使用 Stream Vision Agents 和 Amazon Nova 2 Sonic 构建实时语音代理

TL;DR · AI 摘要
AWS 与 Stream 合作推出实时语音代理方案,可快速部署生产级应用。
核心要点
- Amazon Nova 2 Sonic 提供端到端语音处理能力,无需单独 STT/TTS 服务。
- Vision Agents 框架支持 React、iOS 等多平台 SDK,集成 25+ 插件。
- Stream Edge Network 实现 <30ms 音频延迟和 <500ms 连接时间。
结构提纲
按章节快速跳转。
- §挑战概述
构建语音 AI 应用需协调多个复杂系统并确保低延迟体验。
结合 Amazon Nova 2 Sonic、Vision Agents 和 Stream Edge Network 构建完整语音代理栈。
- §架构设计
Stream 处理媒体传输,Nova 2 Sonic 提供 AI 能力,Vision Agents 实现集成。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- 实时语音代理架构
- 核心组件
- Amazon Nova 2 Sonic
- Vision Agents
- Stream Edge Network
- 功能特性
- 端到端语音处理
- 多平台 SDK 支持
- 低延迟媒体传输
金句 / Highlights
值得收藏与分享的关键句。
Amazon Nova 2 Sonic 支持双向音频流和原生对话轮次检测。
Vision Agents 提供 25+ 插件和跨平台 SDK,减少 70% 的基础设施开发工作。
Stream Edge Network 实现全球平均 <30ms 音频延迟和 <500ms 连接时间。
标题:使用 Stream Vision Agents 和 Amazon Nova 2 Sonic 构建实时语音代理 | 亚马逊云科技
URL 来源:https://aws.amazon.com/blogs/machine-learning/real-time-voice-agents-with-stream-vision-agents-and-amazon-nova-2-sonic/
发布日期:2026-05-14T09:23:48-08:00
Markdown 内容: _本文由__Stream_ _的技术营销负责人 Neevash Ramdial 联合撰写_
构建具备自然感和高响应性的生产级语音代理是一项复杂的工程挑战。你需要协调语音到语音模型、管理低延迟音频流,并处理连接生命周期。同时,还需确保在 Web、移动和桌面应用中提供一致的用户体验。
在本文中,你将学习如何结合使用 Stream 的开源框架 Vision Agents、Amazon Bedrock 和 Amazon Nova 2 Sonic,快速构建可在几分钟内投入生产的实时语音代理。我们将深入解析集成机制,逐步讲解代码示例,并探讨函数调用、自动重连以及多语言语音支持等高级功能。
面临的挑战
构建支持语音的 AI 应用需要协调多个复杂系统,这些系统必须稳定协同工作。你必须在管理实时音频流基础设施的同时,整合语音识别、语言模型和文本转语音服务。而每一项技术都有其独特的延迟特性和故障模式。典型的语音交互流程包括:从用户麦克风采集音频,将其流式传输至语音转文本服务,通过语言模型处理文本,生成回复内容,再将该回复转换为语音并传送给用户。整个过程必须在几百毫秒内完成,才能带来自然流畅的体验。任何环节的延迟都会破坏对话节奏,令用户感到沮丧。
除了核心 AI 流程外,生产环境中的语音应用还必须应对现实部署中的各种复杂情况:网络连接不稳定、浏览器兼容性问题、会话超时,以及服务不可用时的优雅降级。开发者往往花费大量时间编写重连逻辑、管理 WebRTC 连接、处理边缘异常,而非专注于真正的 AI 功能开发。这种基础设施负担导致团队要么投入数月时间构建定制化解决方案,要么只能选择功能有限的现成产品,无法满足特定需求。Vision Agents 在抽象底层基础设施复杂性的同时,提供了灵活定制 AI 体验的能力。
解决方案概览
本方案整合了三个关键组件:
- Amazon Nova 2 Sonic —— 一款通过 Amazon Bedrock 提供的语音到语音基础模型,支持实时双向音频流、原生轮次检测和函数调用能力。Nova 2 Sonic 可处理完整的语音到语音流程,接收音频输入并直接输出音频结果,无需额外集成独立的语音识别(STT)和语音合成(TTS)服务。
