🎙️ How I AI: Gemini Omni: Clone yourself with AI in under 15 minutes & Shopping with Claude
Lenny's Newsletter1328 字 (约 6 分钟)
85
AI视频工具让非专业人士快速生成高质量视频,但角色一致性仍是挑战。
入选理由:使用Gemini Omni可在15分钟内生成完整视频,无需视频制作经验。
精选文章#AI视频#Gemini Omni#创意工具#AI生成英文
模型
别名:Gemini全能模型
Google的多模态AI模型,支持复杂场景生成。
已跟踪 30 条高相关材料
最近变化
2026-07-14 · 使用Veo、Gemini Omni和Nano Banana Pro三款AI模型进行重建
为什么值得关注
Gemini Omni 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
🎙️ How I AI: Gemini Omni: Clone yourself with AI in under 15 minutes & Shopping with Claude
Lenny's Newsletter · 8.5 分
AI视频工具让非专业人士快速生成高质量视频,但角色一致性仍是挑战。
The latest AI news we announced in May 2026
The Keyword (blog.google) · 8.5 分
Google 2026 年 5 月 AI 更新发布 Gemini 3.5 模型与 Omni 工具,推动 AI 主动化与跨领域应用。
Goodbye Seedance... Gemini Omni: Google’s New AI Video Model is INSANE
AI Master · 8.5 分
Google 发布 Gemini Omni 视频模型,支持多模态输入并具备物理理解能力,填补 Sora 停运后的免费市场空白。
已收录 30 条与 Gemini Omni 相关的内容,按评分排序。
AI视频工具让非专业人士快速生成高质量视频,但角色一致性仍是挑战。
入选理由:使用Gemini Omni可在15分钟内生成完整视频,无需视频制作经验。
Google 发布 2026 年 5 月 AI 更新,推出 Gemini 3.5 模型与 Omni 工具,推动 AI 主动化与跨领域应用。
入选理由:Gemini 3.5 实现前沿智能代理与代码生成,Omni 融合推理与创作能力
Google 发布 Gemini Omni 视频模型,支持多模态输入并具备物理理解能力,填补 Sora 停运后的免费市场空白。
入选理由:Gemini Omni 支持文本、图像、音频、视频和绘图五种输入方式生成视频。
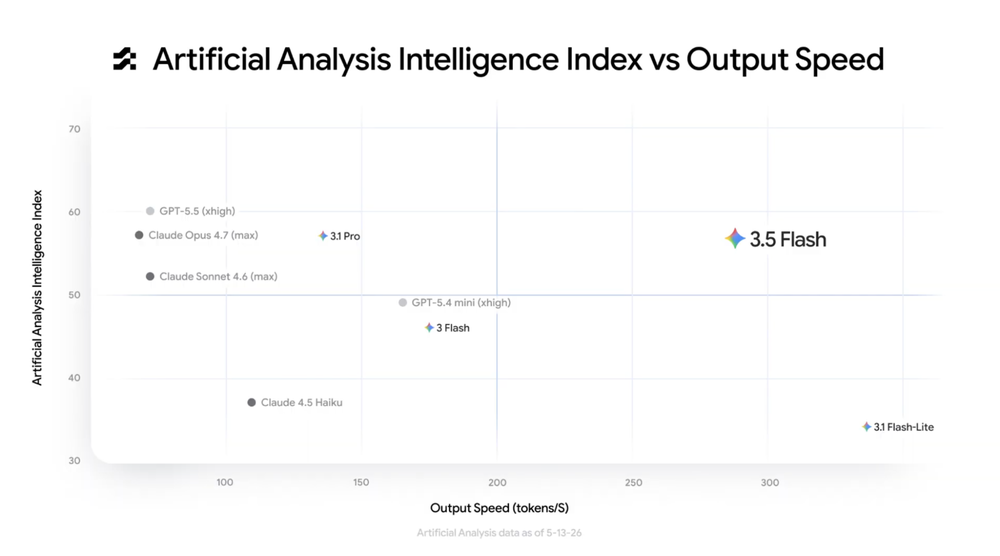
Google I/O 2026为初创公司推出Gemini 3.5系列模型、Agentic Data Cloud及安全平台整合,提供高效AI开发与成本优化方案。
入选理由:Gemini 3.5 Flash模型性能媲美大模型但速度提升,成本低于同类产品50%
Gemini Omni Flash是DeepMind推出的新模型,能够通过多种输入生成高质量视频并支持自然语言编辑,结合物理知识与世界知识实现创意与准确性的平衡。
入选理由:Gemini Omni Flash支持通过文本、图像、视频或音频输入生成视频,并允许通过对话逐步编辑,保持场景连贯性。
Google 在 I/O 2026 发布了多个 AI 更新,包括更快更便宜的 Gemini 3.5 Flash 和功能强大的多模态模型 Gemini Omni,引发社区热议。
