[AINews] Cognition完成10亿美元D轮融资,估值达260亿美元
![[AINews] Cognition完成10亿美元D轮融资,估值达260亿美元](/api/img-proxy?url=https%3A%2F%2Fsubstackcdn.com%2Fimage%2Ffetch%2F%24s_!l_fo!%2Cw_1456%2Cc_limit%2Cf_auto%2Cq_auto%3Agood%2Cfl_progressive%3Asteep%2Fhttps%253A%252F%252Fsubstack-post-media.s3.amazonaws.com%252Fpublic%252Fimages%252Fc283a27b-c506-4ee9-8b9a-47650b429a01_2534x1694.png)
TL;DR · AI 摘要
Cognition以260亿美元估值完成10亿美元D轮融资,成为最大独立AI智能体实验室;ARR预计年底超10亿美元;推理优化转向架构级改进,EAGLE 3.1、vLLM等显著提升长上下文稳定性与吞吐效率。
核心要点
- Cognition D轮募资10亿美元,估值260亿美元,较8个月前增长2.5倍
- EAGLE 3.1稳定隐藏状态反馈,vLLM分词器CPU占用降5–6倍,延迟低至63微秒
- DeepSeek V4-Pro用压缩稀疏注意力使1M-token KV缓存降至V3.2的10%,FLOPs降73%
结构提纲
按章节快速跳转。
Cognition以260亿美元估值完成10亿美元D轮融资, 较8个月前Series C估值增长2.5倍, 成为最大独立AI智能体实验室。
