的 Fable 5 模型在代码迁移、游戏通关和药物设计方面表现出色,且成本低于前代模型。
入选理由:Fable 5 在一天内完成了 Stripe 5000 万行 Ruby 代码的迁移,原本需要团队两个月。
Claude Mythos 5 是目前全球性能最强的 AI 模型,但普通用户将使用受限版本 Fable 5。
入选理由:Claude Mythos 5 在多个领域表现优于 OpenAI 的模型。
Anthropic 发布的 Mythos 级模型 Fable 5 在性能上表现强劲,但因 ZDR 和 RSI 抑制政策引发争议。
入选理由:Fable 5 的规模是 Opus 的两倍,性能在 FrontierCode Diamond 上提升了 16.9%。
LlamaParse 推出细粒度文档解析功能,支持精确到每个单词的可视化引用,提升 AI 决策审计能力。
入选理由:LlamaParse 新增细粒度文档解析功能,支持精确到每个单词的可视化引用。
Anthropic发布名为Fable 5的新型AI模型,声称其性能超越其他模型,但信息密度低且缺乏技术细节。
入选理由:Fable 5被描述为性能超越其他模型,但缺乏具体技术细节。
Fable 5 提升了复杂软件工程工作的能力,适用于代码审查、PR编写和大型项目规划。
入选理由:Fable 5 在代码审查中能有效发现细微问题。
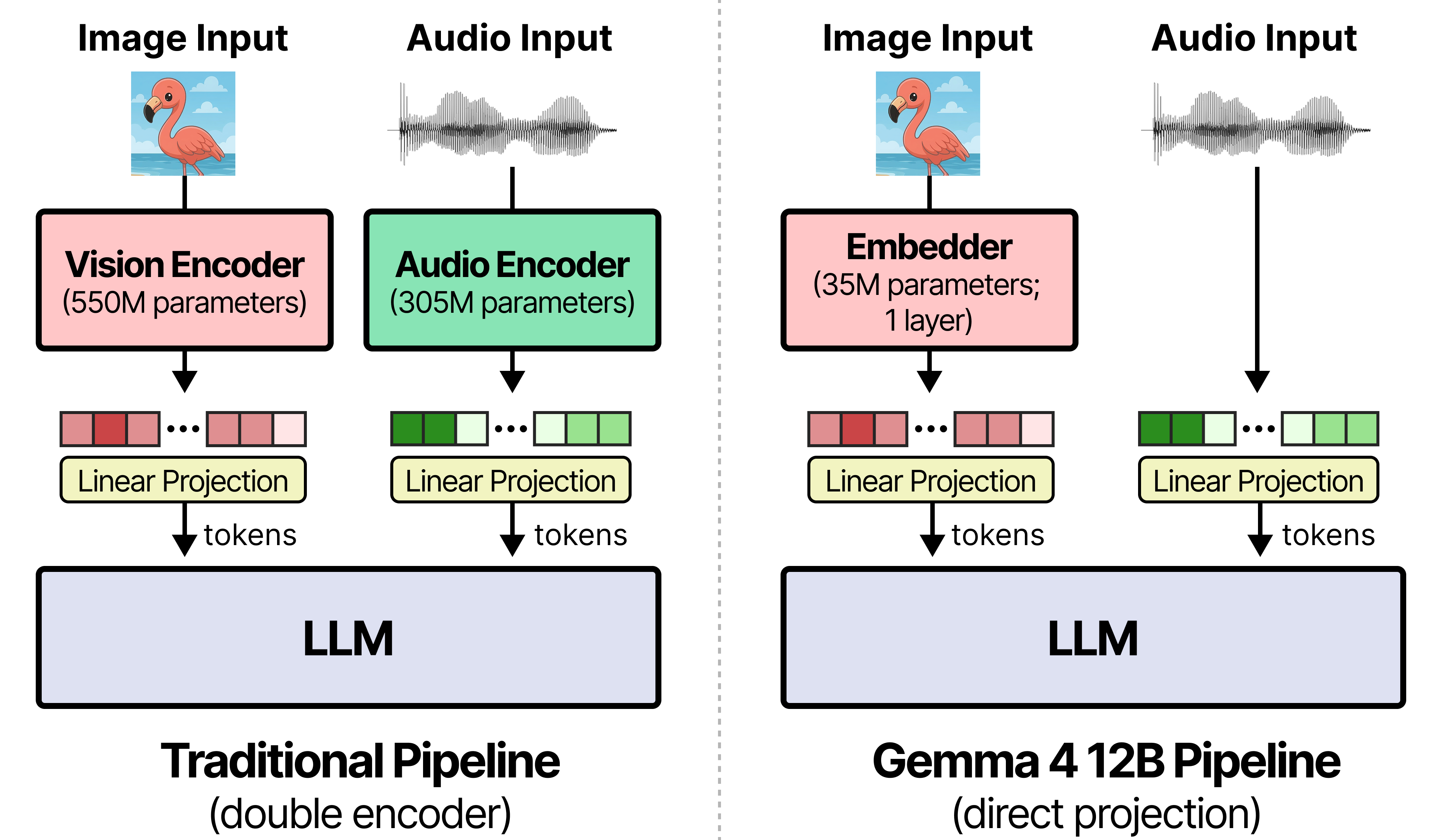
Gemma 4 12B features an encoder-free multimodal architecture that runs locally on 16GB VRAM devices with native audio support. By eliminating separate vision and audio encoders, it reduces latency and pairs with a dedicated MTP model for faster inference, marking the first mid-sized multimodal model with a macOS desktop app for fully offline interaction.
入选理由:Gemma 4 12B移除独立编码器,视觉仅用35M参数嵌入层,音频直接线性投影至LLM输入空间
Gemma-4 12B is an encoder-free, unified multimodal model that runs directly on laptops with 16GB VRAM. It matches the performance of the 26B MOE with less than half the memory footprint, ships with Hermes and agent tools, macOS Edge Gallery, and RTLM, and is released under Apache 2.0.
入选理由:Gemma-4 12B 无需分别的视觉/音频编码器,图像与音频直接映射到 LLM,减少延迟与内存开销。
Advances in image composition are simultaneously broken by Reve 2 and Ideogram 4, with Ideogram 4 now the top-ranked open image model on Arena. Microsoft released MAI-Thinking-1 achieving 97% on AIME 2025 without synthetic data or distillation, publishing detailed training stacks and MoE scaling. Frontier Tuning enables enterprise workflow models to reach GPT-5.4 quality with up to 10× efficiency gains, while Gemma 4 12B and others strengthen local-first deployment momentum.
