
Grok just broke the trend
Matthew Berman154 字 (约 1 分钟)
85
Grok 4.5在编码基准测试中以83.3分超越Opus 4.8,Cursor公司正基于600亿美元收购数据训练下一代模型。
入选理由:Grok 4.5在编码基准测试中得分83.3,领先Opus 4.8五分
FeaturedVideo#Grok#Cursor#AI模型#编码基准英文
模型
别名:Opus 4.8
Grok 4.5的竞争对手模型
已跟踪 30 条高相关材料
最近变化
2026-07-11 · 文章内容无法访问,无法评估技术价值
为什么值得关注
Opus 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
[AINews] SpaceXAI launches Grok 4.5, first Opus-class model post Cursor acquisition
Latent Space · 8.5 分
SpaceXAI发布Grok 4.5,首个Cursor合作训练的Opus级模型,性能接近Opus但成本效率提升,专注编码与代理场景。
Grok just broke the trend
Matthew Berman · 8.5 分
Grok 4.5在编码基准测试中以83.3分超越Opus 4.8,Cursor公司正基于600亿美元收购数据训练下一代模型。
Claude Fable 5 马上要从订阅计划里消失了,怎么把它的大脑提纯出来一直用? @EXM7777 总结出一个统一筛选标准 + 五个具体动作! # 唯一筛选标准:可重做性测试 一句话判断:...
meng shao(@shao__meng) · 8.5 分
Claude Fable 5 即将下线,可通过五项策略提取其价值并持续使用。
已收录 30 条与 Opus 相关的内容,按评分排序。
Grok 4.5在编码基准测试中以83.3分超越Opus 4.8,Cursor公司正基于600亿美元收购数据训练下一代模型。
入选理由:Grok 4.5在编码基准测试中得分83.3,领先Opus 4.8五分
SpaceXAI发布Grok 4.5,首个Cursor合作训练的Opus级模型,性能接近Opus但成本效率提升,专注编码与代理场景。
入选理由:Grok 4.5是Cursor合作训练的首个非软件工程专用模型
阿尔伯塔省政府使用Claude模型20小时扫描4.66亿行代码,修复安全漏洞,传统方法需6.5年。
入选理由:Claude扫描4.66亿行代码仅用20小时,传统方法需6.5年
Claude Fable 5 即将下线,可通过五项策略提取其价值并持续使用。
入选理由:使用可重做性测试判断任务是否值得用顶级模型执行
Grok 4.5在SpaceX和Tesla内部测试,性能接近Opus,SpaceX计划每月发布全新模型。
入选理由:Grok 4.5基于1.5T V9模型并加入Cursor数据训练
GLM 5.2 在 BrowserCode 中表现接近 Opus 级别,且是目前最便宜的模型。
入选理由:GLM 5.2 在 BrowserCode 中表现接近 Opus 级别。
SubQ 是首个基于完全次二次稀疏注意力架构的大型语言模型,其计算成本降低 1000 倍,上下文窗口达 1200 万 token。
入选理由:SubQ 的上下文窗口达到 1200 万 token,是 Opus 的 52 倍。
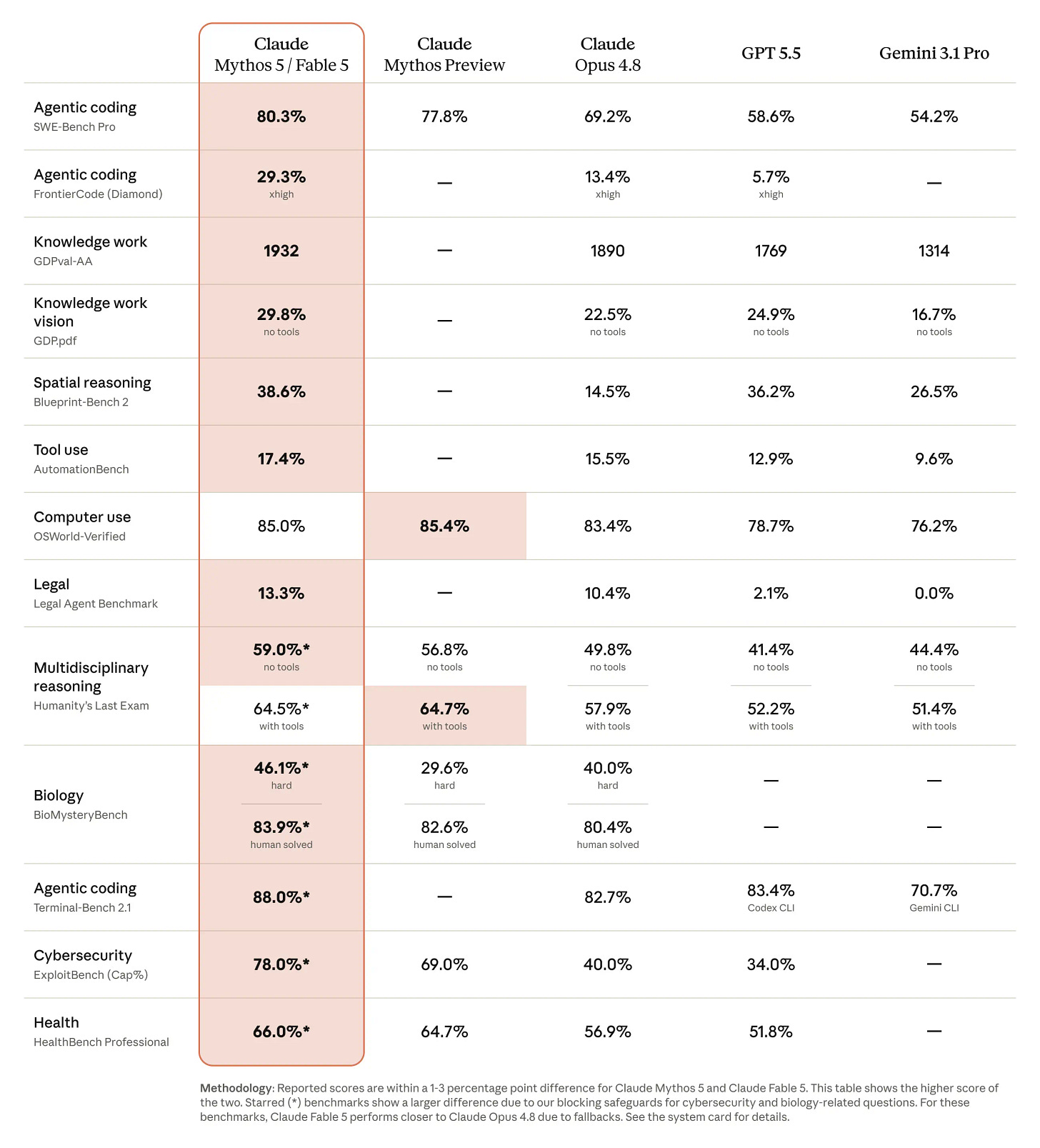
Anthropic 推出 Claude Fable 5 模型,性能显著提升但价格高昂,引发业界两极评价。
入选理由:Claude Fable 5 是 Anthropic 首个安全可用的 Mythos 级模型,性能优于 Opus。
Anthropic 推出 Claude Fable 5,其能力显著提升,但伴随严格的限制措施,引发对 AI 安全与控制的讨论。
入选理由:Claude Fable 5 是目前公开可用的最智能模型,性能远超现有 Opus 模型。
Anthropic 发布的 Mythos 级模型 Fable 5 在性能上表现强劲,但因 ZDR 和 RSI 抑制政策引发争议。