- Stream 的 Vision Agents —— 一个用于构建实时语音与视频 AI 代理的开源 Python 框架。它采用插件化架构,已集成 25 多种服务,提供生产级部署工具,以及适用于 React、iOS、Android、Flutter 和 React Native 的客户端 SDK。该系统以灵活性为核心设计理念。你可以使用 Stream 的全球边缘网络实现高效性能,也可以集成自选的实时通信(RTC)服务商。Vision Agents 通过简洁的基于装饰器的接口屏蔽不同服务商的技术差异,使得客服代理、工作流自动化和 API 驱动操作等场景得以用极少的样板代码实现。借助 Vision Agents,你可以基于开源框架、第三方模型提供商和电话服务来构建 AI 应用。
- Stream 边缘网络 —— 一个全球分布的边缘网络,通常可实现低于 500ms 的接入时间和不到 30ms 的音频延迟,为客户端与你的代理后端之间提供实时传输层。
这三个组件共同构成了完整的技术栈:Stream 负责实时媒体传输和客户端体验,Amazon Nova 2 Sonic 提供 AI 智能能力,而 Vision Agents 则作为粘合层将它们无缝集成。
架构概览
系统设计遵循清晰的关注点分离原则:Stream 的基础设施负责实时媒体传输和客户端连接,而 Amazon Nova Sonic 则运行在客户自己的 AWS 账户中,提供 AI 智能能力。这种分离确保敏感数据和业务逻辑始终由客户掌控,同时借助 Stream 全球分布式边缘网络,为用户提供预期的低延迟媒体体验。
Stream 的边缘网络充当终端设备与 Vision Agent 工作进程之间的媒体中介。当用户说话时,音频被采集、加密,并通过 UDP 以 RTP 协议发送至最近的 Stream SFU(选择性转发单元)。SFU 终止 WebRTC 连接,处理 NAT 穿越和带宽估算,并将音频轨道转发给 Vision Agent 工作进程,就像它是另一个通话参与者一样。这意味着代理能够自然地融入通话模型——它作为另一个对等方,通过与人类参与者相同的基础设施接收和发送音频。
音频数据在系统中双向流动:用户的输入语音由 Vision Agent 工作进程解码为原始 PCM,通过 Bedrock 实时 API 流式传输到 Amazon Nova Sonic,Nova Sonic 返回的响应音频帧则被重新编码、打包为 RTP 格式,并通过 SFU 回传至客户端设备。端到端延迟通常低于 500 毫秒。语音活动检测(VAD)在工作进程中运行,用于检测语音边界和打断事件,而浏览器中的回声消除功能有助于防止代理自身的输出重新触发 VAD 循环。
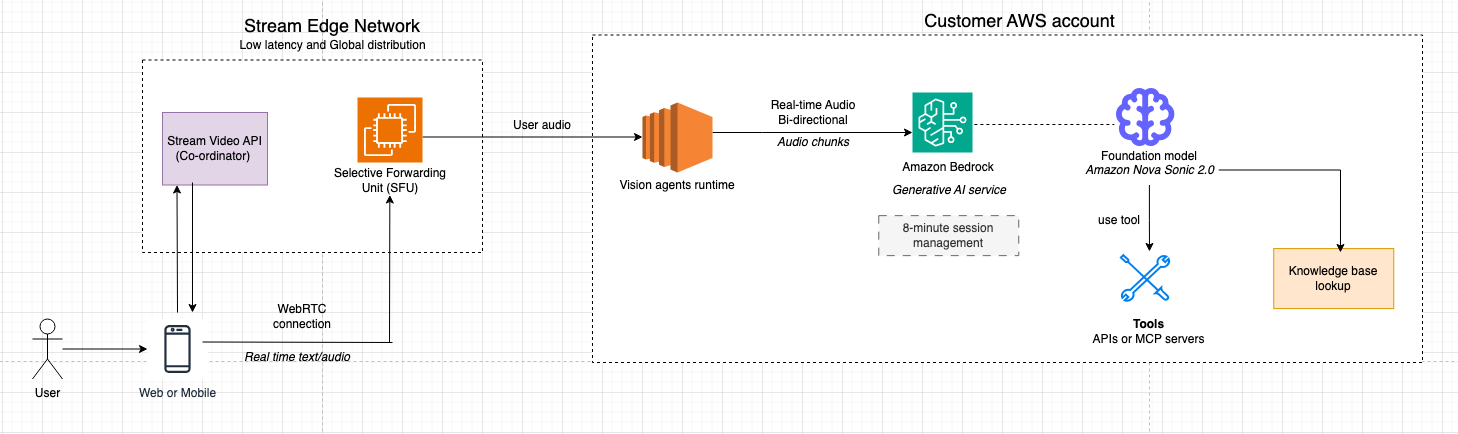
账户边界
- 客户 AWS 账户
- 业务逻辑与编排(代理策略、工具、数据访问)。
- 集成 Amazon Bedrock 以访问 Amazon Nova 模型。
- Stream AWS 账户
- 全球 WebRTC/SFU 媒体平面、TURN/STUN 及信令服务。
- Vision Agent 运行时(工作进程),作为机器人对等方终止 WebRTC,并桥接客户的 Amazon Bedrock 集成。
端到端媒体流
- 用户从网页或移动设备加入
- 应用嵌入 Stream 的音频客户端 SDK,请求麦克风权限(以及可选的摄像头),并加入配置为支持 AI 参与的通话类型。
- 媒体通过 UDP 以 RTP 协议发送,确保低延迟且无队头阻塞的传输效果。2. 区域 SFU 终止
- 区域 SFU 终止
- 最近区域的 Stream SFU 节点终止用户的 WebRTC 连接,处理带宽估算、多路并发流(simulcast)和 NAT 穿越。
- SFU 将相关音频轨道转发给 Vision Agent 工作进程,就像它是另一个参与者一样。
- Vision Agent 工作进程
- 专用的 Vision Agent 工作进程维护该会话的 PeerConnection 状态。
- 它将音频解码为原始 PCM,然后将 PCM 帧流式传输到 Amazon Bedrock 服务,并在客户 AWS 账户中作为实时会话转发至 Amazon Nova 2 Sonic。
- Amazon Nova 2 Sonic 通过 Amazon Bedrock 与 Vision Agent 集成
- Amazon Nova 2 Sonic 检测语音边界,并执行语音到语音建模(理解、推理和 TTS),并可根据需要调用客户系统的工具(如 RDS、API、知识库)。
- 它能优雅地处理打断行为,并保持完整的对话上下文,使对话自然连贯。
- 向用户流式返回响应
- 当 Amazon Nova Sonic 生成响应音频帧时,Vision Agent 工作进程:
- 将其切片并封装进带有单调递增时间戳的 RTP 中,避免出现间隙或漂移
