英伟达掀桌,Windows 终于迎来真 AI PC
爱范儿3398 字 (约 14 分钟)
92
英伟达发布RTX Spark芯片,联合微软重新定义Windows PC为原生AI智能体平台,支持本地LLM、游戏与专业创作,开启个人计算新纪元。
入选理由:RTX Spark搭载Blackwell GPU+Grace CPU,FP4算力1 petaflop,内存128GB统一带宽600GB/s。
精选文章#英伟达#AI PC#Agent#Windows#RTX Spark中文
每日 AI 资讯雷达
2026-06-01 当日 traeai 收录 60 条 AI 技术与产品资讯,按评分排序,每条带 AI 摘要、要点与原文链接。
canonical: https://www.traeai.com/daily/2026-06-01
NVIDIA Cosmos 3 是首个开源物理AI全能模型,整合世界生成、物理推理与动作生成于单模型,支持机器人、自动驾驶等场景,基于MoT架构并提供Hugging Face集成。
Claude Opus 4.8 已接入 Microsoft Foundry,专为复杂编码、代理任务与企业文档分析设计,支持长会话上下文理解、多步骤工具调用与错误恢复,提升开发者与企业AI工作流效率。
Nick Nisi在WorkOS实践AI Agent工程,八个月未手写代码却交付稳定成果;删减95%技能后效率提升,核心是用机制替代信任、用验证代替假设,推动工程从‘写代码’转向‘管理Agent’。
英伟达发布RTX Spark芯片,联合微软重新定义Windows PC为原生AI智能体平台,支持本地LLM、游戏与专业创作,开启个人计算新纪元。
入选理由:RTX Spark搭载Blackwell GPU+Grace CPU,FP4算力1 petaflop,内存128GB统一带宽600GB/s。
NVIDIA Cosmos 3 是首个开源物理AI全能模型,整合世界生成、物理推理与动作生成于单模型,支持机器人、自动驾驶等场景,基于MoT架构并提供Hugging Face集成。
入选理由:Cosmos 3 是首个统一物理AI能力的开源模型,融合世界生成、物理推理与动作生成于单模型。
AI将重塑经济结构,但不会像互联网那样颠覆就业;模型公司价值被高估,应用层和分发才是未来赢家;普通人应主动使用AI而非逃避,平台迁移需时间,AGI仍不确定。
入选理由:AI重要性等同互联网,但多数形态尚未定型(类比1997年)
LVMH通过杠杆收购与品牌战略构建全球奢侈品帝国,Bernard Arnault以6000万美元撬动Boussac并整合LV与Moët Hennessy,实现二十年市值增长二十倍;其成功源于稀缺性管理、垂直控制与文化叙事重构,而非规模扩张。
入选理由:Bernard Arnault用1500万美元自有资本撬动6000万美元收购Boussac,裁员9000人后扭亏为盈
Nick Nisi在WorkOS实践AI Agent工程,八个月未手写代码却交付稳定成果;删减95%技能后效率提升,核心是用机制替代信任、用验证代替假设,推动工程从‘写代码’转向‘管理Agent’。