入选理由:Gemini 3.5 Flash 模型速度比 3.1 Pro 快两倍以上,API 定价为输入 $150/百万 tokens。
Google I/O宣布进入Agentic Era,推出Gemini 3.5系列模型及多模态Gemini Omni,强化AI代理功能与Gemini App交互体验。
入选理由:Gemini 3.5 Flash成为默认模型,提升速度、编码和多模态能力,预计6月发布Pro版本
Google I/O 2026揭示了将Gemini集成到每个产品中的AI代理策略,规模从每月9.7万亿扩展到3.2千万亿token,新的TPU芯片分为训练/推理专用,Gemini Omni作为能够理解现实的多模态模型成为头条。
入选理由:Google scaled from 9.7T to 3.2 quadrillion tokens/month in 2 years, showing explosive AI usage growth
Google DeepMind利用AI技术重建贝利1959年未被记录的著名进球,结合历史资料与先进模型实现数字复原。
入选理由:使用Veo、Gemini Omni和Nano Banana Pro三款AI模型进行重建
Google Gemini App发布Gemini Omni,旨在减少屏幕时间,增加户外活动。
入选理由:Google Gemini App发布Gemini Omni,旨在减少屏幕时间,增加户外活动。
Google I/O 2024展示了Gemini Omni等新模型,强调多模态生成能力,但实际性能受限,与OpenAI在消费端展开门户争夺战。
入选理由:Google的Gemini Omni模型支持多模态生成,但测试中对视频/图像输入限制严格,质量与Cine Dance 2相当。
Gemini Omni是DeepMind推出的新多模态生成模型,结合VEO、Nano Banana等模型实现视频、图像和交互式模拟的生成与编辑,支持物理概念理解和自然语言视频编辑,现已推出Gemini Omni Flash版本。
入选理由:Gemini Omni整合了Gemini的推理能力和生成模型,实现多模态内容创作与物理模拟(如动能和重力)。
Google发布了一系列新的AI功能和产品,包括Gemini Omni多模态模型和Gemini 3.5 Flash,能通过自然语言对话生成和编辑视频,并在代理编码方面表现优异。
入选理由:Gemini Omni是新的多模态模型家族,专注于视频创建和编辑,能理解复杂物理概念并生成高度准确的视频内容。
使用Google Flow结合Gemini Omni模型,可在15分钟内完成从人脸扫描到生成1分钟AI数字人视频的全流程。该工具通过角色一致性功能解决多镜头连贯问题,并利用AI辅助生成分镜脚本,显著降低无视频制作经验者的创作门槛,但目前在微表情和物理规律模拟上仍存在恐怖谷效应。
入选理由:Google Flow配合Gemini Omni模型,支持5分钟内完成人脸扫描与AI分身创建。
Gemini 已服务 9 亿月活用户,Google I/O 2026 将发布 Gemini 3.5 Flash、Gemini Omni 视频模型及 Gemini Spark 主动式助理,强调多模态、主动交互与本地化体验。
入选理由:Gemini 用户规模达 9 亿/月,覆盖 230 国、70+ 语言;Google I/O 2026 将发布 Gemini 3.5 Flash 和 Gemini Omni。
Google I/O 2026发布Gemini Spark和Gemini Omni,前者集成Gmail/Drive/Calendar,后者重新定义用户界面,AI生成动态界面取代固定应用。