公司披露ARR预计2026年底超10亿美元, 并获得Exa、Modal等高门槛企业客户背书, 验证产品实际落地能力。
推理优化重心从内核层转向架构设计,EAGLE 3.1、vLLM、Qwen3.5等通过隐藏状态稳定、零堆分配、联合优化实现吞吐与延迟突破。
DeepSeek V4-Pro和Xiaomi MiMo通过压缩稀疏注意力与分层缓存管理, 将1M-token KV缓存成本降至原10%, 缓存开销降低约80%。
MaxSim v2在H200上比原生PyTorch快10.33倍, A100上快11.94倍, 显著加速训练与推理中的相似度计算。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- Cognition融资与AI推理架构演进(2026.05)
- Cognition融资动态
- D轮$1B,估值$26B
- ARR >$1B(EOY 2026)
- 最大独立Agent实验室
- 推理效率突破
- EAGLE 3.1:长上下文稳定性提升
- vLLM + Unigram:CPU降5–6×,63µs@514t
- Qwen3.5 + TokenSpeed:580 tok/s(agentic)
- 成本结构优化
- DeepSeek V4-Pro:KV缓存↓90%,FLOPs↓73%
- MiMo:缓存容量↑5×,成本↓80%
- MaxSim v2:H200快10.33×
金句 / Highlights
值得收藏与分享的关键句。
Cognition估值达260亿美元,较8个月前Series C增长2.5倍,成为当前最大独立Agent实验室。