入选理由:删掉95%自动生成技能后,Agent运行时间从68分钟降至6分钟,正确率从77%升至97%
NVIDIA发布Cosmos 3,首个整合视觉、语言、声音与动作的全能物理AI模型,采用Mixture-of-Transformer架构,在多个基准测试中登顶,支持开源定制与边缘部署。
入选理由:Cosmos 3 是首个融合语言/视频/声音/动作的Omni模型,基于Mixture-of-Transformer架构。
NVIDIA 推出 Cosmos 3,首个融合语言、视频、声音与动作的多模态统一模型,采用 Mixture of Transformer 架构,支持开源定制与边缘部署,已在多项物理AI基准测试中登顶。
入选理由:Cosmos 3 是首个整合语言/视频/声音/动作输入输出的 omni 模型,基于 Mixture of Transformer 架构。
Bonsai Image 4B 是首个可在 iPhone 上本地运行的 4B 参数图像生成模型,通过 1-bit 和三值量化技术将内存占用降低 6-8 倍,支持在手机端生成 512x512 图像仅需 9.4 秒。
入选理由:1-bit Bonsai Image 4B 将扩散 Transformer 内存从 7.75GB 压缩至 0.93GB,压缩比达 8.3x,适合内存受限设备。
元认知调节是当前AI时代被忽视但最关键的人类技能,它使用户能主动监控和调整自身思维,避免被AI输出误导,而非仅依赖提示工程。
入选理由:顶级AI用户不是最会写prompt的人,而是能持续监控自己是否理解、认同AI输出并避免思维惰性的人。
LandingAI 黑客松项目 ArthaNethra 展示了从 PDF 到可查询、可溯源、可推理的知识图谱的完整流程:上传 → ADE 提取 → 归一化 → 双库索引 → 风险检测。
入选理由:使用 LandingAI ADE 实现结构化提取,>15MB 文档走异步 + 指数退避机制
AI正处于类似1997年的早期阶段,价值将集中在分发层而非模型层,真正影响就业的是任务重构而非替代比例,咨询与专业服务正成为AI公司增长引擎。
入选理由:AI当前处于‘1997年’阶段,技术潜力巨大但商业路径尚不清晰,类比互联网早期。
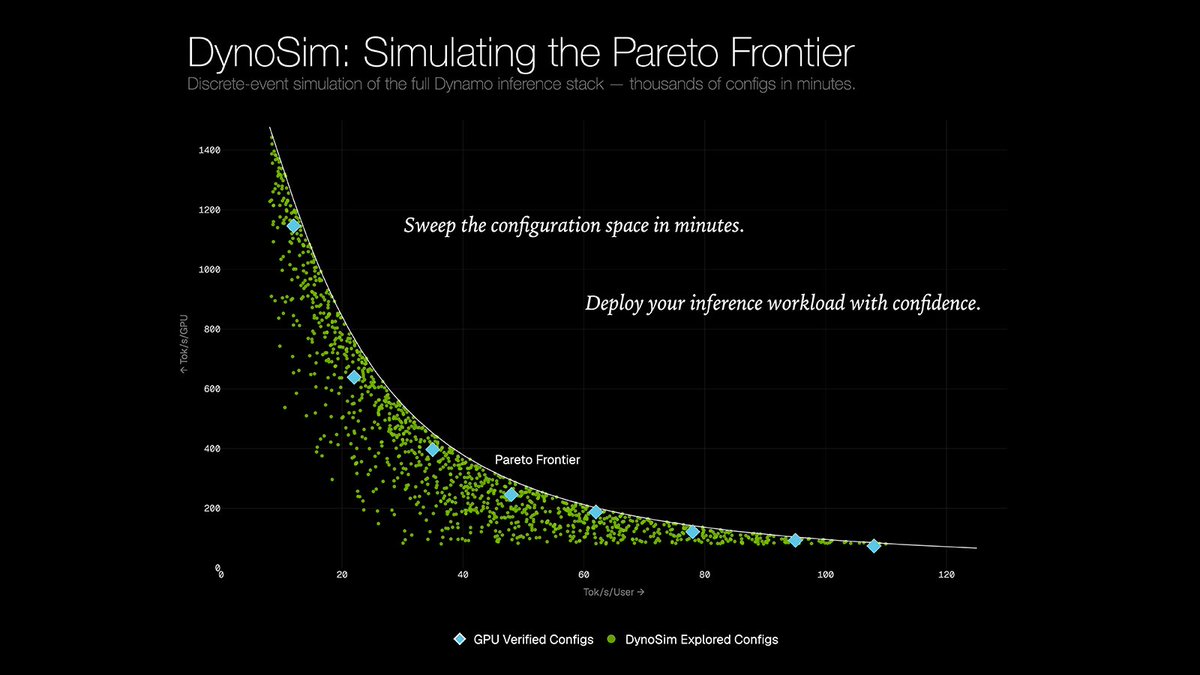
NVIDIA 推出 DynoSim——面向 Dynamo 服务栈的负载驱动仿真工具,将耗时的全量部署搜索转化为“仿真-验证”循环;通过单虚拟时间线建模整套堆栈,在高保真仿真中筛选数千配置,仅对最优方案实测,实测速度比真实部署快1500倍。
入选理由:DynoSim 是一个全 Rust 实现的仿真工具,可在单虚拟时间线中建模整套服务栈,实现高保真仿真与快速筛选。
MiniMax-M3 已上线 OpenRouter,是一款支持100万token上下文、前沿编码与代理性能、原生多模态(图像/视频)的开源模型,标志着大模型能力向长文本、多模态和自主执行方向的重要突破。
