Google I/O 2026初创公司重要公告
Google Cloud Blog1554 字 (约 7 分钟)
85
Google I/O 2026为初创公司推出Gemini 3.5系列模型、Agentic Data Cloud及安全平台整合,提供高效AI开发与成本优化方案。
入选理由:Gemini 3.5 Flash模型性能媲美大模型但速度提升,成本低于同类产品50%
精选文章#Gemini模型#Agentic Data Cloud#Google Cloud#AI开发#初创公司英文
模型对比
Gemini 3.5 Flash 和 Qwen3.6-27B 都是 AI 领域的模型。以下是基于 traeai 收录的真实报道数据的全面对比。
模型
也叫:Gemini Flash
Google 发布的高性能 AI 模型。
20 篇相关报道
模型
也叫:Qwen3.6
通义千问系列开源大模型,适用于工具驱动型任务。
3 篇相关报道
20
Gemini 3.5 Flash 相关
0
共同提及
3
Qwen3.6-27B 相关
Google I/O 2026为初创公司推出Gemini 3.5系列模型、Agentic Data Cloud及安全平台整合,提供高效AI开发与成本优化方案。
入选理由:Gemini 3.5 Flash模型性能媲美大模型但速度提升,成本低于同类产品50%
Google 在 I/O 2026 发布了多个 AI 更新,包括更快更便宜的 Gemini 3.5 Flash 和功能强大的多模态模型 Gemini Omni,引发社区热议。
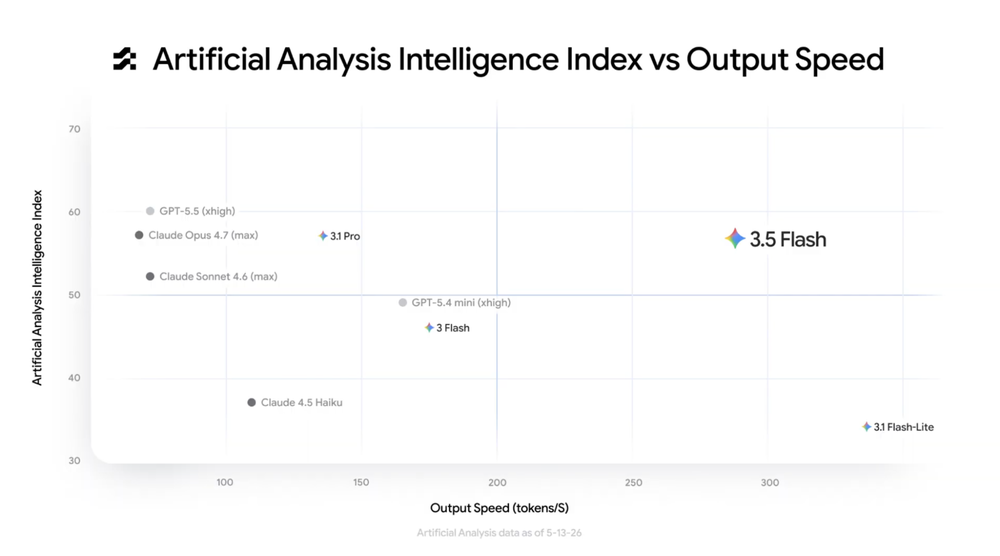
入选理由:Gemini 3.5 Flash 模型速度比 3.1 Pro 快两倍以上,API 定价为输入 $150/百万 tokens。
谷歌发布Gemini 3.5 Flash模型,Meta因沙特和阿联酋政府要求封锁人权账号,欧洲启动主权支付系统以减少对Visa/Mastercard依赖,明尼苏达州禁止预测市场,GitHub调查恶意扩展事件,Qwen公布研发平台,Railway宕机恢复,特斯拉废水排放争议。
入选理由:谷歌的Gemini 3.5 Flash在多模态和代理任务中表现优异,速度是其他模型的4倍,已应用于搜索和应用。
通过优化设置、使用特定工具和提示词调整,可显著提升Anti-gravity 2.0的使用体验和性能,免费及$20层级已足够满足需求。
入选理由:Anti-gravity免费层级性能提升3倍,Gemini 3.5 Flash支持所有付费计划且$20学生折扣计划性价比高
谷歌推出全新AI搜索功能,引入对话式交互、图像上传、Gemini模型接入及个人智能助手四大革新,提升搜索体验与效率。
入选理由:AI模式通过动态扩展输入框提升对话式搜索体验
谷歌声称其AI代理以916美元构建操作系统,但文章指出该演示缺乏透明度和验证细节,实际意义有限。
入选理由:谷歌称单次提示构建OS,实则提示长达数千行。
Gemini 3.5 Flash在视觉任务上超越3.1 Pro版本,平均速度快6倍,展现了多模态理解能力优势。该性能提升对实时视觉应用具有重要意义。
入选理由:Gemini 3.5 Flash在视觉任务上表现优于3.1 Pro版本
Gemini 3.5 Flash (Medium) 在 AutomationBench 上表现最佳,中等思考设置优于高设置,建议用于大多数任务。
入选理由:Gemini 3.5 Flash (Medium) 在 AutomationBench 上排名第一。
本地部署LLM代理需解决推理速度与长会话状态管理问题,通过优化vLLM服务器和结构化世界状态,可将单次调用耗时从15秒降至2秒以内,支持科学工作流的可复现性需求。
入选理由:使用vLLM优化推理性能,单次调用耗时从15秒降至2秒内
llama.cpp 加入 MTP 支持后,本地模型推理速度提升 78%,Qwen3.6-27B 在 A10G 上从 25 token/s 提升至 45 token/s。
入选理由:MTP 支持使 llama.cpp 推理速度提升 78%
开发者利用本地运行的大模型Qwen3.6-27B实现自然语言到Shell命令的转换,提升操作效率。
入选理由:使用Qwen3.6-27B大模型实现在本地将自然语言转为Shell命令。







