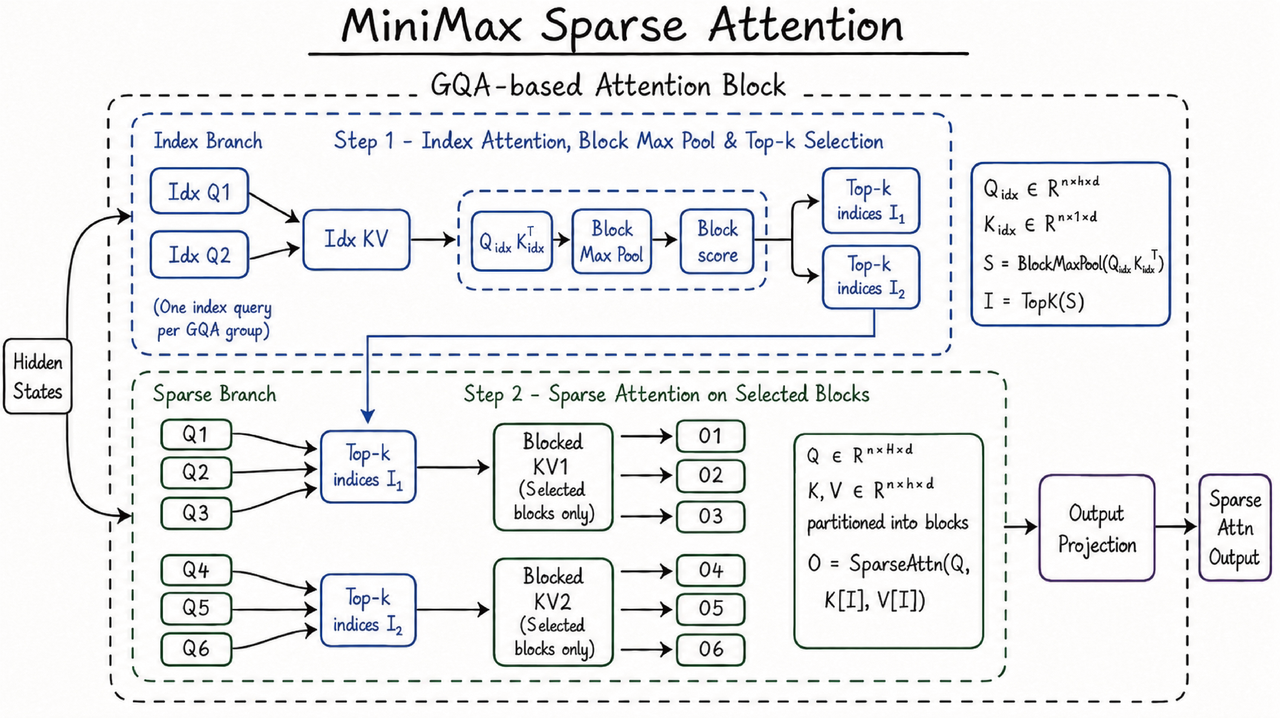
MiniMax M3 登场 Arena,推动价格带帕累托前沿
lmarena.ai(@lmarena_ai)175 字 (约 1 分钟)
87
MiniMax M3 登场 Code Arena 前端第7,得分1531,与 GLM-5.1 并列领先,价格带 Pareto 前沿达 $0.60/ $2.40 每Mtoken。
入选理由:Code Arena 前端排名第7,得分1531,与GLM-5.1并列。
精选推文#MiniMax#Code Arena#GLM-5.1#帕累托前沿#开源权重英文
模型对比
MiniMax M3 和 Qwen 3.7 Max 都是 AI 领域的模型。以下是基于 traeai 收录的真实报道数据的全面对比。
模型
也叫:M3
多模态大模型,支持长程上下文与多模态任务。
9 篇相关报道
模型
也叫:通义千问
阿里巴巴云推出的一款强大代码代理模型。
5 篇相关报道
9
MiniMax M3 相关
0
共同提及
5
Qwen 3.7 Max 相关
基于 traeai 收录材料自动更新
MiniMax M3 与 Qwen 3.7 Max 的差异,最好从真实材料覆盖、共同语境和高频标签一起判断。traeai 会根据已收录内容持续更新这组对比。
MiniMax M3 登场 Code Arena 前端第7,得分1531,与 GLM-5.1 并列领先,价格带 Pareto 前沿达 $0.60/ $2.40 每Mtoken。
入选理由:Code Arena 前端排名第7,得分1531,与GLM-5.1并列。
Together AI优化了MiniMax M3模型的部署,通过架构和工程创新实现81–125%吞吐量提升。
入选理由:MiniMax M3 supports 1M-token context and native multimodality, making it suitable for complex real-world tasks.
