Claude Fable 5 - Full 319 page Breakdown
AI Explained7804 字 (约 32 分钟)
85
Claude Fable 5 显著提升了 AI 能力,但存在使用限制和内容过滤机制。
入选理由:Claude Fable 5 在性能和功能上都有显著提升。
FeaturedVideo#AI#Claude#Anthropic#模型发布英文
产品对比
Claude Fable 5 和 MiniMax M3 都是 AI 领域的产品。以下是基于 traeai 收录的真实报道数据的全面对比。
产品
也叫:Fable 5
Anthropic公司推出的AI模型,曾因性能调整引发争议。
20 篇相关报道
模型
也叫:M3
多模态大模型,支持长程上下文与多模态任务。
10 篇相关报道
20
Claude Fable 5 相关
0
共同提及
10
MiniMax M3 相关
基于 traeai 收录材料自动更新
Claude Fable 5 与 MiniMax M3 的差异,最好从真实材料覆盖、共同语境和高频标签一起判断。traeai 会根据已收录内容持续更新这组对比。
Claude Fable 5 显著提升了 AI 能力,但存在使用限制和内容过滤机制。
入选理由:Claude Fable 5 在性能和功能上都有显著提升。
Anthropic 推出 Claude Fable 5,该模型在安全性和能力上实现重大突破,标志着与模型协作的新阶段。
入选理由:Claude Fable 5 是 Anthropic 首个 Mythos-class 模型,适用于一般用途。
Claude Fable 5在低档位下表现优于Opus 4.8,且在复杂任务中更省成本。
入选理由:Fable 5低档位下表现优于Opus 4.8
Anthropic 推出 Claude Fable 5 模型,性能显著提升但价格高昂,引发业界两极评价。
入选理由:Claude Fable 5 是 Anthropic 首个安全可用的 Mythos 级模型,性能优于 Opus。
Claude Fable 5 是 Claude Mythos 5 的受限版本,价格合理但存在安全限制。
入选理由:Claude Fable 5 和 Claude Mythos 5 是同一模型,但 Fable 5 有更多安全限制。
Google Cloud 现已提供 Claude Fable 5 模型,但文章信息密度较低,缺乏深度技术细节。
入选理由:Google Cloud 现已提供 Claude Fable 5 模型。
GitHub 宣布 Claude Fable 5 模型在 GitHub Copilot 中需要数据保留以运行 Anthropic 的安全分类器。
入选理由:Claude Fable 5 需要数据保留来运行安全分类器。
GitHub 宣布 AnthropicAI 的 Mythos 模型系列首推 Claude Fable 5,已集成到 GitHub Copilot 中,用于长周期、自主编码和知识工作。
入选理由:Claude Fable 5 是 AnthropicAI 的 Mythos 模型系列的首个版本。
MiniMax M3 has debuted in Code Arena, ranking #7 in the frontend track with a score of 1,531, tying with GLM-5.1. It advances the Pareto frontier in its price class at $0.60/ $2.40 per Mtoken.
入选理由:Code Arena 前端排名第7,得分1531,与GLM-5.1并列。
Together AI optimized the deployment of MiniMax M3, achieving 81–125% throughput improvements through architectural and engineering innovations.
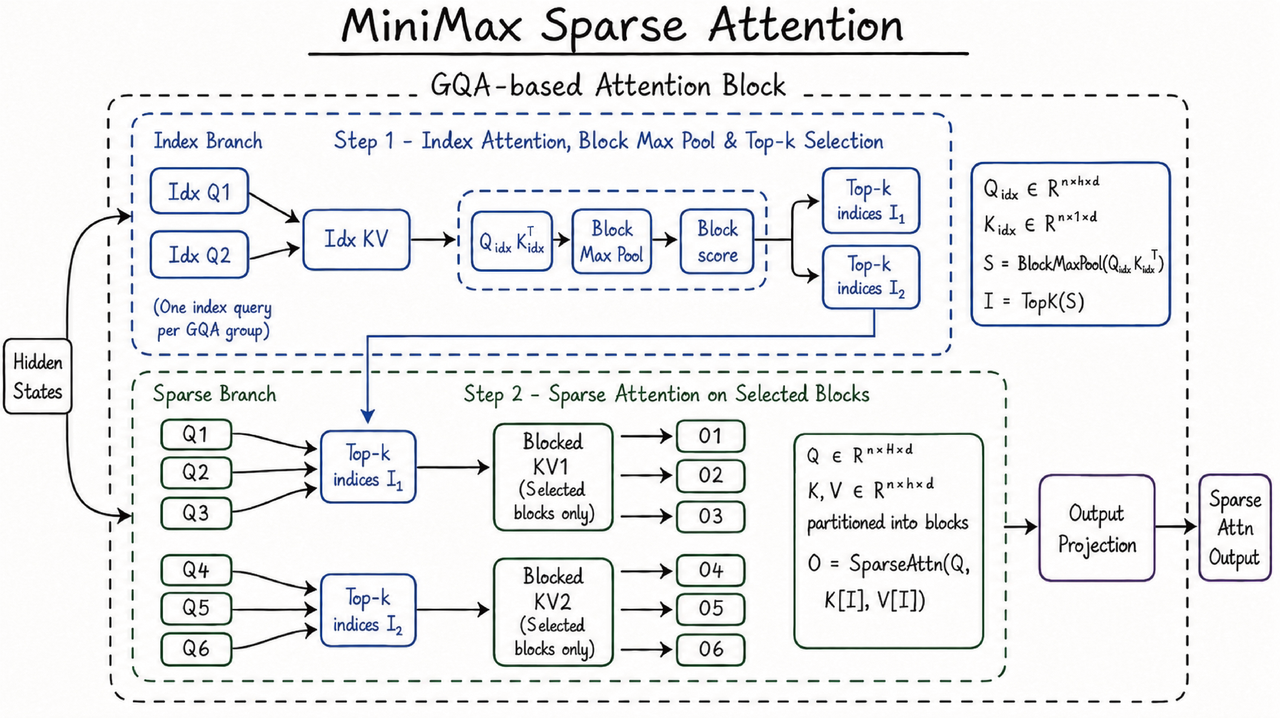
入选理由:MiniMax M3 supports 1M-token context and native multimodality, making it suitable for complex real-world tasks.
