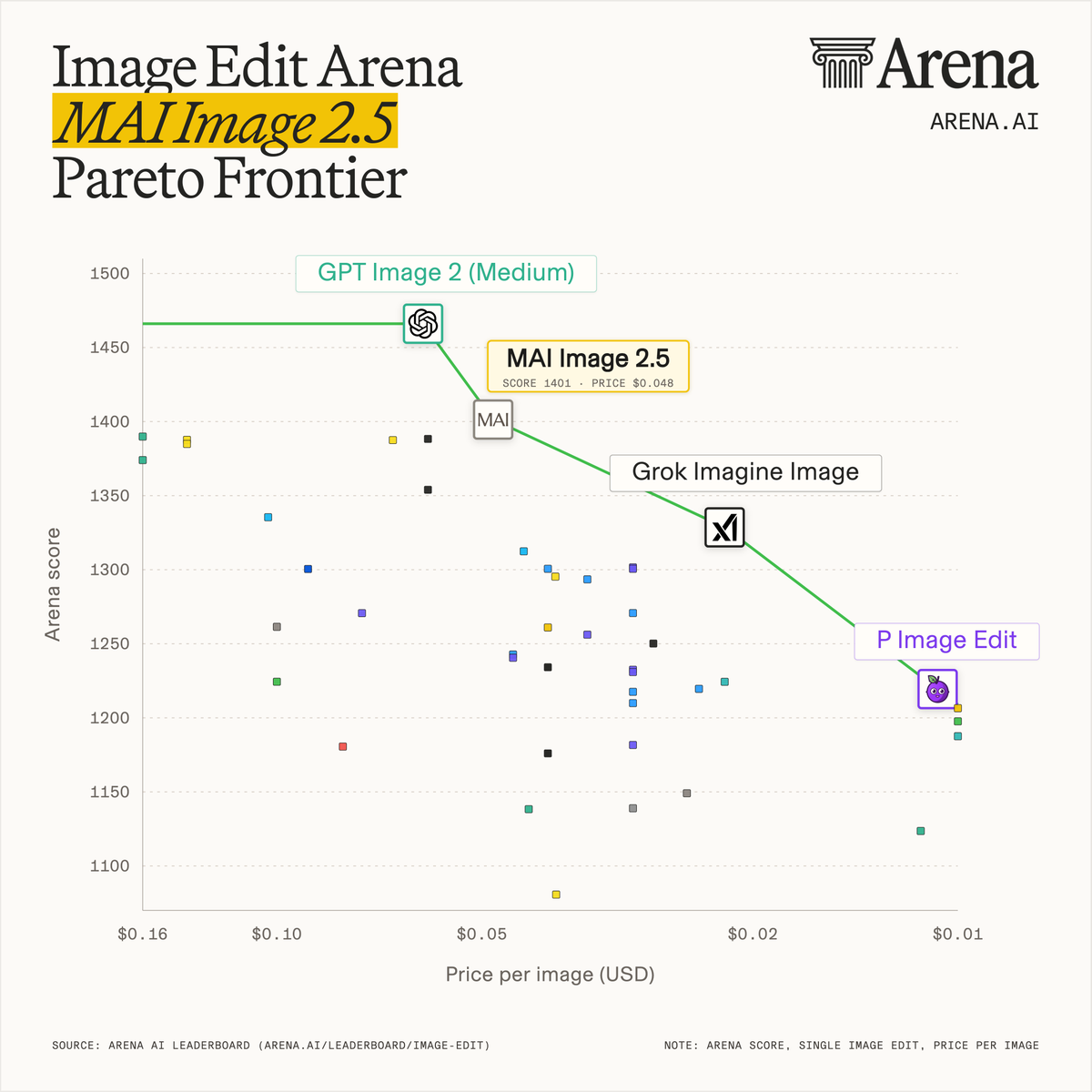
Meet MAI-Image-2.5 - ranked third on the @arena text-to-image leaderboard. It's another great advance in quality. And with Build just a week away, there's much more to come from the @MicrosoftAI team. I can't wait.
Mustafa Suleyman(@mustafasuleyman)106 字 (约 1 分钟)
75
MAI-Image-2.5 在 @arena 文本转图像排行榜中排名第三,展示了质量上的进步。微软团队即将在 Build 大会上展示更多成果。
入选理由:MAI-Image-2.5 排名第三
FeaturedTweet#MAI-Image-2.5#@arena#Build#MicrosoftAI中文