再见 Seedance… 迎接 Gemini Omni:谷歌新 AI 视频模型太疯狂了
AI Master3942 字 (约 16 分钟)
85
Google 发布 Gemini Omni 视频模型,支持多模态输入并具备物理理解能力,填补 Sora 停运后的免费市场空白。
入选理由:Gemini Omni 支持文本、图像、音频、视频和绘图五种输入方式生成视频。
精选视频#Gemini Omni#AI 视频生成#Google AI#Sora 替代方案#多模态模型英文
产品对比
Gemini Omni 和 Spark 都是 AI 领域的产品。以下是基于 traeai 收录的真实报道数据的全面对比。
产品
也叫:Omni
Google推出的多模态AI模型,据称支持视频理解与物理驱动动作生成
20 篇相关报道
模型
也叫:Apache Spark
分布式计算框架,被SQLMesh和Bytewax作为对比对象提及。
3 篇相关报道
20
Gemini Omni 相关
0
共同提及
3
Spark 相关
Google 发布 Gemini Omni 视频模型,支持多模态输入并具备物理理解能力,填补 Sora 停运后的免费市场空白。
入选理由:Gemini Omni 支持文本、图像、音频、视频和绘图五种输入方式生成视频。
Google I/O 2026为初创公司推出Gemini 3.5系列模型、Agentic Data Cloud及安全平台整合,提供高效AI开发与成本优化方案。
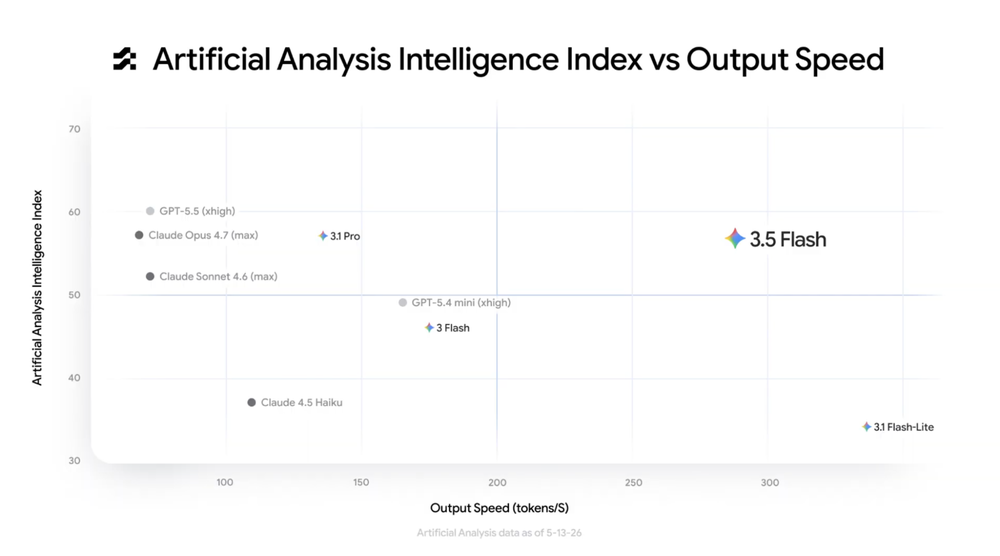
入选理由:Gemini 3.5 Flash模型性能媲美大模型但速度提升,成本低于同类产品50%
Gemini Omni Flash是DeepMind推出的新模型,能够通过多种输入生成高质量视频并支持自然语言编辑,结合物理知识与世界知识实现创意与准确性的平衡。
入选理由:Gemini Omni Flash支持通过文本、图像、视频或音频输入生成视频,并允许通过对话逐步编辑,保持场景连贯性。
Google 在 I/O 2026 发布了多个 AI 更新,包括更快更便宜的 Gemini 3.5 Flash 和功能强大的多模态模型 Gemini Omni,引发社区热议。
入选理由:Gemini 3.5 Flash 模型速度比 3.1 Pro 快两倍以上,API 定价为输入 $150/百万 tokens。
Google I/O宣布进入Agentic Era,推出Gemini 3.5系列模型及多模态Gemini Omni,强化AI代理功能与Gemini App交互体验。
入选理由:Gemini 3.5 Flash成为默认模型,提升速度、编码和多模态能力,预计6月发布Pro版本
Google I/O 2026揭示了将Gemini集成到每个产品中的AI代理策略,规模从每月9.7万亿扩展到3.2千万亿token,新的TPU芯片分为训练/推理专用,Gemini Omni作为能够理解现实的多模态模型成为头条。
入选理由:Google scaled from 9.7T to 3.2 quadrillion tokens/month in 2 years, showing explosive AI usage growth
Google I/O 2024展示了Gemini Omni等新模型,强调多模态生成能力,但实际性能受限,与OpenAI在消费端展开门户争夺战。
入选理由:Google的Gemini Omni模型支持多模态生成,但测试中对视频/图像输入限制严格,质量与Cine Dance 2相当。
Gemini Omni是DeepMind推出的新多模态生成模型,结合VEO、Nano Banana等模型实现视频、图像和交互式模拟的生成与编辑,支持物理概念理解和自然语言视频编辑,现已推出Gemini Omni Flash版本。
入选理由:Gemini Omni整合了Gemini的推理能力和生成模型,实现多模态内容创作与物理模拟(如动能和重力)。
2026年数据工程领域最值得关注的10个Python库,涵盖编排、摄入、质量与存储四大核心场景,其中Prefect、SQLMesh、dlt和Bytewax等新兴工具正重塑数据管道构建方式,显著降低运维复杂度并提升可维护性。
入选理由:Prefect允许用纯Python装饰函数构建可观测流水线,无需额外数据库即可实现实时监控与自动重试。
Arena.ai 使用统一标签系统处理每周数百万次投票,通过 Databricks 和 Spark 构建高效数据管道。
入选理由:Arena.ai 每周处理数百万次用户投票,依赖统一标签系统进行分类。
本文介绍了NVIDIA Developer社区在纽约的Spark黑客松获奖项目,展示了开发者如何利用NVIDIA技术构建多智能体系统。
入选理由:NVIDIA Developer社区在纽约的Spark黑客松中,有多个团队展示了基于NVIDIA技术的多智能体系统开发成果。