Perplexity开源的Unigram分词器将CPU利用率降低5–6倍,在514 tokens下延迟仅63微秒且零堆分配。
DeepSeek V4-Pro使用混合注意力,1M-token KV缓存降至V3.2的10%,单token推理FLOPs降至27%,仍激活49B参数(总1.6T)。
MaxSim v2在H200上比原生PyTorch快10.33倍,A100上快11.94倍,支持反向传播并显著加速相似度计算。
我们上一次报道认知实验室是在九月份的100亿美元C轮融资,当时Smol.ai也加入了认知实验室,而AINews最终被迁移到潜空间。八个月后,该实验室估值已增长2.5倍,正式成为AI领域最大的独立智能体实验室,这正是我们去年提出的核心论点。随着官方ARR(年度经常性收入)披露(目前预计到年底将超过10亿美元),我们可以看到其增长轨迹与2025年发生了什么图表惊人相似(这并非偶然):
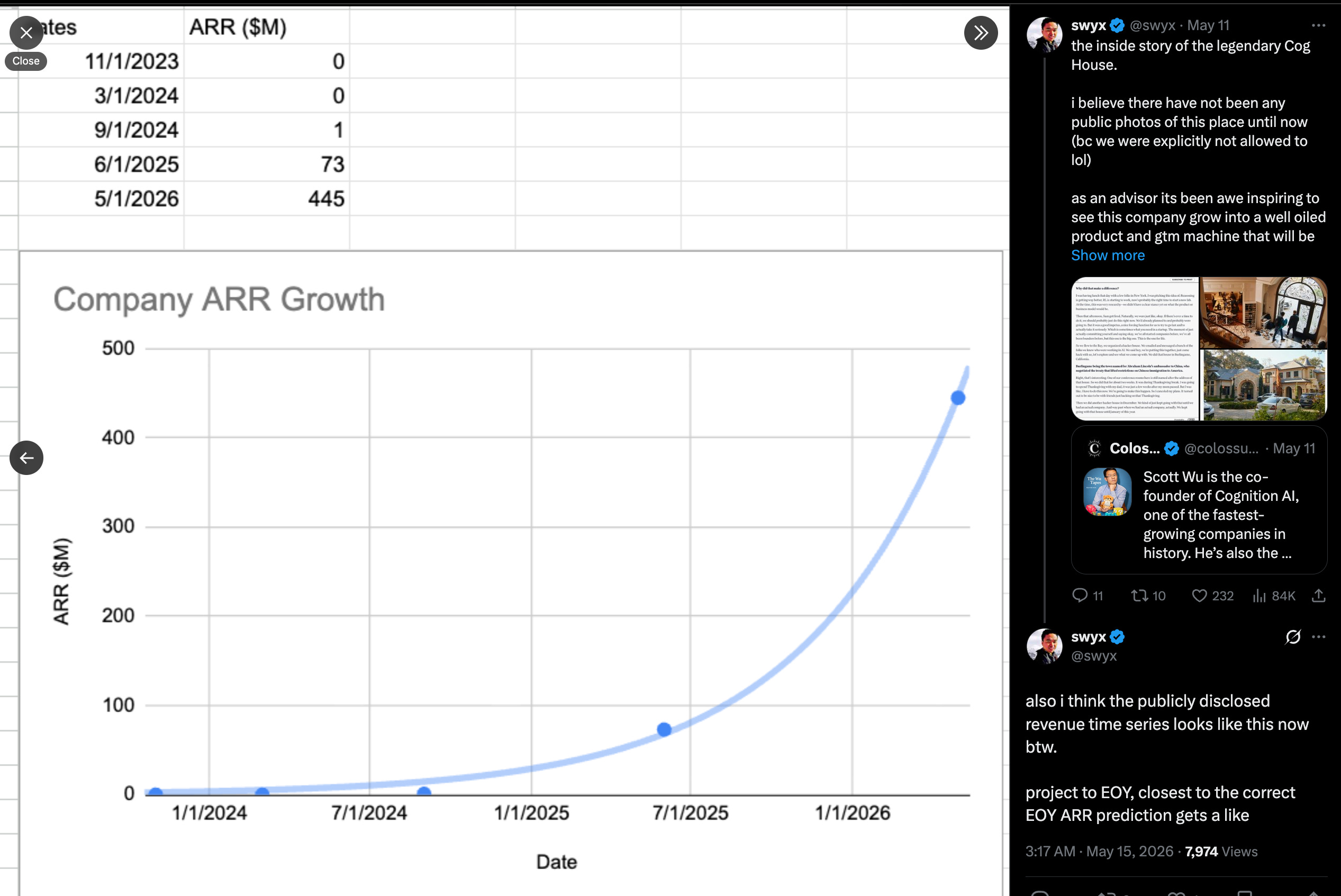
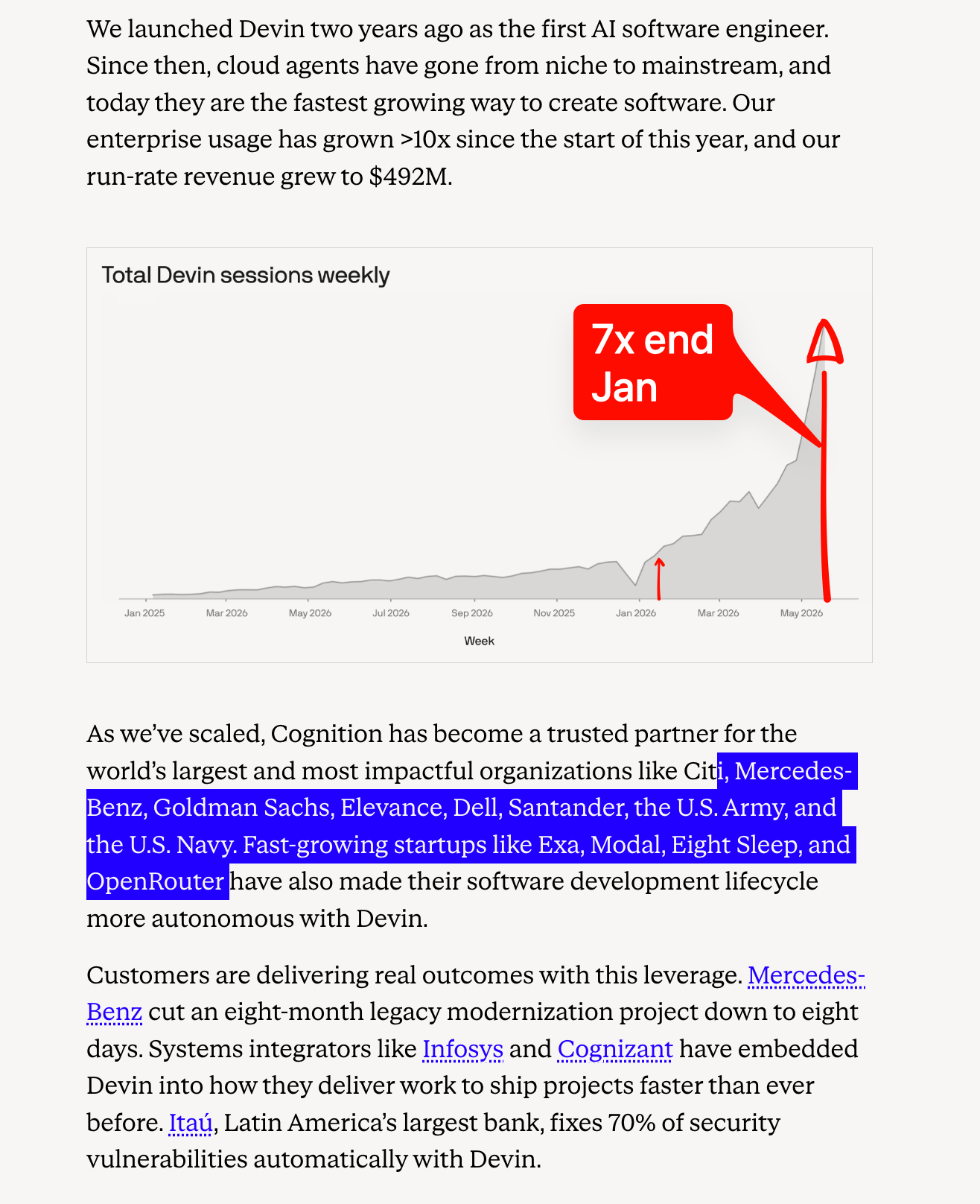
在企业SaaS业务中,ARR是滞后指标,反映了客户使用率,而一些最严苛/最具鉴别力的企业和初创生态系统客户的标志(包括上周报道的Exa和Modal)同样印证了这一点:
明天将在认知播客发布更多信息。
AI新闻2026年5月26日至5月27日。我们监测了12个子版块、544个推特账号和无Discord频道。AINews网站可搜索所有往期内容。提醒:AINews现为潜空间的一个版块。您可订阅/退订邮件推送频率!