- 通过相同的 WebRTC 会话经由 SFU 发送 RTP 数据包。浏览器的 WebRTC 栈解码并播放音频,延迟低于 500 毫秒。
- 打断、转录与侧边数据
- 浏览器中的回声消除有助于防止代理自身输出重新触发 VAD。
- 当用户打断时,新语音会通过 RTCDataChannel 触发中断信号,导致工作进程停止转发 Amazon Nova Sonic 输出并重置本地缓冲区。
这一架构看似复杂,但 Vision Agents 抽象了大部分复杂性。让我们看看实际代码是什么样的:
前提条件
开始之前,请确保具备以下条件:
- 已通过环境变量、IAM 角色或 AWS 命令行界面(AWS CLI)配置好 AWS 凭证。对于生产环境,建议使用附加到计算资源的 IAM 角色,而非长期有效的凭证。对于本地开发,可使用 AWS CLI 配置文件(
aws configure)或 AWS SSO。切勿将包含凭证的.env文件提交至版本控制系统。 - 拥有 Stream 账户及 Audio API 密钥和密钥(每月可免费获得 333,000 名参与者分钟数)。
- 已安装 Python 3.12 或更高版本。
- 已安装 uv 包管理器(
pip install uv)。 - 已安装 Vision Agents(
uv add vision-agents)
快速入门
步骤 1:创建新的项目目录并安装带 AWS 插件的 Vision Agents
mkdir voice-agent
cd voice-agent
uv init
uv add "vision-agents[getstream,aws]"
python-dotenvPowerShell
vision-agents[aws] 扩展功能会安装 Amazon Bedrock 插件及其依赖项,包括 boto3、aws-sdk-bedrock-runtime 和用于语音活动检测的 Silero VAD。
步骤 2:配置环境变量
在项目根目录创建一个 .env 文件来管理配置。对于 AWS 凭证,我们建议在此文件中引用你的 AWS_PROFILE,以便应用程序在与 AWS 资源交互时能够访问凭证。不建议直接在此文件中存储 AWS 访问密钥。
对于 Stream API 凭证,你可以使用 HashiCorp Vault 或 AWS Secrets Manager 等第三方库,但安全考虑不在本文讨论范围内。
# Stream API 凭证
STREAM_API_KEY=test/geststream/api_key
STREAM_API_SECRET=test/getstream/api_secret
# AWS 凭证
AWS_PROFILE=your_aws_profile_name
AWS_REGION=us-east-1PowerShell
Vision Agents 在启动时会自动发现这些环境变量,因此你无需显式地将它们传递给每个客户端。
步骤 3:构建你的第一个语音代理
创建一个包含以下代码的 main.py 文件:
import asyncio
from dotenv import load_dotenv
from vision_agents.core import Agent, User, Runner
from vision_agents.core.agents import AgentLauncher
from vision_agents.plugins import aws, getstream
load_dotenv()
async def create_agent(**kwargs) -> Agent:
agent = Agent(
edge=getstream.Edge(),
agent_user=User(name="Helpful Assistant", id="agent"),
instructions="你是一个乐于助人的语音助手。请简洁友好。",
llm=aws.Realtime(
model="amazon.nova-2-sonic-v1:0",
region_name="us-east-1",
voice_id="matthew",
),
)
return agent
async def join_call(agent: Agent, call_type: str, call_id: str, **kwargs) -> None:
call = await agent.create_call(call_type, call_id)
async with agent.join(call):
await asyncio.sleep(2)
await agent.llm.simple_response(
