Claude Fable 5 - Full 319 page Breakdown
AI Explained7804 字 (约 32 分钟)
85
Claude Fable 5 显著提升了 AI 能力,但存在使用限制和内容过滤机制。
入选理由:Claude Fable 5 在性能和功能上都有显著提升。
精选视频#AI#Claude#Anthropic#模型发布英文
产品对比
Claude Fable 5 和 Gemma 4 12B 都是 AI 领域的产品。以下是基于 traeai 收录的真实报道数据的全面对比。
产品
也叫:Fable 5
Anthropic公司推出的AI模型,曾因性能调整引发争议。
20 篇相关报道
模型
也叫:Gemma 4-12B
Google DeepMind 推出的多模态模型,可在 16GB 显存的笔记本电脑上运行。
15 篇相关报道
20
Claude Fable 5 相关
0
共同提及
15
Gemma 4 12B 相关
基于 traeai 收录材料自动更新
Claude Fable 5 与 Gemma 4 12B 的差异,最好从真实材料覆盖、共同语境和高频标签一起判断。traeai 会根据已收录内容持续更新这组对比。
Claude Fable 5 显著提升了 AI 能力,但存在使用限制和内容过滤机制。
入选理由:Claude Fable 5 在性能和功能上都有显著提升。
Anthropic 推出 Claude Fable 5,该模型在安全性和能力上实现重大突破,标志着与模型协作的新阶段。
入选理由:Claude Fable 5 是 Anthropic 首个 Mythos-class 模型,适用于一般用途。
Claude Fable 5在低档位下表现优于Opus 4.8,且在复杂任务中更省成本。
入选理由:Fable 5低档位下表现优于Opus 4.8
Anthropic 推出 Claude Fable 5 模型,性能显著提升但价格高昂,引发业界两极评价。
入选理由:Claude Fable 5 是 Anthropic 首个安全可用的 Mythos 级模型,性能优于 Opus。
Claude Fable 5 是 Claude Mythos 5 的受限版本,价格合理但存在安全限制。
入选理由:Claude Fable 5 和 Claude Mythos 5 是同一模型,但 Fable 5 有更多安全限制。
Google Cloud 现已提供 Claude Fable 5 模型,但文章信息密度较低,缺乏深度技术细节。
入选理由:Google Cloud 现已提供 Claude Fable 5 模型。
GitHub 宣布 Claude Fable 5 模型在 GitHub Copilot 中需要数据保留以运行 Anthropic 的安全分类器。
入选理由:Claude Fable 5 需要数据保留来运行安全分类器。
GitHub 宣布 AnthropicAI 的 Mythos 模型系列首推 Claude Fable 5,已集成到 GitHub Copilot 中,用于长周期、自主编码和知识工作。