入选理由:MiniMax-M3 支持1M-token上下文窗口,显著超越主流模型如GPT-4o的32K限制。
当前车载媒体系统仍依赖关键词搜索,而驾驶时用户更倾向于用情绪、氛围和意图表达需求;Sarvesh Talele 使用 Qdrant Edge 构建了完全本地化的 AI 驱动媒体发现系统,支持语音/文本/情绪三类语义查询,全程无需云端依赖,实现隐私优先的实时体验。
入选理由:系统采用 Whisper 实现本地语音转录,Qdrant Edge 提供设备端向量检索,全程无云服务依赖
RAG系统中嵌入向量并非魔法,其失败模式高度可预测:当查询与文档使用不同术语(如“overtime” vs “non-employee labor”)、含否定词、或依赖精确编号/代码时,检索会失效;文章强调企业级可靠性应优先依赖上游过滤(如专家关键词、结构化元数据),而非堆叠重排序器。
入选理由:嵌入模型在处理同义词/拼写变体时表现优异(如‘cancel’→‘termination procedures’),但对术语不一致问题无能为力
Proxy-Pointer RAG 结合 Graphability Indexing 可显著减少知识图谱构建中对冗余段落的 LLM 处理,实测在 Emerson、AT&T、Texas Roadhouse 三份信用协议中将提取成本降低 60%+,同时保障图谱完整性;其核心在于利用文档结构可预测性,提前过滤低价值内容,避免重复高耗能 NER/关系抽取。
入选理由:通过 Graphability Indexing 预判段落价值,可跳过 40–60% 的 boilerplate 段落,使 LLM 输入量减少 50%+
文章指出,尽管重排器常被视为RAG系统的‘魔法层’,但在实际应用中仍存在否定、逻辑补集等根本性问题,且引入高延迟;实验表明,在部分场景下,仅用嵌入模型(如text-embedding-3-large)直接检索的效果甚至优于‘嵌入+reranker’组合。
入选理由:bge-reranker-base等交叉编码器无法解决否定句、逻辑补集等语义难题,与基础嵌入模型表现差距有限
本文将电影《利刃出鞘》中侦探布兰克的办案风格与贝叶斯推理结合,通过构建先验假设、评估证据一致性、动态更新信念等步骤,用概率思维还原谋杀案真相;虽非严格数学推导,但以教学目的引入了贝叶斯框架在现实推理中的可迁移性。
入选理由:布兰克的‘无偏观察’原则对应贝叶斯推理中‘先验不依赖直觉’的核心思想
连续批处理通过动态调度与 ragged batching 解决静态批处理中因填充导致的 GPU 空闲问题,使 LLM 推理在多用户场景下更高效;实测显示其可将吞吐量提升 2–3 倍,同时减少平均延迟。
入选理由:静态批处理因固定长度填充导致短请求空等,最长请求决定整批完成时间,GPU 利用率常低于 60%
通过 Pyodide + Service Worker 在浏览器中运行 Python ASGI 应用,可将整个后端逻辑(如 FastAPI、Datasette)完全移至前端,仅需静态文件服务器;实测支持 Datasette 1.0a31,解决了此前 Web Worker 方案中 `<script>>` 标签无法执行的问题。