入选理由:Gemini Spark与Google服务深度集成,无需复杂配置,适合日常用户
Google I/O 2026 推出了 Gemini Spark 和 Gemini Omni,前者集成 Gmail、Drive 和 Calendar,后者可能重新定义用户界面。
入选理由:Gemini Spark 集成 Gmail、Drive 和 Calendar
Google 推出 Gemini Omni 模型,支持任意输入生成任意内容,首批集成至 Gemini App、Flow 和 YouTube,API 即将开放。
入选理由:Gemini Omni 可根据任意输入生成任意内容,首批支持视频生成,类似‘Nano Banana’的视频版
Pika展示Gemini Omni在视频编辑中的多场景应用,支持背景替换、角度调整等操作。
入选理由:Gemini Omni支持视频背景替换、角度调整、服装更换等操作
Gemini Omni是谷歌新推出的多模态生成模型,支持从任意输入生成视频等内容,现已集成到Gemini App、Flow和YouTube,API即将开放。
入选理由:Gemini Omni可从任意输入生成视频,类似Nano Banana但专为视频设计
Gemini Omni通过对话式交互简化视频编辑流程,用户上传视频后可直接要求AI进行修改,但缺乏技术细节和使用案例。
入选理由:Gemini Omni支持通过自然对话指令直接修改已上传视频内容
Google Gemini App 发布 Gemini Omni 的产品演示预告,但缺乏技术深度和实用信息,工程师无需关注。
入选理由:文章仅为产品发布预告,未提供技术实现细节或架构分析。
Google Gemini Omni 生成的视频默认嵌入不可见的 SynthID 水印,用户可通过 Gemini App 验证来源,旨在提升内容透明度。
入选理由:Gemini Omni 生成的所有视频均自动嵌入 SynthID 数字水印,肉眼不可见。
Google Gemini Omni 现已向全球所有 Google AI Plus、Pro 和 Ultra 订阅者开放。
入选理由:Google Gemini Omni 对全球 Google AI Plus、Pro 和 Ultra 订阅者开放。
Google AI Plus、Pro和Ultra订阅用户现可在Gemini应用中试用Gemini Omni,并被鼓励分享创作。
入选理由:全球Google AI Plus/Pro/Ultra订阅用户可直接在Gemini应用内体验Gemini Omni新功能
测试 Gemini Omni 在视频编辑和地理位置理解方面的能力,展示其基于地图截图生成新场景的无缝转换能力。
入选理由:Gemini Omni 能根据 Google Maps 截图自动重拍视频场景
AI模型厂商发布信息不透明,关键参数和定价信息缺失,用户需花费大量时间在官网查找基础信息,反映了行业信息披露问题。
入选理由:Qwen Max 3.7参数规模和定价信息未公开披露
Gemini Omni 声称可通过单提示理解视频、应用物理并生成新动作,但全文仅为社交平台宣传帖,无技术细节或验证数据。
入选理由:Gemini Omni 声称支持视频输入+物理模拟+新动作生成三步流程
Google Gemini App 展示了一个图像生成提示词示例,要求保留原画面并让屏幕蜜袋鼯‘活过来’跳入掌心,但无技术细节或可复现信息。
入选理由:该推文仅展示一个提示词示例('preserve all original footage exactly...'),无模型参数、推理时长或输出质量数据。
Google Gemini Omni已推出并展示了一些创作成果,但实际内容严重不足,页面可能未完全加载导致信息缺失。
入选理由:Gemini Omni已正式发布