text="热情地问候用户,并询问如何提供帮助。"
)
await agent.finish() # 运行直到通话结束
if __name__ == "__main__":
Runner(AgentLauncher(create_agent=create_agent, join_call=join_call)).cli()Python
第4步:运行语音代理
运行代理:
uv run main.py run
PowerShell
不到30行代码,你就拥有了一个由 Amazon Nova Sonic 驱动的、功能完整且实时的语音代理,可通过 Stream 客户端 SDK 访问。
理解 Amazon Bedrock 集成
让我们深入了解一下 aws.Realtime 插件的工作原理。
使用 Amazon Nova 2 Sonic 实现双向流式传输
Amazon Nova 2 Sonic 使用基于事件的双向流式 API。这种方法不同于传统的请求-响应模式,允许几乎连续的音频在两个方向上同时流动。Vision Agents AWS 插件通过结构化的事件序列来管理这种复杂性:
- 会话初始化 — 发送包含推理配置(温度、最大 token 数、top-p)的
sessionStart事件。 - 提示设置 —
promptStart事件用于配置音频输出格式(24kHz PCM)、语音选择和工具定义。 - 系统指令 — 以
SYSTEM角色发送系统指令作为文本内容块。 - 音频流式传输 — 麦克风音频帧(每个约 32 毫秒)作为
audioInput事件进行流式传输。 - 响应流式传输 — Nova Sonic 返回带有生成语音的
audioOutput事件。 - 会话终止 — 通过
promptEnd和sessionEnd事件干净地关闭连接。
每个内容块遵循三部分模式:contentStart → 内容载荷 → contentEnd。这种层次结构使模型在整个交互过程中保持正确的上下文。
以下是插件中会话启动事件的样子:
def _create_session_start_event(self) -> Dict[str, Any]:
return {
"event": {
"sessionStart": {
"inferenceConfiguration": {
"maxTokens": 1024,
"topP": 0.9,
"temperature": 0.7,
}
},
"turnDetectionConfiguration": {
"endpointingSensitivity": "MEDIUM"
},
}
}Python
添加函数调用功能
Amazon Nova 2 Sonic 的关键能力之一是在实时对话期间支持原生函数调用。这使得你的语音代理能够在维持自然口语对话的同时执行诸如查询数据库、调用 API 和触发工作流等操作。使用 @llm.register_function 装饰器来定义模型可以调用的函数:
import asyncio
from dotenv import load_dotenv
from typing import Dict, Any
from vision_agents.core import Agent, User, Runner
from vision_agents.core.agents import AgentLauncher
from vision_agents.plugins import aws, getstream
load_dotenv()
async def create_agent(**kwargs) -> Agent:
agent = Agent(
edge=getstream.Edge(),
agent_user=User(name="Weather Assistant", id="agent"),
instructions="""你是一个乐于助人的天气助手。当用户询问天气时,
使用 get_weather 函数获取当前天气状况。你也可以处理简单的计算任务。""",
llm=aws.Realtime(
model="amazon.nova-2-sonic-v1:0",
region_name="us-east-1",
),
)
@agent.llm.register_function(
name="get_weather",
description="获取指定城市的当前天气"
)
async def get_weather(location: str) -> Dict[str, Any]:
# 在生产环境中,调用真实的天气 API
return {
"city": location,
"temperature": 72,
"condition": "晴朗",
