Gemma 4 12B:开发者指南
Google Developers Blog1171 字 (约 5 分钟)
92
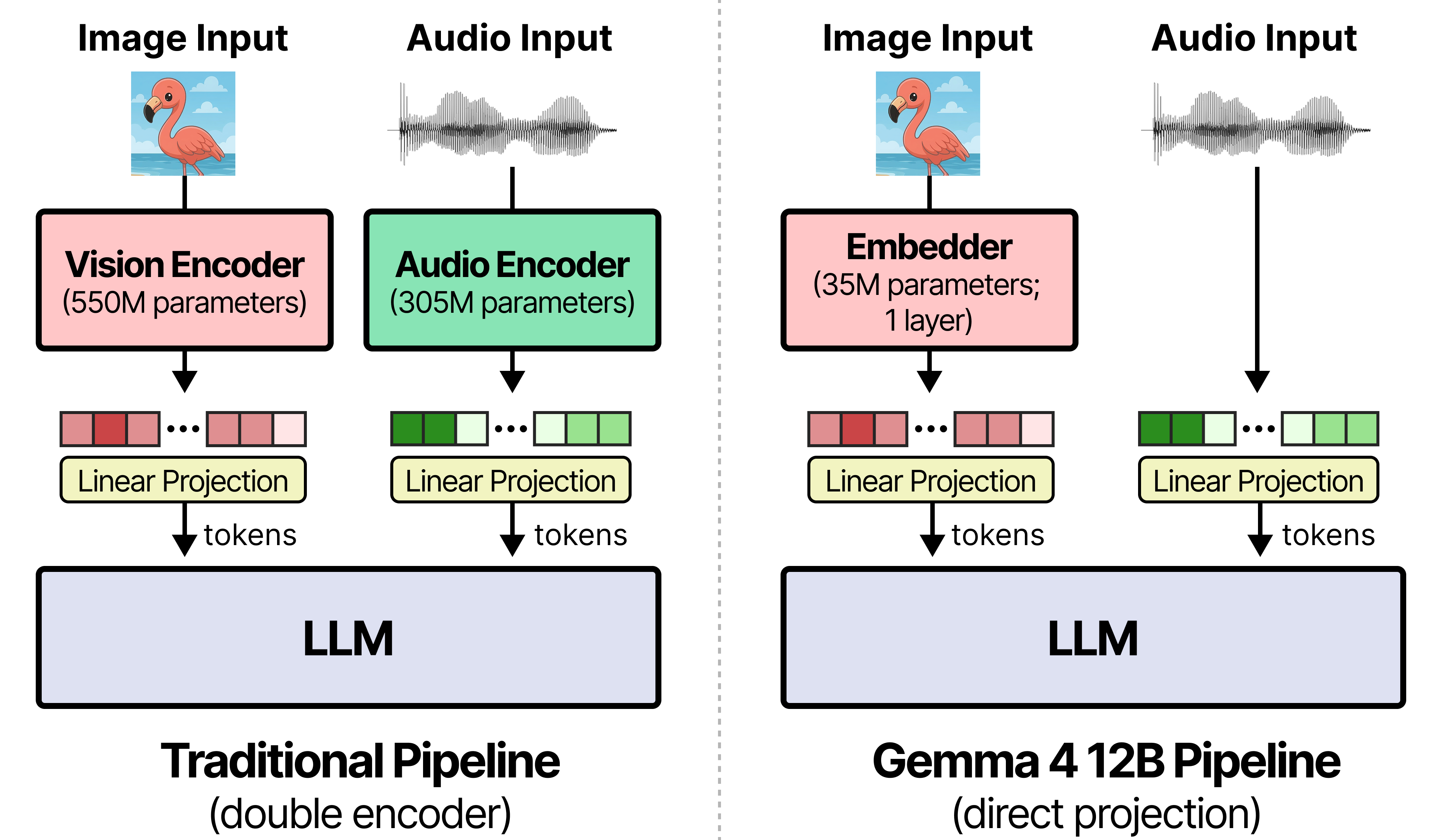
Gemma 4 12B采用无编码器多模态架构,可在16GB显存设备上本地运行并原生支持音频输入。该模型通过移除独立视觉与音频编码器显著降低延迟,配合专用MTP模型提升推理速度,是首个支持macOS桌面端全离线交互的中型多模态模型。
入选理由:Gemma 4 12B移除独立编码器,视觉仅用35M参数嵌入层,音频直接线性投影至LLM输入空间
精选文章#Gemma 4#多模态大模型#无编码器架构#本地AI#Google英文










![[AINews] Thinky's Inkling: 975B-A41B multimodal, new best American Apache 2.0 open model (with Inkling-Small, 276B-A12B)](https://substackcdn.com/image/fetch/$s_!AvrX!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F90048da3-a87f-44d8-8ad4-e954031d2721_2540x1692.png)
