Comprehensive observability for Amazon SageMaker AI LLM inference: From GPU utilization to LLM quality
AWS Machine Learning Blog2218 字 (约 9 分钟)
92
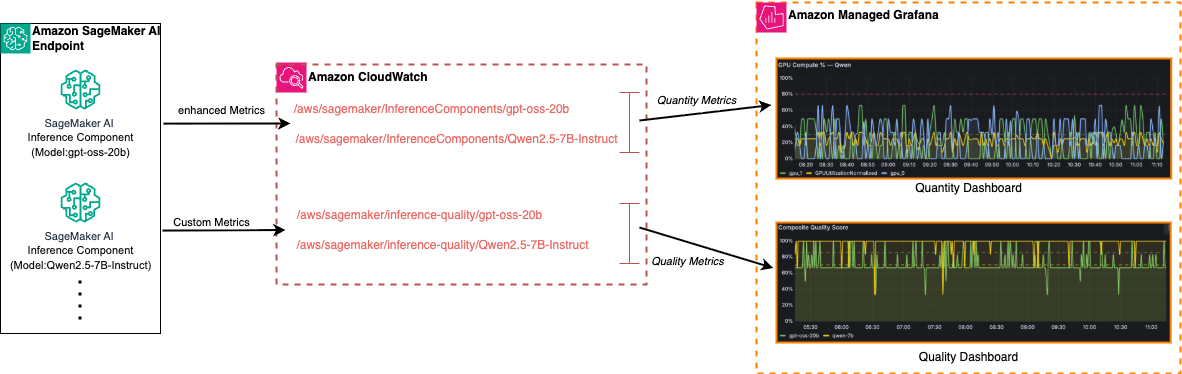
AWS proposes a full-stack observability solution for SageMaker LLM inference, collecting infrastructure metrics (GPU utilization, latency) and custom quality metrics (response accuracy, compliance) via CloudWatch, visualized in Managed Grafana—enabling dual-dimension monitoring to address cases where systems appear healthy but produce poor outputs, or deliver high-quality responses inefficiently.
入选理由:SageMaker AI Inference 支持单 endpoint 多 inference components 部署(如 gpt-oss-20b + Qwen2.5-7B-Instruct),实现模型隔离与共享资源协同。
FeaturedArticle#LLM#Observability#Amazon SageMaker#CloudWatch#Grafana英文