ByteByteGo Newsletter
Must-Know Failure Modes in Distributed Systems
8.5Score

TL;DR · AI 摘要
分布式系统中常见的故障模式及其应对策略是工程师必须掌握的核心知识。
核心要点
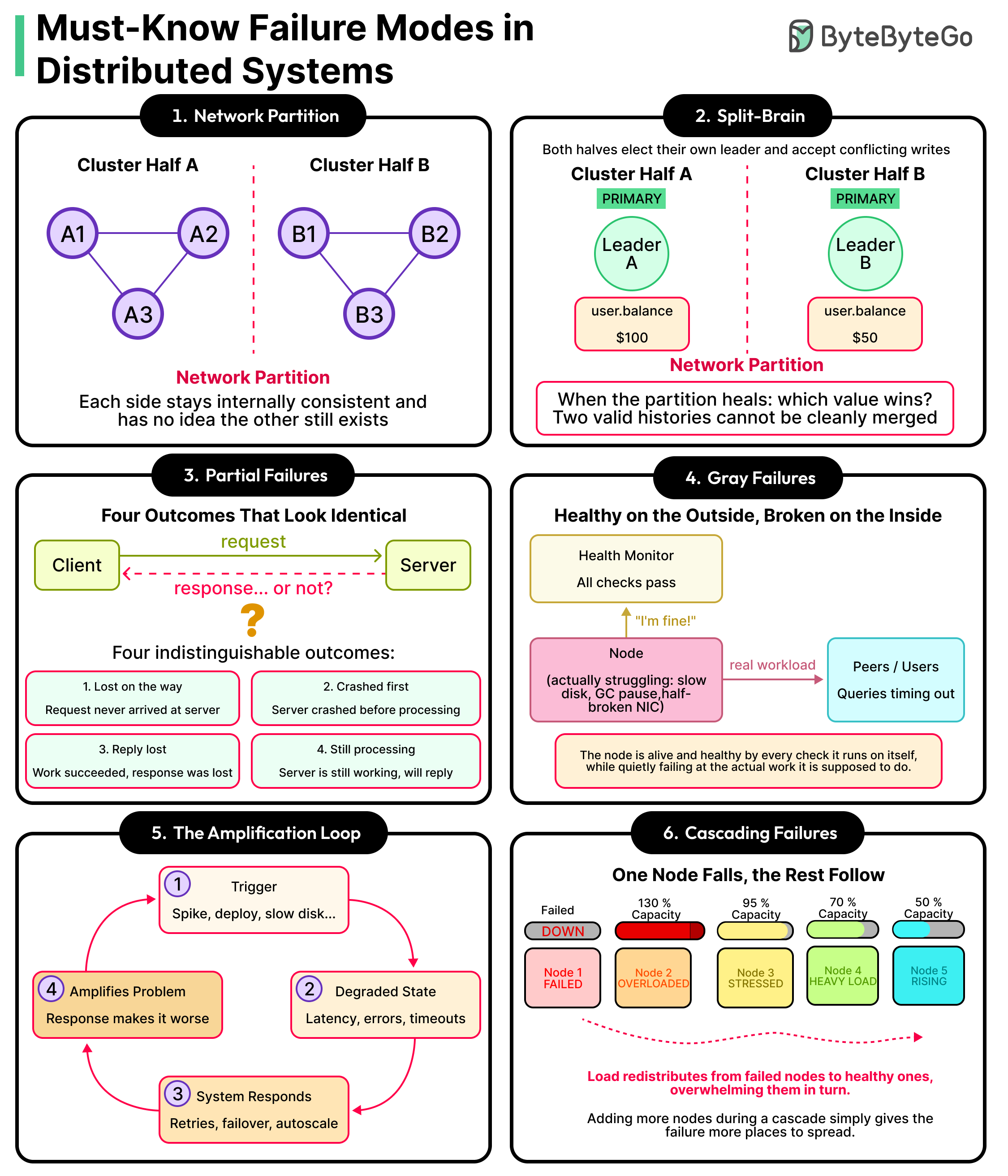
- 分布式系统可能在所有服务器正常运行时仍出现故障,如数据不一致或死锁。
- 常见的故障模式包括脑裂、活锁和级联故障,需通过一致性协议和超时机制应对。
- 监控和日志系统应能检测隐性故障,如静默数据损坏和慢查询问题。
结构提纲
按章节快速跳转。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- 分布式系统故障模式
金句 / Highlights
值得收藏与分享的关键句。
Distributed systems can quietly serve wrong data while every dashboard glows green.
They are recurring failure patterns that have been showing up across systems for decades.
Every server can report healthy while users are seeing errors.
#分布式系统#故障模式#系统设计
打开原文什么是分布式系统的"正常运行"?
在单机环境下,答案非常直接,因为程序要么在运行,要么已崩溃,两者之间的界限通常能从堆栈跟踪中明显看出。
分布式系统就没那么简单了。每个服务器都可能报告状态正常,而用户却在不断遇到错误;整个系统可能从技术角度看仍在运行,却陷入无法自行恢复的状态;甚至可能在所有监控面板都显示绿色健康的情况下,悄悄提供错误的数据。
这些情况未必源于传统意义上的程序漏洞。它们是数十年来反复出现在各类系统中的典型故障模式,具有特定名称、作用机制和标准化的防御手段。
本文将探讨分布式系统中最显著的故障模式,并介绍针对每种模式的标准应对方案。