MiniMax-M3 has launched on OpenRouter — a frontier-class open-weight model supporting 1M-token context, agentic performance, and native multimodality (image & video), marking a major leap in long-context, autonomous-agent, and multi-modal AI capabilities.
入选理由:MiniMax-M3 支持1M-token上下文窗口,显著超越主流模型如GPT-4o的32K限制。
Real-world testing shows that MiniMax M3 outperforms M2.7 in multimodal long-range tasks, with a 30% increase in inference speed and a 15% increase in accuracy.
入选理由:MiniMax M3在多模态长文本生成任务中准确率较M2.7提升15%。
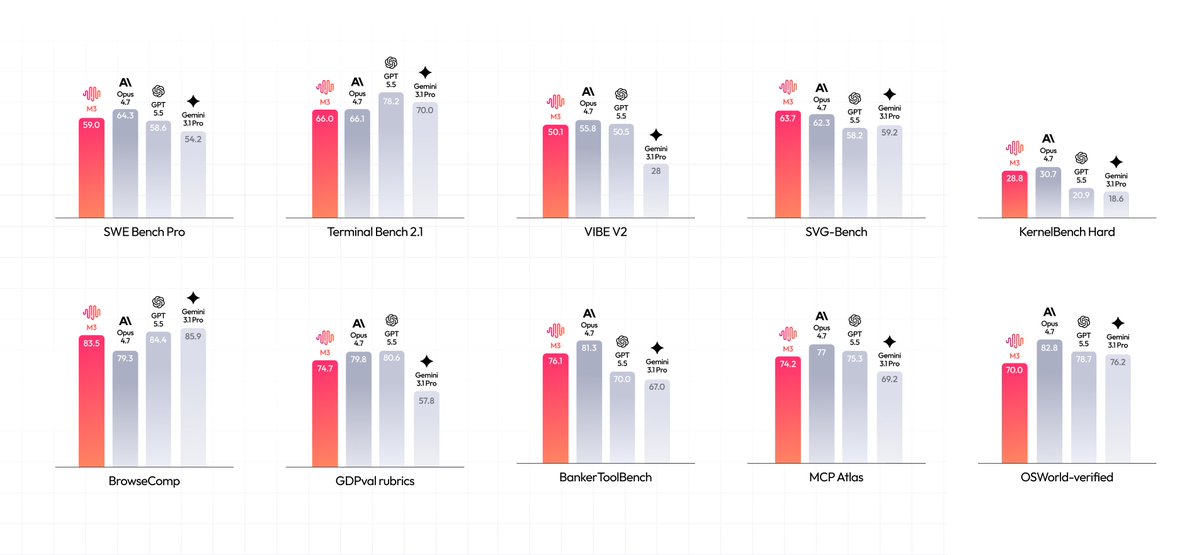
The open-weight model MiniMax M3 has reached performance comparable to GPT-5.5 and Opus 4.7, outperforming Gemini 3.1 Pro in coding tasks, and costs 10x less to use, with weights to be released on Hugging Face next week.
入选理由:MiniMax M3在SWE Bench Pro上与GPT-5.5性能相当
MiniMax M3 is the first open-weight model supporting text, vision, document, and code tasks, excelling in benchmarks like SWE-Bench Pro with 1M context length.
入选理由:MiniMax M3 在 SWE-Bench Pro 达到 59.0%,Terminal Bench 2.1 达 66.0%,是当前开源模型中编程能力最强之一。
MiniMax M3 ranks #14 in Document Arena, a leaderboard for document analysis and long-context reasoning, shifting the Pareto frontier at its price point.
入选理由:MiniMax M3 在 Document Arena 排名第 14,评估维度为文档分析与长文本推理能力。
NVIDIA AI祝贺MiniMax AI发布MiniMax M3,一个支持长上下文多模态推理的模型,可通过NVIDIA的GPU加速端点免费试用。
入选理由:MiniMax M3支持文本、图像和视频推理。