The top announcements for startups from Google I/O '26
Google Cloud Blog1554 字 (约 7 分钟)
85
Google I/O 2026 introduces Gemini 3.5 series models, Agentic Data Cloud, and security platform integrations to empower startups with efficient AI development and cost optimization solutions.
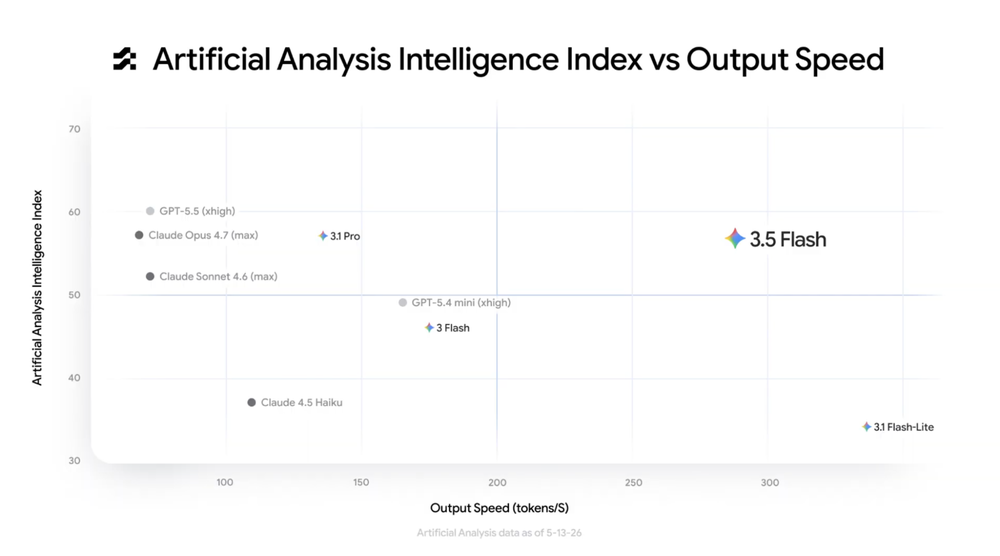
入选理由:Gemini 3.5 Flash模型性能媲美大模型但速度提升,成本低于同类产品50%
FeaturedArticle#Gemini models#Agentic Data Cloud#Google Cloud#AI development#Startups英文