MiniMax-M3 已上线 OpenRouter,是一款支持100万token上下文、前沿编码与代理性能、原生多模态(图像/视频)的开源模型,标志着大模型能力向长文本、多模态和自主执行方向的重要突破。
入选理由:MiniMax-M3 支持1M-token上下文窗口,显著超越主流模型如GPT-4o的32K限制。
实测显示,MiniMax M3在多模态长程任务上显著优于M2.7,推理速度提升约30%,准确率提升约15%。
入选理由:MiniMax M3在多模态长文本生成任务中准确率较M2.7提升15%。
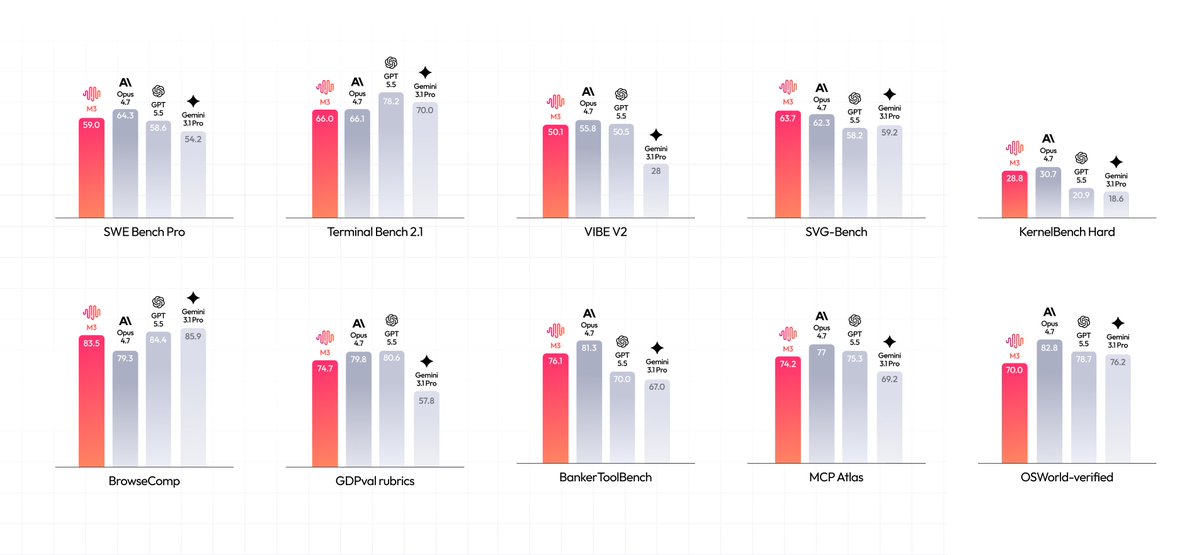
开源模型MiniMax M3已达到与GPT-5.5和Opus 4.7相当的性能,尤其在编码任务上优于Gemini 3.1 Pro,且成本仅为它们的1/10,其权重将于下周在Hugging Face开放。
入选理由:MiniMax M3在SWE Bench Pro上与GPT-5.5性能相当
MiniMax M3 是首个开源权重模型,同时支持文本、视觉、文档和代码任务,在 SWE-Bench Pro 等基准测试中表现优异,上下文长度达 1M tokens。
入选理由:MiniMax M3 在 SWE-Bench Pro 达到 59.0%,Terminal Bench 2.1 达 66.0%,是当前开源模型中编程能力最强之一。
MiniMax M3 在文档分析与长文本推理的 Document Arena 中排名第 14,其性价比显著提升该领域的帕累托前沿。
入选理由:MiniMax M3 在 Document Arena 排名第 14,评估维度为文档分析与长文本推理能力。
MiniMax M3在BU Bench测试中性能提升26%,达到Claude 4.6-sonnet和Gemini 3.5 Flash水平,但测试细节未公开。
入选理由:MiniMax M3在BU Bench上实现26%的性能提升,具体测试方法未详述。
Qwen 3.7 Max 是一个强大的代码代理模型,适用于各种编程场景,具有出色的性能和自适应能力。
入选理由:Qwen 3.7 Max 在基准测试中表现最佳,能够持续运行超过 35 小时。
阿里推出Qwen-3.7-Max模型,在成本和性能上显著优于GPT-5.5和Opus 4.7,支持与Hermes Agent或OpenCode集成。
入选理由:Qwen-3.7-Max输出价格比Opus 4.7便宜3.3倍,比GPT-5.5便宜4倍。
阿里通义千问Qwen 3.7 Max模型现已集成到Vercel AI Gateway,为开发者提供统一的AI模型接入端点。该模型专为代理场景设计,支持多模态推理能力。
入选理由:Qwen 3.7 Max模型已集成到Vercel AI Gateway平台
Qwen-3.7-max 在实际代理任务中超越了 GPT-5.5 和 Opus 4.7,且成本显著更低。
入选理由:Qwen-3.7-max 在自进化 Tetris 机器人任务中击败 GPT-5.5 和 Opus 4.7。
阿里通义千问官方账号转发了一条关于Qwen 3.7-max在Tetris机器人测试中表现优于Opus 4.7和GPT-5.5的消息,但缺乏具体的技术细节和验证信息。
入选理由:Qwen 3.7-max在Tetris自训练机器人测试中击败Opus 4.7和GPT-5.5