How Trustpilot built a real-time architecture for data enrichment using Gemma
Google Cloud Blog992 字 (约 4 分钟)
92
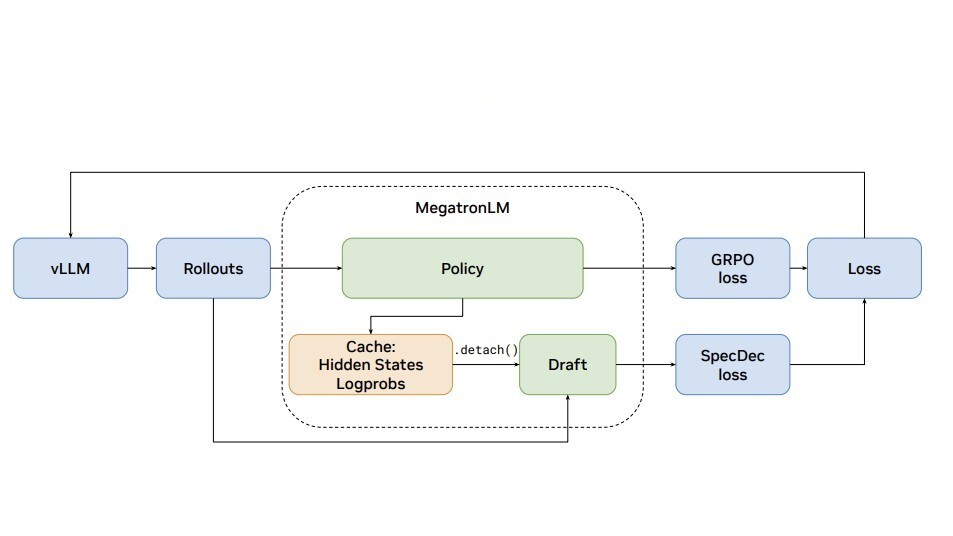
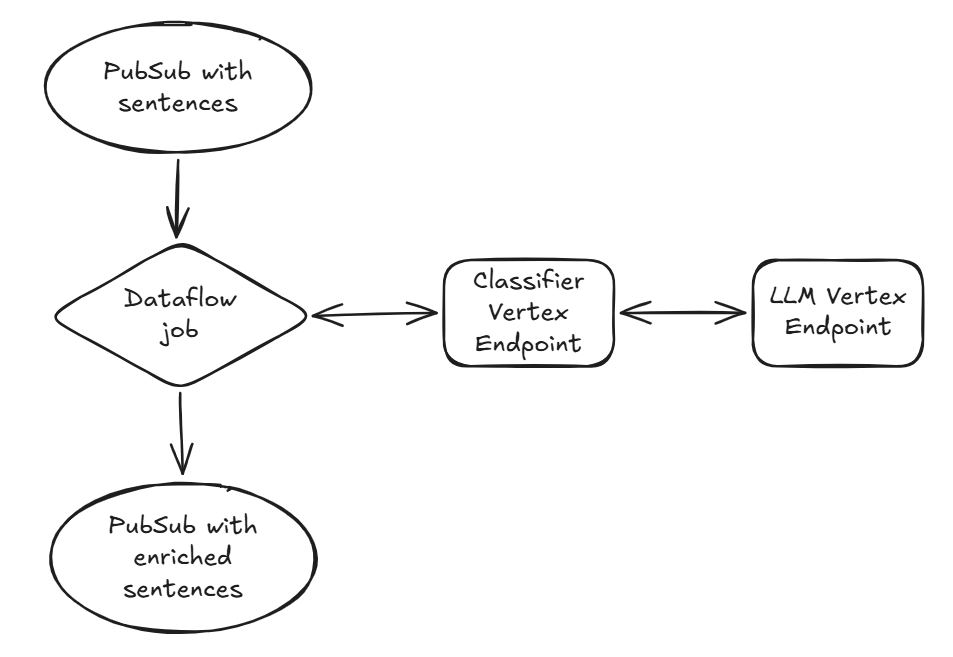
Trustpilot built a real-time data enrichment pipeline using fine-tuned Gemma models to process millions of reviews under strict latency and cost constraints, achieving near-teacher-model accuracy with full control.
入选理由:采用 google/gemma-2-9b 基础模型,通过共识标注生成高质量训练集,微调后准确率仅比教师模型低几个百分点。
FeaturedArticle#Gemma#Dataflow#LLM#Real-time Architecture#Fine-tuning英文








![[AINews] Cognition raises $1B in $26B Series D](https://substackcdn.com/image/fetch/$s_!l_fo!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fc283a27b-c506-4ee9-8b9a-47650b429a01_2534x1694.png)