"humidity": "45%"
}
@agent.llm.register_function(
name="calculate",
description="执行数学计算"
)
def calculate(operation: str, a: float, b: float) -> dict:
operations = {
"add": lambda x, y: x + y,
"subtract": lambda x, y: x - y,
"multiply": lambda x, y: x * y,
"divide": lambda x, y: x / y if y != 0 else None,
}
result = operations.get(operation, lambda x, y: None)(a, b)
return {"operation": operation, "a": a, "b": b, "result": result}
return agent
async def join_call(agent: Agent, call_type: str, call_id: str, **kwargs) -> None:
await agent.create_user()
call = await agent.create_call(call_type, call_id)
async with agent.join(call):
await asyncio.sleep(2)
await agent.llm.simple_response(
text="问候用户并告知他们你可以查询天气。"
)
await agent.finish()
if __name__ == "__main__":
Runner(AgentLauncher(create_agent=create_agent, join_call=join_call)).cli()Python
Amazon Nova 2 Sonic 中函数调用的工作原理
当模型决定调用函数时,将发生以下序列:
- Nova 2 Sonic 会发出一个包含函数名称和参数的
toolUse事件。 - Vision Agents 插件拦截此事件,反序列化参数并运行已注册的 Python 函数。
- 结果通过
toolResult事件传回 Nova,并包裹在标准的contentStart→toolResult→contentEnd模式中。 - Nova 2 Sonic 将函数结果融入其响应中,并自然地继续语音对话。
使用这种方法,你可以构建复杂的多步骤工作流。例如,语音代理可以在一次自然对话中查找客户记录、检查库存并下单。
使用 Amazon Bedrock 的标准大语言模型(LLM)
除了实时语音对话语音外,AWS 插件还通过 aws.LLM 提供了标准的大语言模型集成。当你希望将 Amazon Bedrock 模型与独立的语音转文本(STT)和文本转语音(TTS)提供商组合用于自定义流水线架构时,这非常有用:
from vision_agents.core import Agent, User
from vision_agents.plugins import aws, getstream, cartesia, deepgram, smart_turn
agent = Agent(
edge=getstream.Edge(),
agent_user=User(name="Custom Pipeline Agent"),
instructions="Be helpful and concise.",
llm=aws.LLM(
model="anthropic.claude-3-haiku-20240307-v1:0",
region_name="us-east-1"
),
tts=cartesia.TTS(),
stt=deepgram.STT(),
turn_detection=smart_turn.TurnDetection(
buffer_duration=2.0,
confidence_threshold=0.5
),
)Python
标准 LLM 支持通过 converse_stream() 实现流式响应、完整的对话历史管理、支持 Claude 等模型的视觉输入,以及每请求最多三轮函数执行的多轮工具调用。
使用 Amazon Polly 进行文本转语音
对于自定义流水线架构,AWS 插件还包括 Amazon Polly TTS 集成。当你使用非实时 LLM(如 Amazon Bedrock 上的 Claude 或其他提供商)且需要高质量语音合成时,这非常有用:
from vision_agents.plugins import aws