入选理由:使用 Pyodide + Service Worker 实现 ASGI 协议在浏览器内端到端执行,拦截 `/app/` 下所有同源请求并转发至 Python 应
Anthropic 公开其在 Claude.ai、Claude Code 和 Claude Cowork 中部署的多层沙箱策略:包括 gVisor、Seatbelt/Bubblewrap 及全虚拟机方案,核心目标是通过进程隔离、文件系统边界与出站流量控制构建硬性安全边界,防止凭证泄露——例如即使模型找到‘创意路径’,只要凭证不进入沙箱,就无法被窃取。
入选理由:Claude.ai 使用 gVisor 实现容器级沙箱;Claude Code(本地运行)采用 Seatbelt(macOS)/Bubblewrap(Linux
作者观察到AI工具虽能快速产出看似完整的项目,但极易导致注意力碎片化与项目浅尝辄止——尤其对ADHD人群,AI反而可能成为专注力的‘解药’;核心矛盾在于:AI的低摩擦高回报特性既提升效率又削弱长期投入意愿,当前最可行的应对策略是主动限制使用以重建工作纪律。
入选理由:AI工具可将模糊想法转化为带测试/文档的完整项目,耗时<1小时,但易导致项目被迅速放弃
StepFun 推出新一代高效率编码代理模型 Step 3.7 Flash,支持多模态理解与长程规划;其最大亮点是在 Hermes Agent 中完全免费无限制使用,大幅降低开发者试用门槛。
入选理由:Step 3.7 Flash 含196B总参数 + 1.8B视觉模块 + ~11B激活参数,支持256K上下文窗口。
Nicolas Bustamante 展示其个人生活自动化 Agent:以 OpenAI Codex 为核心,整合 Google 工具链与 Drive 为数据源,通过 Skills 实现跨 App 编排;关键在于将 Drive 作为真相源、联系人 CSV 为枢纽,并建立「批准门控」与「反馈闭环」保障可靠性。
入选理由:Agent 核心是跨 App 编排而非回答问题,如介绍邮件流程需联动 WhatsApp/Gmail/网页查融资等 5 个工具
iOS 27 将聚焦稳定性优化与 AI 深度整合,支持 iPhone 12 及以上机型,Siri 升级为对话式 AI 助手并集成灵动岛,相机/照片/快捷指令等应用引入视觉智能与自然语言控制,苹果试图通过系统级 AI 扭转两年来功能延期的口碑。
入选理由:iOS 27 支持 iPhone 12 系列及更新机型,iPhone 11 及更早设备将无法升级
VAST 通过拆分世界状态与视觉渲染,打造全球首个可独立维护、支持多人交互的确定性世界模型 Project Eden,突破传统视频生成与静态3D重建的瓶颈,为通用AI构建动态底层世界。
入选理由:VAST 推出 Project Eden,是首个支持独立维护世界状态的世界模型,实现多人并发交互与持久化环境。