推理效率、服务架构与成本曲线
- 推理优化正变得更具体系化,而非仅限于内核级:EAGLE 3.1通过稳定隐藏状态反馈和减少深层解码步骤中的注意力漂移,提升了推测式解码的鲁棒性,特别强调长上下文接受长度和现实世界服务可靠性;团队还提到与vLLM和TorchSpec的合作。在内核/系统层,Perplexity开源了重建的Unigram分词器,使CPU利用率降低5-6倍,处理514个标记时达到63微秒且零堆分配;通义千问3.5在TokenSpeed上的表现则通过阿里巴巴、LightSeek、NVIDIA、Mooncake和FlashAttention-4贡献者的联合优化,在代理工作负载中实现每秒580个标记。支持库也得到改进:MaxSim v2新增反向传播功能,在H200上提速10.33倍,在A100上提速11.94倍,远超原始PyTorch性能。
- 价格下调由结构性键值缓存和注意力机制变革支撑:多篇分析指出,中国实验室近期的API降价具有可持续性,因为它们反映了单标记服务成本下降,而非临时补贴。@kimmonismus总结了DeepSeek V4-Pro如何通过混合注意力机制(压缩稀疏注意力和高度压缩注意力)将100万标记的键值缓存容量降至V3.2版本的10%,单标记推理FLOPs减少至27%,同时仍能调用1.6万亿参数中的490亿活跃参数。小米的MiMo则通过SWA(滑动窗口聚合)和分层缓存管理减少缓存流量。@_LuoFuli证实,MiMo最深输入缓存命中带来的价格降幅源于5倍缓存容量提升、约80%的缓存成本降低,以及1:7全连接:SWA稀疏度比。总体结论:长上下文推理经济性正由注意力设计+缓存层次+路由策略共同推动,而不仅仅是硬件成本下降。
智能体、框架、记忆与持续学习
- 堆栈正在从“模型质量”转向“模型-框架-内存适配”:大量推文聚焦于实用代理工程实践。LangChain 发布了 Deep Agents v0.6,引入 Delta Channels 技术,将 200 轮编码会话的检查点存储需求从 5.3 GB 压缩至 129 MB,并推出了 Fleet 中的计算机使用功能 和 Context Hub(用于版本化代理上下文/技能)。LangSmith Engine 被定位为自动化评估→诊断→修复循环,多位从业者强调其价值在于将追踪反馈转化为可复用的在线/离线评估器。与此同时,@Vtrivedy10 提出了当日最清晰的观点:任务-框架适配与模型质量同等重要,定制化垂直系统通过缩小工具、提示和上下文范围,性能优于通用框架。
- 持续学习正重新成为产品类别,而不仅仅是研究课题:最大亮点是 Trajectory 的发布:一个利用 产品使用信号和代理追踪数据 对大型智能体模型进行持续后训练的平台,获得 1500 万美元融资,设计合作伙伴包括 Clay、Harvey、Decagon、Mercor 和 Rogo。Baseten 表示支持此类部署,提供 FP8/NVFP4 量化和自动扩展 H100 基础设施,其中包括一夜之间部署 3970 亿参数模型 的案例。开源工具方面,基于 LangChain/LangGraph 构建的 内存中心型代理 因明确分离检索/存储/推理/学习模块而受到开发者称赞;RLM 的极简训练框架 展示小型团队如今可在 8×A100 GPU 上一天内完成长上下文代理的强化学习调优。核心趋势是:“部署后学习”正从愿景变为基础设施。
基准测试、扩展定律与训练方法
- 新基准测试越来越关注长期、复杂、真实世界的流程:DeepSWE 被列为软件工程师/代理基准,包含 跨 5 种语言的 91 个仓库中的 113 项任务,采用极简主义 bash-only 框架和较短提示,但要求生成的代码量比 SWE-Bench Pro 多 5.5 倍,平均涉及 7 个文件。在企业运维领域,Artificial Analysis 和 IBM 推出 ITBench-AA,这是一个针对 Kubernetes 事件响应的 SRE 基准测试,所有前沿模型得分均低于 50%;Claude Opus 4.7 领先(47%),GPT-5.5 紧随其后(46%),GLM-5.1 Reasoning 在开源权重中表现最佳(40%)。另一个可靠性视角来自 AgingBench,该基准将部署代理的性能退化视为生命周期问题,归因于压缩、干扰和内存更新的影响。