入选理由:Claude Fable 5 是 AnthropicAI 的 Mythos 模型系列的首个版本。
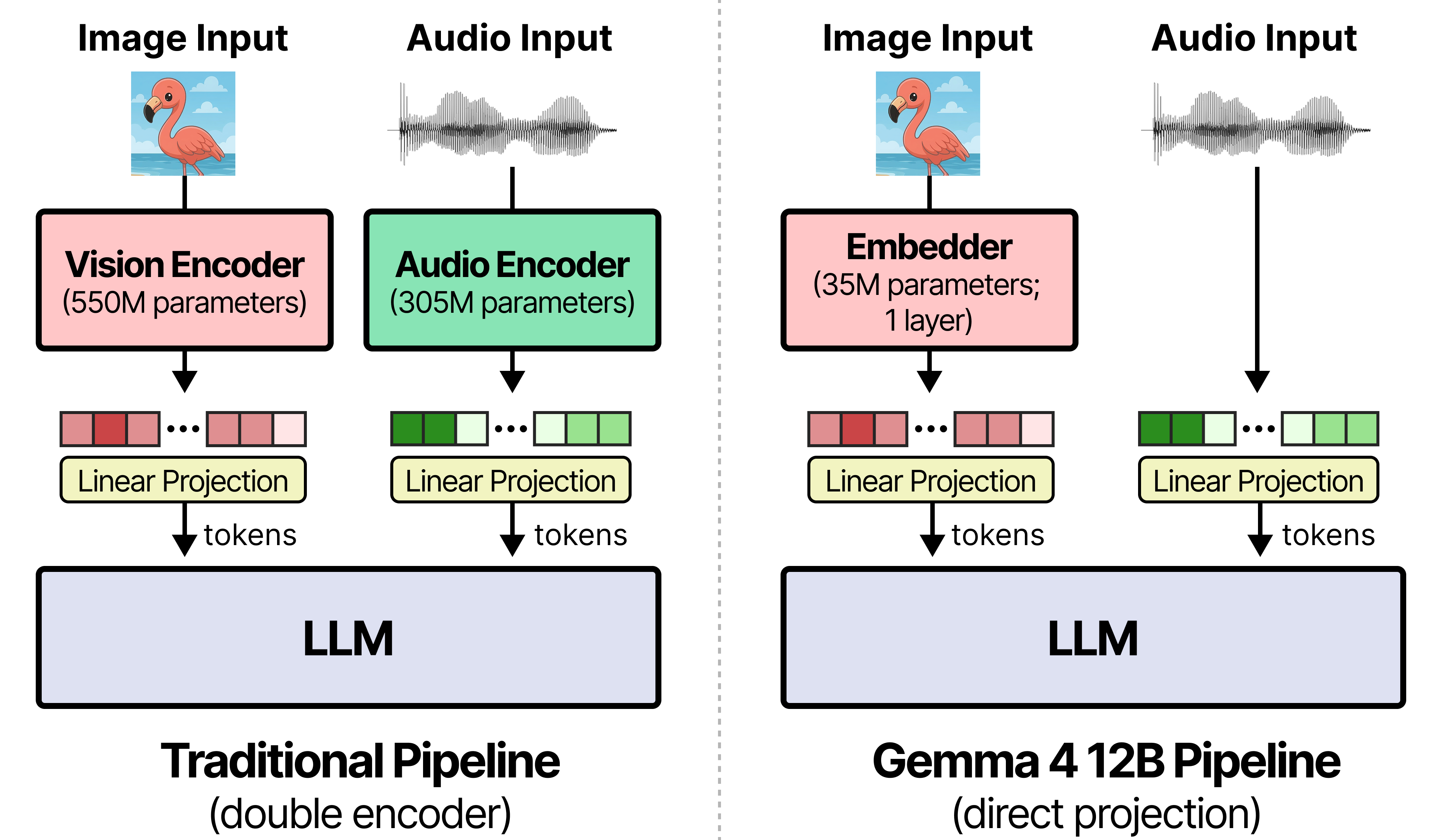
Gemma 4 12B采用无编码器多模态架构,可在16GB显存设备上本地运行并原生支持音频输入。该模型通过移除独立视觉与音频编码器显著降低延迟,配合专用MTP模型提升推理速度,是首个支持macOS桌面端全离线交互的中型多模态模型。
入选理由:Gemma 4 12B移除独立编码器,视觉仅用35M参数嵌入层,音频直接线性投影至LLM输入空间
Gemma-4 12B 采用统一无编码器架构,图像与音频直连 LLM,可在 16GB 设备本地运行;性能接近 26B MOE 且内存不足其半,配套 Hermes 等 Agent 工具与 macOS Edge Gallery,采用 Apache 2.0 开源许可。
入选理由:Gemma-4 12B 无需分别的视觉/音频编码器,图像与音频直接映射到 LLM,减少延迟与内存开销。
图像生成布局能力被 Reve 2 与 Ideogram 4 同步突破,后者登顶公开图像模型榜单;微软发布 MAI-Thinking-1,AIME 2025 97% 且无合成数据、无蒸馏,公开训练细节与 MoE 阶梯;开源侧 Gemma 4 12B 等多款模型升级,强化本地优先部署。
入选理由:Ideogram 4.0 登顶 Arena 开放图像模型榜单,图像布局能力显著提升。
Gemma 4 12B 是面向本机运行的统一、无编码器多模态模型,将视觉与音频直接接入 LLM,性能接近 26B MoE 但内存仅其一半,可在 16GB VRAM 紧凑设备上运行,支持离线语音处理与低延迟多步推理。
入选理由:Gemma 4 12B 性能接近 26B MoE,内存仅其一半,适合在 16GB VRAM 现代本机运行。
Gemma 4 12B 是 Google DeepMind 推出的首个无需编码器的多模态模型,可在 16GB 显存的笔记本电脑上运行。
入选理由:Gemma 4 12B 在 16GB 显存的笔记本电脑上即可运行。
Zed现在支持直接在编辑器中使用本地AI模型,如Gemma-4 12B和Qwen-3.6,提升隐私和实验效率。
入选理由:Zed支持通过LM Studio/Ollama/llama.cpp集成本地模型
当前AI领域最被低估的发展是「足够好」的本地智能已经到来,以Gemma 4 12B在16GB笔记本电脑上的运行为例,它覆盖了普通用户的所有需求,并且无限、永久免费、完全离线。
入选理由:Gemma 4 12B on 16GB laptops provides 'good enough' local AI for normal users' needs.
Gemma 4 12B 模型在大小和性能之间找到了一个甜蜜点,可以在笔记本电脑上本地运行,同时支持强大的多步推理和自主工作流。
入选理由:Gemma 4 12B 模型可以在笔记本电脑上本地运行,支持强大的多步推理和自主工作流。