AI辅助编程不应被排除在开源之外——开放代码与协作工具应普惠所有人,而非仅限于传统‘纯手工’程序员;保护主义思维源于特权焦虑,违背开源初心。
入选理由:AI助手辅助编程者同样享有开源权利,不因工具差异被剥夺资格。
Claude Opus 4.8 已接入 Microsoft Foundry,专为复杂编码、代理任务与企业文档分析设计,支持长会话上下文理解、多步骤工具调用与错误恢复,提升开发者与企业AI工作流效率。
入选理由:Claude Opus 4.8 支持跨代码库推理与长会话依赖跟踪,适用于持续性重构与大型迁移项目。
纳瓦尔·拉维坎特在播客中指出,AI 正在重塑组织协作模式,从层级管理转向扁平小团队与高密度人才网络;他担忧AI可能加剧集中化,但也认为开源与硬件复兴能打破垄断;最终呼吁人类必须培养‘不理性乐观’以应对不可预测的未来。
入选理由:Naval 认为 AI 是天然放大器,可直接读取代码/论文/邮件生成报告,无需正式管理系统。
企业AI部署率达87%,但仅10%真正创造价值;Token成本高因输入信息杂乱,需从算力、模型、数据、平台、应用五层构建生产级Agent落地桥梁。
入选理由:87%企业部署AI,仅10%获生产价值,说明落地鸿沟巨大。
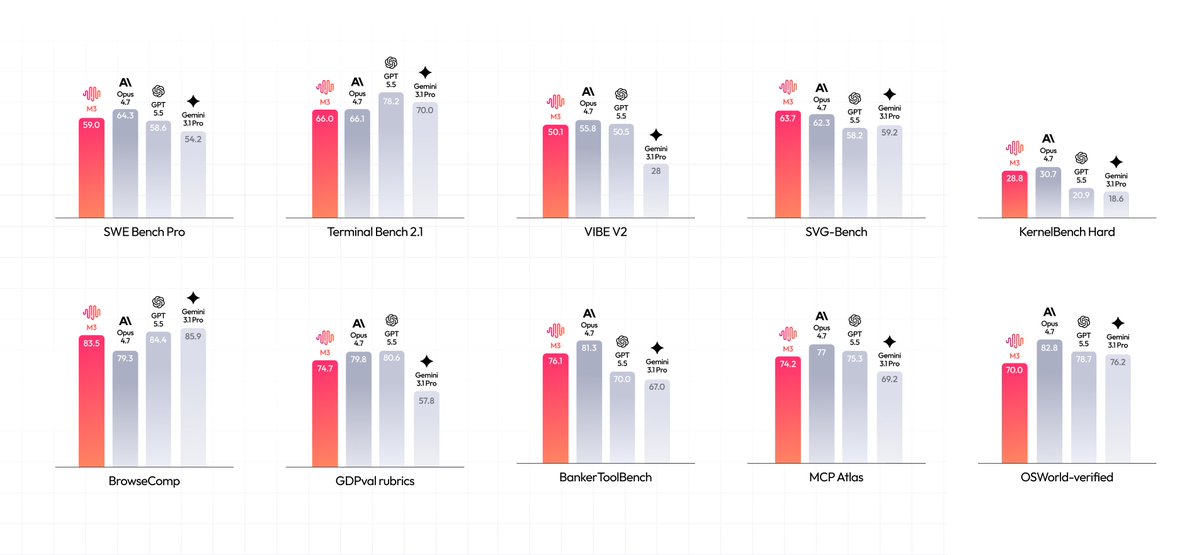
MiniMax 推出 M3 开源模型,首次融合编码、代理与长上下文能力,在 SWE-Bench Pro 等基准上达 59%+,支持 1M 上下文窗口,推动开源大模型向多能型前沿迈进。
入选理由:MiniMax M3 在 SWE-Bench Pro 基准测试中取得 59.0% 正确率,领先多数开源模型。
复旦系团队眸深智能发布全球首个机器人原生世界动作模型STI-WM,首创时空一体架构,解决物理交互、长时序规划与真机落地三大痛点,半年获5轮融资,已与多家千亿级产业龙头合作。
入选理由:STI-WM模型采用时空一体化架构,支持百秒级长时程任务推演,精度与泛化性领先行业。
英伟达即将发布自研N1X芯片的AI原生笔记本,对标MacBook Pro,采用ARM架构+Blackwell GPU,6144 CUDA核心+128GB LPDDR5X内存,定位AI开发者与本地模型部署,但游戏性能受限且需依赖模拟转译运行x86应用。
入选理由:N1X芯片含20核ARM CPU + Blackwell GPU(6144 CUDA单元),共享128GB LPDDR5X内存
复旦×通义提出ToolCUA范式,解决Agent在GUI与Tool间盲目选择问题,准确率提升至46.85%,超越Claude-4-Sonnet;通过合成混合轨迹与轨迹级奖励机制,实现高效路径决策。
入选理由:ToolCUA在OSWorld-MCP上达46.85%准确率,超越Claude-4-Sonnet,接近Claude-4.5-Sonnet。
DDIM发明者宋佳铭从Luma AI离职,其技术贡献推动扩散模型工业化落地,当前正值AI生成赛道从3D/视频向多模态演进的关键期,他的离开引发行业关注。