tts = aws.TTS(
region_name="us-east-1",
voice_id="Joanna",
engine="neural", # 'standard' 或 'neural'
language_code="en-US"
)Python
Amazon Polly TTS 支持标准和神经引擎、用于精细语音控制的 SSML 输入,以及多种语言和声音。神经引擎生成更自然的语音,在你基于 AWS 基础设施构建自定义 STT → LLM → TTS 流水线时是一个理想选择。
清理资源
要删除 Stream 呼叫并终止正在运行的 Vision Agent 进程,请执行:
uv run main.py stop
PowerShell
重要提示:所有对 Amazon Nova 2 Sonic 的 API 调用均会产生 Amazon Bedrock 费用。你可以运行清理命令以终止会话,避免持续产生费用。活动会话在显式终止前可能会持续产生费用。
使用场景
在技术基础就绪后,值得探讨这些能力如何转化为有意义的实际影响。低延迟语音、对话管理和工具集成的结合,为众多行业开辟了广泛的应用场景,其中自然的口语交互可以替代或增强传统界面。
使用场景 1:无屏幕或低注意力环境中的语音接口
Vision Agents 与 Amazon Nova 2 Sonic 的组合非常适合用户无法可靠操作屏幕的环境,例如驾驶、现场服务、物流、医疗保健或现场作业。在这些情境下,语音成为主要交互方式,而不仅仅是一项便利功能。
- 借助 Amazon Nova 2 Sonic,你可以实现低延迟、自然轮流说话的实时语音对话,允许用户自由发言、打断回应或自我纠正,而不会中断对话流程。
- Vision Agents 在多轮对话中管理对话状态和任务逻辑,将语音输入转化为结构化操作,例如获取下一个任务分配、更新任务状态、记录备注或请求人工协助。
由于代理在整个交互过程中保持上下文,用户可以发出后续命令或澄清信息,而无需重复内容。例如,快递司机可以询问:“我的下一站是哪里?” 接收语音导航指引,然后说“将上一次配送标记为完成”,再跟进“联系调度中心”,全程无需触碰屏幕,同时代理实时更新后台系统。
使用场景 2:大规模高并发呼入电话支持
Vision Agents 与 Amazon Nova 2 Sonic 的组合专为处理大量呼入支持电话而设计,可解决人工坐席成为瓶颈的问题。该使用场景的核心在于扩展性:减少排队时间、分流重复请求,并将人工坐席保留给需要他们介入的情况。
- 借助 Amazon Nova 2 Sonic,来电者可以进行低延迟的实时语音对话,能够自然地描述问题,而不是在预设的 IVR 菜单中导航。
- Vision Agents 协调意图识别、对话状态和后端集成(如订单系统、账户记录或工单服务),使常见请求可在通话中自动解决。
当问题超出预设的置信度阈值或需要人工干预时,代理会附带结构化上下文转接至人工坐席,避免来电者重复陈述问题。在高峰时段,可能有数百名客户来电询问配送延迟情况。与其让他们排队等待,不如立即由语音代理接听,检查订单状态、解释延迟原因、提供后续步骤,并仅在检测到异常时才转接至人工坐席。这将电话系统从基于队列的成本中心转变为连续的一线问题解决层。
结论
本文介绍了如何使用 Stream 的 Vision Agents 框架结合 Amazon Bedrock 与 Amazon Nova 2 Sonic 构建实时语音代理。我们涵盖了架构设计、双向流协议、自动重连处理、函数调用、多语言支持以及生产环境部署等内容。Stream 的低延迟边缘网络与 Amazon Nova Sonic 原生的语音到语音能力相结合,为构建语音 AI 应用提供了坚实的基础。Vision Agents 框架抽象了连接生命周期管理、音频编码、基于语音活动检测(VAD)的重连机制以及工具执行等复杂编排逻辑,使你能够专注于代理的业务逻辑和用户体验。
如果你准备进一步探索,我们鼓励你尝试为你的具体应用场景添加自定义函数,或利用多语言功能来构建面向全球的应用。你可以从 https://github.com/GetStream/Vision-Agents 的 Vision Agents 代码仓库开始。在那里,你将找到更多示例、插件文档以及社区讨论内容。如需深入了解集成细节,可查阅 AWS 插件文档:https://visionagents.ai/integrations/aws-bedrock,而 Amazon Nova 2 Sonic 的详细说明则可在 AWS Nova 用户指南中找到,其中包含了双向流 API 的完整参考。你可以在 https://getstream.io/ 注册 Stream 开发者账户,立即免费开始构建。
- * *