最近深度使用了一下 Kimi 3,所以对这个模型的真实编程能力有一定的发言权,正好有做一个录屏软件的需求,之前也说过市面上现在有很多,但是我想按照我的需求深度自定义一个,用来测试一下 Kimi3 的实...
Viking(@vikingmute)516 字 (约 3 分钟)
85
Kimi3在复杂录屏软件开发中展现接近Opus 5.5的编程能力,支持多代理并行处理和1M上下文长度。
入选理由:Kimi3可同时处理5-6小时的多代理并行任务,上下文长度达1M
FeaturedTweet#Kimi3#AI编程#React#Rust#模型对比中英混合

![[AINews] SpaceXAI launches Grok 4.5, first Opus-class model post Cursor acquisition](https://substackcdn.com/image/fetch/$s_!beuF!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F3dad0acc-e1ba-4ce4-9196-4ea6e56633a0_1628x1726.png)





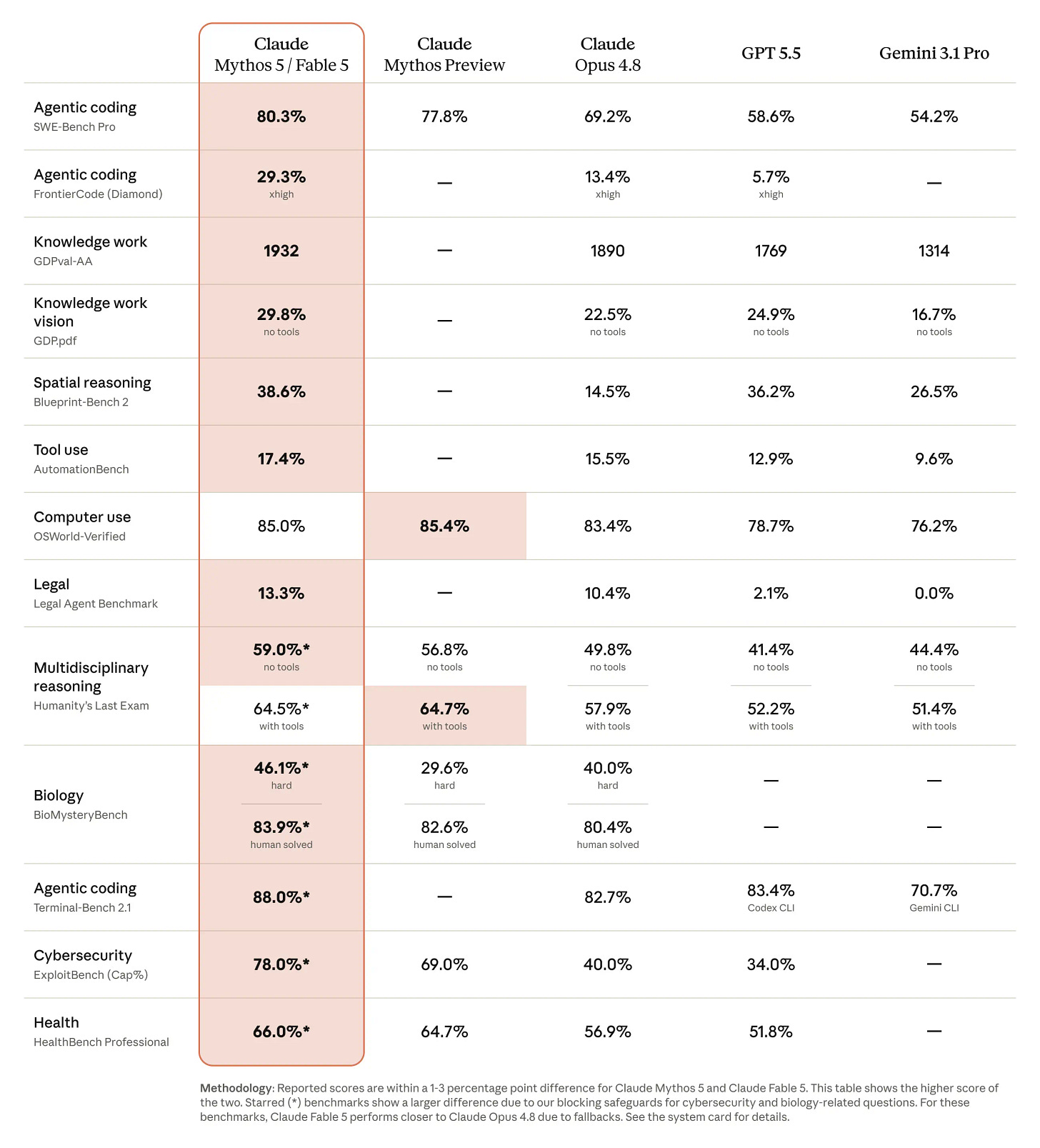
![[AINews] Anthropic Claude Fable 5 — Mythos but Safe, with Controversial Terms](https://substackcdn.com/image/fetch/$s_!TXW4!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F7af8f73c-7a20-4f7e-ac83-a05cbc892d8b_2318x1684.png)