- 训练效率研究在理论和系统层面持续活跃:Sakana AI 的 DiffusionBlocks 是最具技术突破性的成果之一:它将前向传播重新解释为扩散式去噪步骤,使深度网络能够 逐块训练,显著降低内存消耗,同时在 ViT、DiT、掩码扩散、自回归变换器和递归深度变换器 等架构上保持端到端性能。在强化学习系统方面,Snowflake 推出 ZoRRo,声称通过消除冗余回滚计算,实现 长达 3.2 倍的上下文窗口 和 最高 3.5 倍的长上下文 RL 加速,并发布了面向企业的专用 Arctic-Text2SQL-R2 SQL 模型。理论研究方面,Tiberiu Musat 的预印本 认为,在固定精度网络中,最小神经权重范数与最小程序长度在对数因子范围内匹配;Unified Neural Scaling Law 则提出多变量函数形式,旨在更准确地外推神经网络扩展行为,超越现有拟合方法。
模型与模态发布:生物学、视觉、OCR 及嵌入式 AI
- 蛋白质建模迎来高光时刻:ESMFold2 被宣布为开放科学引擎,用于蛋白质结构预测与设计,在 蛋白质相互作用和抗体 方面取得显著成果,并附带 68 亿蛋白质图谱 和 11 亿预测结构 数据集。该发布强调了实际应用成果——针对五个治疗靶点的迷你蛋白结合剂和单链抗体——以及关于新兴蛋白质表示的机制可解释性发现。这一成果得到 @proteinrosh 和 @cgeorgiaw 的呼应,后者指出其图谱规模已超过 AlphaFold 数据库。
- 一波规模较小但实用的多模态/开源发布落地:Google DeepMind 发布了 Gemini Embedding 2 的白皮书,该模型被描述为支持文本、图像、音频和视频统一表示的原生多模态嵌入模型。NVIDIA 的 LocateAnything 结合了 Qwen2.5-3B + Moon-ViT,实现高速定位任务,声称在密集目标检测中速度提升 10×。Hugging Face 集成了 Roboflow 的 RF-DETR,将其定位为实时检测/分割系统,性能优于 YOLO 类型架构。文档处理方面,Surya OCR 2 是一个 6.5亿参数 模型,达到 OLMOCR 基准83.3%、内部91种语言基准87%,并在 RTX 5090 上实现 每秒5页 处理速度;LiteParse v2 用 Rust 重写解析器,实现 最高100×加速,并通过 WASM 支持边缘/浏览器部署。设备端 AI 方面,Google 推出新 Coral 开发板,用于本地语音、视觉和控制演示。
开发者平台、企业级控制与编码代理产品化
- 编码代理正整合为企业级全栈产品:OpenAI 继续收紧 Codex 的产品线:GPT-5.2 和 GPT-5.3-Codex 将被 GPT-5.5 取代,同时新增企业功能包括 仅限外网 HTTPS 的私有 MCP 连接、工作负载身份联合认证 和扩展的 Admin API 控制(如支出警报、允许列表、保留策略及托管工具管理)。OpenAI 还发布了使用 Codex 构建自改进税务代理的具体案例研究,重点展示如何将评审修正反馈回评估和修复流程。
- 编码代理竞争聚焦可靠性、工作流广度与企业采用:Claude Code 更新了可靠性和性能指标,并简化了 bug 报告流程;GitHub 则通过 Copilot Dev Days 和 MCP 定位 加速“代理化 IDE”方向。最大商业信号来自 Cognition:以260亿美元估值筹集超过10亿美元资金,年营收达4.92亿美元,企业客户年度增长超10倍,并获得 Exa 等用户的积极背书。其他基础设施/产品动态显示生态扩展:Cua Driver for Windows 将后台计算引入 Windows 代理;Cloudflare 的代理平台因“分时计算”经济性获好评;Grok Build 的 worktree 支持则瞄准仓库级多代理代码协作。
高互动推文精选
- Cognition 规模扩张:Cognition 公布 超10亿美元融资、260亿美元估值 和 4.92亿美元年营收,成为编码代理向大型企业业务转型的明确信号。
