How to Use Prompt Engineering and Context Engineering for AI Agents
freeCodeCamp.org2270 字 (约 10 分钟)
85
提示工程和上下文工程能显著提升AI代理性能,通过优化输入和上下文信息。
入选理由:使用LangChain v1和Ollama可本地运行AI代理,避免API成本
精选文章#AI代理#提示工程#LangChain#Ollama英文
产品
也叫:@ollama
本地运行大型语言模型的工具
最近变化
2026-07-24 · 使用LangChain v1和Ollama可本地运行AI代理,避免API成本
Ollama 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
已收录 30 篇与「Ollama」相关的 AI 资讯和分析。
提示工程和上下文工程能显著提升AI代理性能,通过优化输入和上下文信息。
入选理由:使用LangChain v1和Ollama可本地运行AI代理,避免API成本
开源模型已具备代理应用能力,但API兼容性不足成为生产环境瓶颈,Mozilla提出开源网关Otari解决该问题。
入选理由:开源模型推理能力已满足代理产品需求,但API兼容性仅支持基础聊天功能
本文提供本地化AI代理评估框架,结合LLM作为裁判与规则检查,使用LangChain、Ollama等工具实现零API成本测试。
入选理由:使用LLM-as-a-judge与规则检查双重机制评估AI代理输出
使用Ollama可在15分钟内本地运行AI模型,无需复杂配置。该工具通过量化技术降低硬件要求,支持跨平台部署。
入选理由:Ollama提供三步安装流程:安装、下载模型、启动聊天
本文详解使用Python和LangGraph构建多智能体AI系统,对比框架与无框架实现的差异,强调本地运行的低成本优势。
入选理由:LangGraph通过节点边实现工作流管理,降低多智能体系统开发复杂度
本地运行LLM成本可能低于云服务,Gemma26B模型每百万令牌仅需0.12欧元,但大模型能耗差异显著。
入选理由:Gemma26B模型本地运行成本0.12欧元/百万令牌,低于多数云API
开源模型将主导未来AI算力消耗,Ollama团队预测超多数token将来自开源模型,但大公司仍因计算资源垄断保持优势。
入选理由:未来超80%的AI算力消耗将来自开源模型(Ollama预测)
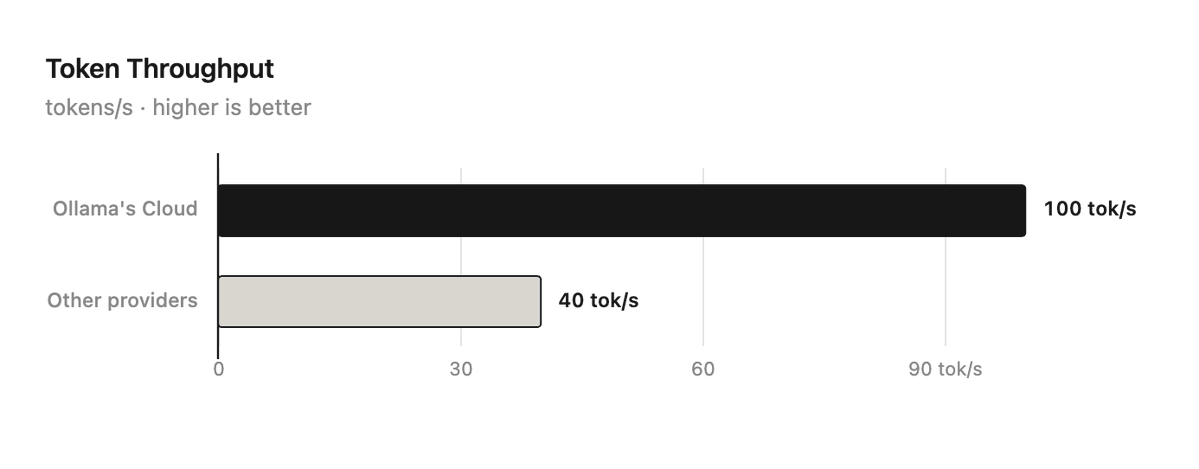
Ollama云服务在GLM-5.2模型上实现每秒80-120输出令牌,显著优于其他提供商的30-40 tok/s。
入选理由:Ollama云服务GLM-5.2输出速度达80-120 tok/s,是其他服务商的2-3倍
自动化数据科学流程的5种代理工作流可节省45%时间,Databricks已集成相关功能,核心依赖ReAct循环与LLM工具。
入选理由:数据科学家45%时间消耗在数据清洗,代理可自动化处理
本文展示如何使用 Ollama 和 Qwen 构建一个本地运行的 AI 网络研究代理,实现无 API 成本、隐私保护的网页信息检索与总结。
入选理由:使用 Ollama 和 Qwen 可构建本地运行的 AI 研究代理,无需 API 成本。
未来AI将主导多数任务,但六项核心技能仍具价值,包括管理AI代理、本地模型运行等。
入选理由:管理AI代理和本地模型运行是未来高价值技能。
Codex 推出 Record & Replay 功能,可录制用户操作并转化为可复用的技能,提升 AI 在图形界面操作中的自动化能力。
入选理由:Codex 的 Record & Replay 功能可将用户操作转化为可复用的技能,适用于重复性高、依赖隐性规则的任务。