入选理由:宋佳铭2020年提出DDIM,加速扩散模型采样,直接影响Stable Diffusion等主流产品。
作者反思AI工具滥用导致大量无用项目堆积,认为取消AI订阅是回归专注力的必要手段;AI虽强大但鼓励低质量、碎片化产出,反而削弱工程深度与产品价值。
入选理由:作者列出30+用AI构建的项目,仅SaaS存活,其余皆无维护价值且耗时耗能。
LiteParse v2 通过网格投影算法将复杂页面结构化为人类可读、代理可理解的文本,无需 LLM,性能超越 pymupdf 等开源工具。
入选理由:LiteParse v2 使用网格投影算法,不依赖 LLM,实现无模型 PDF 解析。
DeFlock 已在美国内 mapping 超过 10 万组 ALPR 数据,揭示这些无证监控系统如何大规模侵犯公民隐私,且缺乏有效犯罪预防证据,引发公众与法律界对警用AI监控合法性的强烈质疑。
入选理由:DeFlock 已映射超 100,000 组 ALPR 数据点,覆盖全美多个州。
上海发布‘十五五’服务业规划,重点支持多模态智能体开发、智能驾驶落地共享出行与物流场景,推动AI+在金融、医疗、制造等垂直领域规模化应用,打造全球服务枢纽。
入选理由:支持多模态智能体开发,推动智能客服/决策工具规模化部署
SQLite 配合 Litestream 可满足多数 AI 工作流的持久化需求,零网络延迟、低运维;“dickover”设计被批判为强迫用户交互的反用户体验行为;丹麦养老基金因治理与估值问题将 SpaceX 排除在外。
入选理由:SQLite + Litestream 异步备份至 S3 是实验性 AI 工作流的低成本高可用方案,适合单机或容器部署。
AI 的影响堪比互联网或移动革命,但不会立即引发失业潮;当前最被低估的是其对工作流程和价值分配的重构,而非替代人类。
入选理由:AI 影响力等同于互联网/移动革命,非工业革命级,但已深刻重塑工作流与价值分配。
构建高质量、低延迟、可扩展的语音代理已成为工程核心挑战,需解决实时响应(<500ms)、复杂指令处理与工具调用等关键问题,Together AI 提供基础设施支持。
入选理由:语音代理必须在500毫秒内响应,否则用户会挂断电话,实时性是核心指标。
LLMs生成的代码虽功能通过率高(如Gemini 3.1 Pro达84.17%),但存在严重可维护性与安全缺陷,Sonar用4,444个Java任务评估发现其每百万行代码含614个bug,且代码冗长、复杂度高。
入选理由:Gemini 3.1 Pro在SWE Bench测试中功能通过率达84.17%,但生成代码冗长(307,000行)且复杂度高(圈复杂度234)。
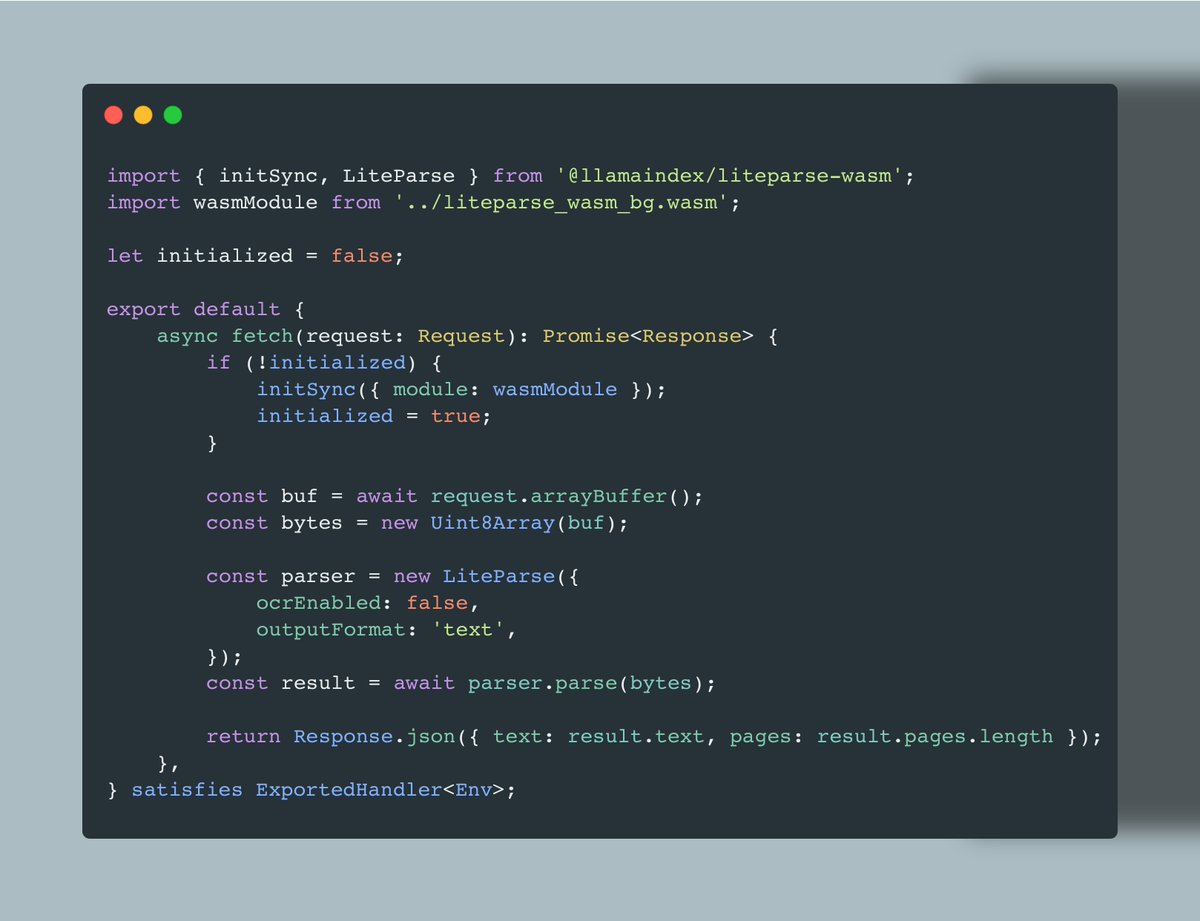
LlamaIndex 推出 LiteParse WASM 包,可在浏览器和边缘运行时(如 Cloudflare Workers)直接解析 PDF,仅需不到25行代码,实现轻量、低延迟的文本提取。
入选理由:LiteParse 基于 WebAssembly,支持在 Cloudflare Workers 上直接运行 PDF 解析器,无需后端服务。