- Claude Code 可靠性强化:Anthropic 的 ClaudeDevs 发布响应速度、可靠性优化及反馈收集机制升级,表明产品质量与信任已成为核心竞争领域。
- Sakana AI 的 DiffusionBlocks:@hardmaru 展示块状训练方法,可在大幅降低内存需求的同时匹配端到端扩散模型性能。
- ESMFold2 发布:@alexrives 推出当日最具影响力的科学成果之一——开源蛋白质建模工具 ESMFold2,具备治疗设计潜力。
- OpenAI 企业级控制 + MCP:@OpenAIDevs 关于私有 MCP 和安全/管理功能的更新,反映前沿 API 在争夺大型组织采用方面的竞争焦点。
- PrismML 发布 Binary/Ternary Bonsai Image 4B:PrismML 推出 1-bit/三值量化 文本到图像扩散变换器变体,模型大小约 3GB,Apache-2.0 许可,支持 WebGPU 浏览器运行(HF 集合、演示)。与 FLUX.2 Klein 4B(约16GB)对比,评论区指出其本质为量化/微调版本,未充分标注原始模型来源。争议集中在品牌归属:有评论认为 PrismML 重新包装量化模型作为“Bonsai”系列,类似将 Qwen 量化版标榜为新模型。
- 一位评论者声称PrismML的“Bonsai-Image”并非重新训练的基础模型,而是对
FLUX.2 Klein 4B进行二值/三值量化并附加后训练以恢复质量的结果。他们指出该项目的Hugging Face演示页面/模型页面和GitHub仓库未明确标注原始FLUX模型/团队的贡献,仅在白皮书中提及原始模型。
- 技术可用性说明指出浏览器/WebGPU版本的模型需要下载约
~2 GB,这与1位元/三值压缩声明形成对比,但对纯本地推理仍具相关性。另一用户询问该模型是否能在16 GB RAM CPU上运行,但讨论中未提供具体基准测试或兼容性答案。
- [受够了4GB GPU的内存溢出问题。用Rust编写自定义裸机引擎,在RTX 3050上实现4B模型(BitNet 1.58b)66.8 TPS](https://www.reddit.com/r/LocalLLM/comments/1to6enj/got_tired_of_oom_errors_on_my_4gb_gpu_wrote_a/)(活跃度:390):作者声称自研Rust/C++大语言模型推理引擎Cluaiz可运行
prism-ml/Bonsai-4B-gguf模型,通过1.58-bit量化在4GB RTX 3050上达到66.8 token/s,并报告通过动态KV缓存管理使Gemma/Qwen 4B变体在不发生OOM的情况下实现~30–33 TPS。帖子尚未提供可复现的代码库或基准测试工件;评论者指出了项目链接(GitHub、官网),质疑模糊表述如“直接访问硅片级硬件”,认为这可能仅指提前编译生成本地代码而非特殊GPU驱动机制。附带的Reddit视频因HTTP 403限制无法独立验证。顶级评论强烈质疑,认为文档和代码库语言具有伪技术性/AI生成特征,声称的成果实质仅为基本本地编译加单机演示。评论者还挑战了Apache 2.0许可下的版权措辞,并要求披露所谓低级硬件访问的具体实现细节。
- 评论者质疑关联代码库(github.com/cluaiz/cluaiz、cluaiz.com)的技术主张,认为“直接访问硅片级硬件”“裸机引擎”“Apache许可的版权软件”等表述属于营销话术或LLM生成的伪技术语言。有评论者询问“直接访问硅片级硬件”是否仅指Rust的提前本地编译,而非超出常规CUDA/驱动API的底层GPU编程。
- 多位评论者认为,宣称的成果应与现有工具(如llama.cpp)对比,后者已支持消费级GPU上的低内存推理和量化模型。批评观点指出,4GB RTX 3050的OOM问题通常可通过合理配置llama.cpp解决,无需开发新引擎,因此需提供可复现的基准测试和配置详情才能证明66.8 TPS(4B BitNet 1.58b模型)的实际意义。