开源模型在性能和成本上显著优于闭源模型,成为AI领域的优选。
入选理由:GLM 5.2 比 Opus 4.8 快且更高效,成本低 6 倍以上。
GLM-5.2 是目前最强的开源编码模型,支持 1M-token 上下文和代理任务,已在 Ollama 云平台上线。
入选理由:GLM-5.2 支持 1M-token 上下文,适用于长周期编码任务。
Ollama 0.32.1显著提升Gemma 4工具调用可靠性,支持高效运行26B模型。
入选理由:Ollama 0.32.1版本优化了Gemma 4的工具调用稳定性,特别针对编码代理场景
Ornith-1.0 是一个开源的大型语言模型系列,专为代理式编程设计,包含多种参数规模的模型。
入选理由:Ornith-1.0 包含 9B Dense、31B Dense、35B MoE 和 397B MoE 四种参数规模的模型。
Fortune 500公司转向开源AI模型以降低成本并增强数据控制,但缺乏技术细节和实证数据支撑。
入选理由:开源模型可降低企业30%的AI部署成本(推测数据)
Ollama宣布Gemma 4模型在MLX平台实现多令牌预测优化,但推文内容未展开技术细节。
入选理由:Gemma 4模型在MLX平台实现多令牌预测优化
文章讨论了开源权重AI模型的最新进展,但信息密度较低,缺乏具体技术细节。
入选理由:开源权重AI模型在特定任务上表现优异。
Ollama 云平台通过增加 NVIDIA B300 Blackwell GPU 容量,提升 GLM 5.2 模型的处理能力,但内容信息密度较低。
入选理由:Ollama 云平台使用 NVIDIA B300 Blackwell GPU。
文章介绍了在Jetson设备上使用不同框架(如Ollama、llama.cpp、vLLM)部署开源生成AI模型的方法,但内容以视频链接和导航元素为主,缺乏深度技术细节。
入选理由:文章提到Ollama、llama.cpp、vLLM三种框架可用于Jetson设备上的GenAI模型部署。
Ollama推文称85%的财富500强企业已使用其开放模型,但缺乏技术细节和可信数据支撑。
入选理由:Ollama声称85%的财富500企业使用其模型(需验证数据真实性)
OpenCode Desktop 现支持 Ollama 集成,但信息量有限,未提供技术细节或使用场景说明。
入选理由:OpenCode Desktop 新增基于标签的会话管理功能
推特动态提及Ollama融资及开放模型趋势,但缺乏技术细节与深度分析。
入选理由:Ollama完成B轮融资
该推文仅包含直播链接和社交媒体互动信息,缺乏实质性技术内容。
入选理由:推文内容为直播预告,无技术深度
文章内容为 Ollama 官方推文,主要展示其模型页面链接,信息量有限,缺乏技术深度。
入选理由:文章仅提供模型页面链接,未深入介绍技术细节。
Cohere 宣布 North Mini Code 模型现已支持 Ollama,可在本地运行并与其他模型如 Codex、OpenClaw 集成。
入选理由:North Mini Code 现在可以在 Ollama 平台上本地运行。
文章宣传了支持本地运行模型的工具,并提及多个模型和链接,但信息密度低,缺乏深度技术内容。
入选理由:North Mini Code 现在支持本地运行模型。
Ollama 宣布支持 GLM-5.2 和 Kimi-K2.7-Code 模型在 Codex 中使用,但信息密度低,缺乏技术深度。
入选理由:Ollama 支持 GLM-5.2 和 Kimi-K2.7-Code 模型在 Codex 中使用。
文章内容为推文链接,未提供实质性技术信息。
入选理由:文章未提供具体技术内容或深度分析。
与「Ollama」经常一起出现的 AI 术语。
💡 想追踪「Ollama」的长期趋势?去 实体雷达 · Ollama 查看详细分析和跨材料问答。