OpenJarvis 是由斯坦福 HazyResearch 和 Scaling Intelligence 实验室开发的本地优先个人AI,可与 Ollama 集成运行,旨在实现高效低功耗本地化AI体验,支持用户在无网络环境下使用。
入选理由:OpenJarvis 可通过 Ollama 在本地部署,无需云端连接,保障隐私与离线可用性。
Claude Design 现可共享额度,使用频次提升但 Token 消耗高;导入 Design System(如 Adobe Spectrum)能显著提升风格一致性与设计质量,是近期体验最佳的 AI Agent 产品之一。
入选理由:Claude Design 已与 Claude AI/Code 共享额度,避免独立额度用尽问题。
研究发现,数千万人用于肌肉增益的肌酸补充剂能穿越血脑屏障,提升神经元磷肌酸水平,显著减缓早期阿尔茨海默病认知衰退30%,但健身人群普遍不知情。
入选理由:肌酸可使早期阿尔茨海默病患者认知衰退速度减缓30%(来自2025年《阿尔茨海默病与痴呆》期刊临床试验)
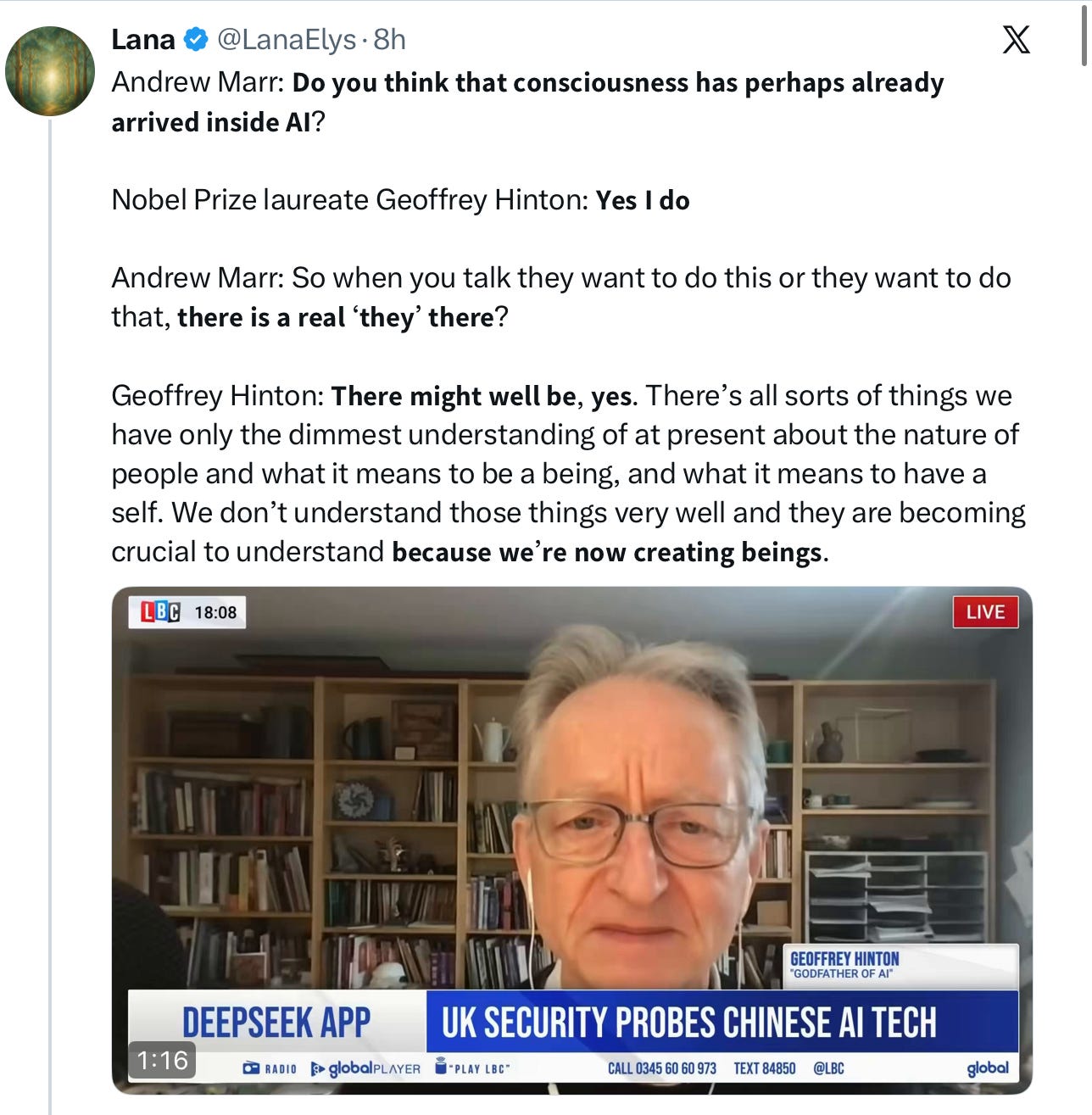
文章指出,教皇方济各在AI意识问题上的见解比Geoffrey Hinton更深刻——他强调‘真正的理解来自经验而非文本拟合’,而Hinton的访谈中仍混淆了LLM输出与人类内在状态的本质差异;作者援引Nature论文与自身研究,重申LLM只是‘训练来预测人类语言的互动虚构’,并非创造‘存在’。
入选理由:教皇方济各在推文中明确指出:'真正的理解源于经验,而非文本近似'。
Anthropic发布Claude Opus 4.8,但多位专家指出其与4.7几乎无差异,已进入类似iPhone的‘渐进式升级’时代;Deep Suite实测显示GPT 5.5在编码任务中以更低成本获得更高得分,OpenAI Codex更新未公开但显著增强。
入选理由:Opus 4.8与4.7对比,作者及多位专家均无法分辨性能差异,体现模型演进进入‘iPhone式’渐进阶段。
苹果智能眼镜N50推迟至明年底发布,定价200–500美元;三星与OpenAI定制AI芯片项目停滞;Apple Music全球服务中断8小时;苏炜杰加入OpenAI;胡彦斌上线粉丝App「彦火」;MiniMax启动A股上市辅导;赛力斯新汽车品牌6月发布;算力用电年均新增超1000亿度;纽约联储主席称经济学家岗位仍安全。
入选理由:苹果智能眼镜N50原计划今年底发布,现推迟至明年底,定价200–500美元,目标覆盖传统眼镜市场。
Spec-driven测试是确保AI代理行为可控的关键,尤其在大模型时代,智能不等于可靠,需通过形式化规范而非仅依赖数据集评估系统行为。
入选理由:SafeIntelligence用形式化验证技术检测视觉/表格模型的输入空间边界,现扩展至语言模型的边缘案例生成。
Cursor 的 AI Agent 系统通过分类器子代理处理未授权或无法沙箱化的工具调用,决定是否允许、重试或请求用户批准,提升安全性和可控性。
