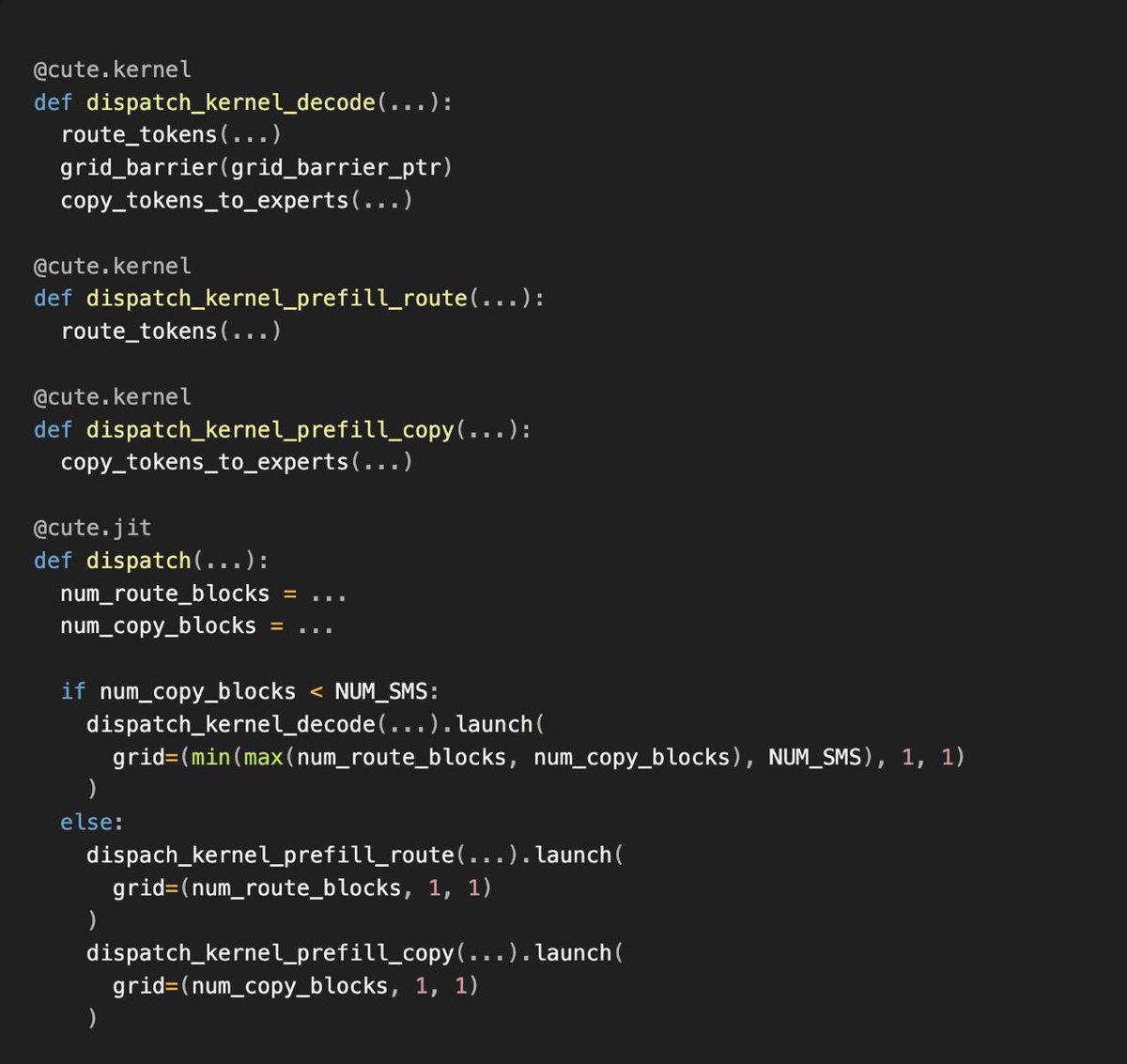
We’ve developed our own inference engine ROSE
Perplexity(@perplexity_ai)302 字 (约 2 分钟)
65
Perplexity has launched its in-house inference engine ROSE, enabling efficient serving from embedding models to trillion-parameter LLMs, with CuTeDSL integration for faster GPU kernel customization.
入选理由:Perplexity 自主研发了推理引擎 ROSE,提升大模型服务效率。
FeaturedTweet#ROSE#CuTeDSL#GPU optimization#large model inference#Perplexity英文