- [Qwen3.5 35B A3B非审查版异端Native MTP Preserved发布,包含完整785个MTP张量,支持Safetensors、GGUF、NVFP4、NVFP4 GGUF及GPTQ-Int4格式](https://www.reddit.com/r/LocalLLaMA/comments/1tnzalm/qwen35_35b_a3b_uncensored_heretic_native_mtp/)(活跃度:602):llmfan46发布了
Qwen3.5-35B-A3B-uncensored-heretic-v2-Native-MTP-Preserved,这是基于Qwen/Qwen3.5-35B-A3B使用Heretic v1.3.0/Magnitude-Preserving Orthogonal Ablation方法修改的非审查版本,针对attn.o_proj、attn.out_proj和mlp.down_proj模块进行编辑,同时保留全部785个原生MTP张量。模型卡显示拒绝率从92/100降至14/100,KL散度0.0487(相对于基线),MMLU分数在7,021道题中仅从84.12%微降至83.72%;发布版本包括Safetensors、GGUF、NVFP4、NVFP4 GGUF和GPTQ-Int4格式。作者指出Qwen3.5和Qwen3.6均采用qwen35架构,但分别针对通用辅助(3.5)和代理/编码任务(3.6)调优,强调不同家族间消融KL/质量行为存在显著差异。评论者赞赏了NVFP4 GGUF版本的罕见性,有人表示:“我实在找不到其他类似发布,甚至Unsloth也没有。” 另一测试者认同作者的观点,认为Qwen3.6更接近“3.5 coder+”而非全面升级版。
- 一位评论者强调NVFP4 GGUF构建的实际价值,指出该格式难以在其他地方找到:“我实在找不到其他人做这个,连Unsloth都没有。” 这对目标NVIDIA平台低精度推理流程的用户具有技术意义,因其依赖GGUF运行时。
- 测试者比较Qwen3.5与Qwen3.6,认为3.6更像是“3.5 coder+”而非简单升级。他们推测短时间内连续发布不太可能带来广泛能力飞跃,暗示3.6可能更专注于编码领域而非作为3.5的全面继任者。
- [Okay 27B made me a believer](https://www.reddit.com/r/LocalLLaMA/comments/1to73op/okay_27b_made_me_a_believer/) (活跃度:541):原帖作者报告称,通过Opencode调用的Qwen家族`27B`模型仅凭三份参考文件(描述控制台API、手柄控制和TypeScript着色器)一次性生成了一个近乎完整的HTML5 Breakout风格游戏。输出结果可立即运行,包含完整控制、音效、元数据,并集成了存档/状态/心跳API,仅需一次后续定制和一个漏洞修复;一位评论者建议启用MTP/推测性解码并设置2-3个草稿标记以提升速度。另一位重度用户指出该模型在64K以下上下文表现最佳,超过64K后性能明显下降,超过128K后“显著恶化”,推荐对长期代理编码任务进行定期文件摘要和会话重置。 评论者认为密集型
27B在本地编码方面异常强大——单次生成Web应用时接近Sonnet级别性能——但有用户发现35B A3B尽管具备规模/路由优势却能力较弱。主要警告是长时间上下文代理运行可能导致循环或“愚蠢行为”,因此用户需积极管理上下文。
- 一位评论者建议启用多令牌预测/推测性解码以提高吞吐量,推荐使用2或3作为实际的速度/质量折中值。这是部署级优化而非模型质量声明,适用于本地运行27B模型的用户。
- 一名用户报告称,27B模型的有效推理质量随上下文长度显著下降:64K以下最佳,超过64K后性能下降,超过128K后“显著恶化”。他们针对长期代理任务的解决方案是定期将状态摘要到文件,重启框架/会话并重新加载摘要,以恢复模型质量和避免循环。
- 一位基准测试人员表示,Qwen 27B的表现如此突出以至于他们复核了方法论,在排名中将其定位于与GPT-5.2或Sonnet 4.5相当,同时指出其在大上下文场景下存在局限性,这可能是由于参数量限制所致。他们提供了数据链接:gertlabs.com/rankings。