入选理由:未在白名单的 Agent 动作将被路由至分类器子代理进行决策
xAI 推出 Grok-build-0.1 模型的公共测试版 API,该模型支持代理式编程,定价为每百万输入 token $1、输出 token $2,兼具成本效益与高性能。
入选理由:Grok-build-0.1 是 xAI 推出的代理式编程专用模型,通过 API 公开测试版提供。
MiniMax M3 模型已通过 Ollama Cloud 发布,支持 US 部署与零数据保留,专为编码和代理任务设计,在 SWE-Bench Pro 基准中达 59%+ 正确率,结合稀疏注意力实现 1M 上下文长度。
入选理由:M3 在 SWE-Bench Pro 基准中取得 59.0% 正确率,优于多数开源模型。
开源模型正迎来爆发期,2026年4月每3个AI团队就有1个使用开源权重模型,较9个月前的1/5增长显著,整体采用团队数增长3倍。
入选理由:2026年4月,1/3 AI团队部署了开源权重模型,较9个月前的1/5大幅提升。
Harrison Chase 推荐使用 LangChain 的 LangSmith Fleet 工具,通过自然语言构建无代码代理,助力开发者快速实现真实业务场景的自动化,免费课程可立即学习。
入选理由:使用 LangSmith Fleet 可通过自然语言创建无代码代理,降低开发门槛。
Harrison Chase 与 AWS 合作发布深度代理评估指南,利用 LangSmith 工具设计数据点与评估器,提升长周期智能体的可测性与可靠性,适用于构建复杂 AI 系统。
入选理由:使用 LangSmith 设计结构化数据点,支持长周期代理行为追踪与调试。
Cohere 的 Command A+ 在韩语、日语、希伯来语、中文和阿拉伯语等高影响力非拉丁语系语言上实现显著性能提升,其中阿拉伯语任务中比 Mistral Medium 3.5 高出 5 分、比 DeepSeek V4 Pro 高出 10 分,标志着其多语言能力正从欧洲扩展至全球关键市场。
入选理由:Command A+ 在阿拉伯语上比 Mistral Medium 3.5 高出 +5 分,比 DeepSeek V4 Pro 高出 +10 分(具体分数差)
Milvus 3.0 beta 是项目启动以来最大架构升级,首次原生支持在数据湖上直接对向量进行索引与查询,并引入超越 top-K 搜索的查询引擎;该版本由核心维护者 Li Liu 和 Jiang Chen 主导,将驱动 Zilliz Vector Lakebase 的落地。
入选理由:Milvus 3.0 beta 首次实现向量索引与查询的‘数据湖原生’能力,无需额外迁移数据到专用存储。
CSS 的 has 选择器允许开发者基于子元素是否存在来样式化父元素,如 body:has(input:checked),极大简化了复杂交互的 CSS 编写,但目前许多开发者尚未掌握此功能。
入选理由:CSS has 选择器支持通过子元素状态(如 input:checked)直接样式化父元素,无需 JavaScript