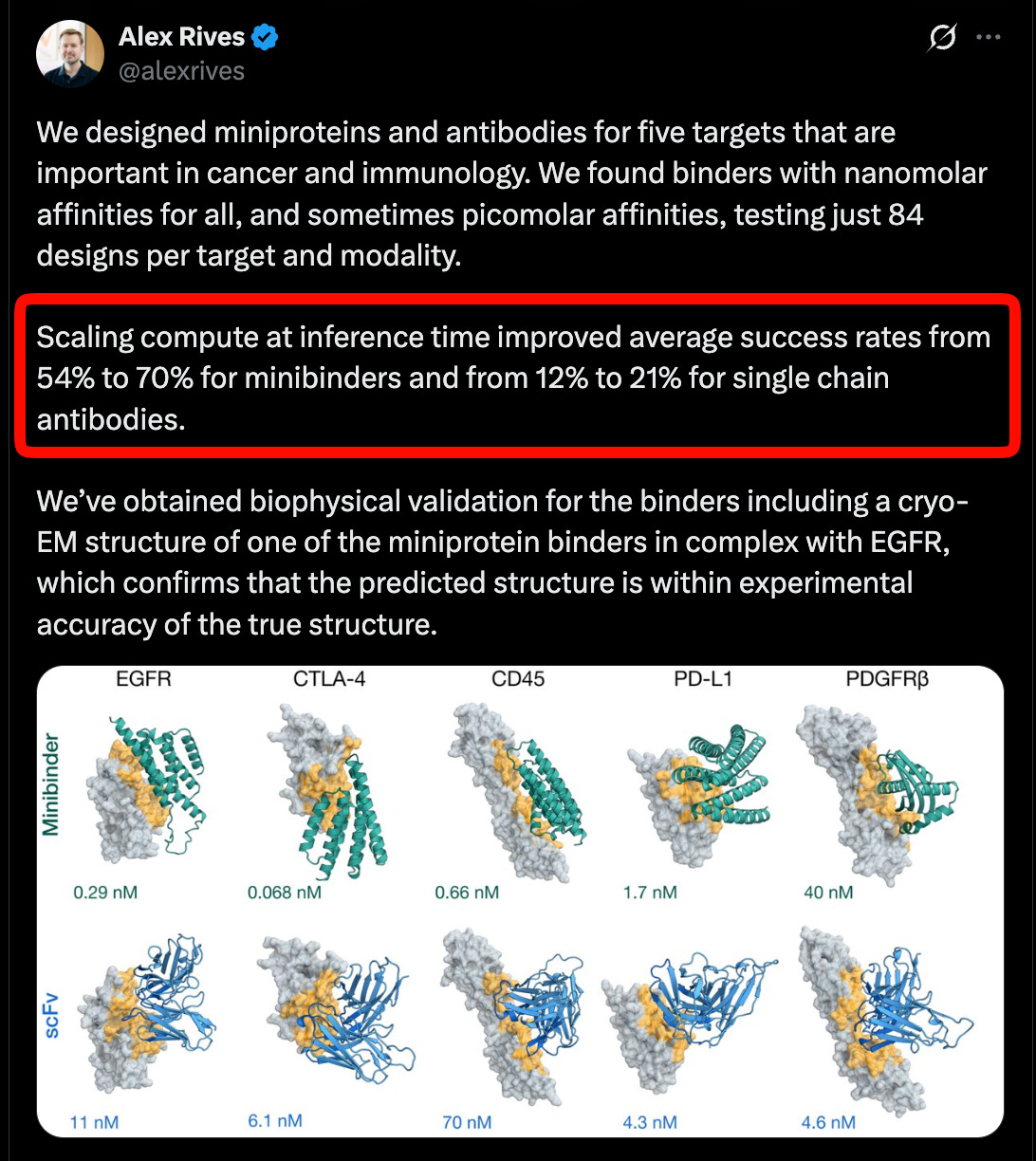
🆕Biohub’s Protein World Model: ESMC-6B, ESMFold2, 6.8B proteins, 1.1B structures, antibody design, ...
Latent.Space(@latentspacepod)224 字 (约 1 分钟)
85
Biohub的Protein World Model通过ESMC-6B和ESMFold2处理68亿蛋白质和11亿结构,展示了生物建模可能像语言建模一样扩展,强调稀疏自编码器揭示模型内部生物学。
入选理由:Biohub的ESMC-6B和ESMFold2处理68亿蛋白质和11亿结构。
FeaturedTweet#Biohub#Protein Modeling#ESMFold2#ESMC-6B#Virtual Biology中文