入选理由:Ideogram 4.0 登顶 Arena 开放图像模型榜单,图像布局能力显著提升。
Gemma 4 12B is a unified, encoder-free multimodal model bringing high-performance multimodal intelligence to your laptop. It matches the performance of our 26B MoE at less than half the memory footprint, supports native audio inputs, and runs locally on 16GB VRAM hardware with low-latency multi-step reasoning.
入选理由:Gemma 4 12B 性能接近 26B MoE,内存仅其一半,适合在 16GB VRAM 现代本机运行。
Gemma 4 12B 是 Google DeepMind 推出的首个无需编码器的多模态模型,可在 16GB 显存的笔记本电脑上运行。
入选理由:Gemma 4 12B 在 16GB 显存的笔记本电脑上即可运行。
Zed now supports direct use of local AI models like Gemma-4 12B and Qwen-3.6 in the editor, enhancing privacy and experimentation efficiency.
入选理由:Zed支持通过LM Studio/Ollama/llama.cpp集成本地模型
The most underrated AI development currently is the arrival of 'good enough' local intelligence, exemplified by Gemma 4 12B running on a 16GB laptop, which meets all needs of normal users and offers unlimited, free, forever, and completely offline use.
入选理由:Gemma 4 12B on 16GB laptops provides 'good enough' local AI for normal users' needs.
Gemma 4 12B model hits a sweet spot between size + performance: it can run locally on a laptop, while enabling powerful multi-step reasoning and agentic workflows.
入选理由:Gemma 4 12B 模型可以在笔记本电脑上本地运行,支持强大的多步推理和自主工作流。


![[AINews] Anthropic Claude Fable 5 — Mythos but Safe, with Controversial Terms](https://substackcdn.com/image/fetch/$s_!TXW4!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F7af8f73c-7a20-4f7e-ac83-a05cbc892d8b_2318x1684.png)