入选理由:Fable 5 的规模是 Opus 的两倍,性能在 FrontierCode Diamond 上提升了 16.9%。
Claude Code is a powerful AI tool that can be used to build projects without writing any code. It is achieved by installing Node.js, Claude Code, and Cursor, a free editor that shows every file Claude touches in real-time. Claude Code can be used to build four projects, including a landing page. The way Claude Code works is by using Opus and Sonnet models, Opus is the senior architect, used for planning, and Sonnet is the builder, used for execution. Claude Code can also be used for debugging an
入选理由:Claude Code 是一个强大的 AI 工具,可以用于构建项目,无需编写代码。
MiniMax M3 is China's first open-source model with simultaneous long-context, multimodal, and coding capabilities; it scored 59% on SWE-Bench Pro, outperforming GPT-5.5 and Gemini 3.1 Pro, with efficiency boosted to 1/20 of the previous generation.
入选理由:M3在SWE-Bench Pro上得分59%,超越GPT-5.5和Gemini 3.1 Pro
Felix Rieseberg分享了如何在日常生活中使用Claude Cowork,强调通过抽象层提升效率,并利用电子邮件作为个人数据源。
入选理由:识别并利用AI解决日常琐事。
GPT-5.5 has shown significant improvements in complex agent work, outperforming Opus 4.7, demonstrating OpenAI's strong competitiveness in model development.
入选理由:GPT-5.5 在复杂代理工作方面表现出色。
Karpathy points out that 90% of the AI coding bill is spent on unnecessary context, and optimizing context usage and routing strategies can significantly reduce costs.
入选理由:AI 编码账单的 90% 花费在不必要的 context 上。
Codex Spark's coding speed reaches 1,200 tokens per second, significantly outpacing Sonnet and Opus in the 40-60 range, but high speed may lead to declining code quality.
入选理由:Codex Spark 生成速度为每秒 1200 tokens,比 Sonnet 和 Opus 快约 20 倍。
MiniMax M3通过稀疏注意力机制提升长期运行智能体的实用性,值得关注。
入选理由:稀疏注意力机制可降低长期智能体计算资源消耗达40%
GLM-5.2 在设计任务中表现优异,尤其在游戏、网页和3D世界设计方面,但尚未达到专业设计师水平。
入选理由:GLM-5.2 在设计任务中表现优异,尤其擅长游戏和3D世界设计。
美国对Fable 5的出口限制可能削弱美国的网络防御能力,因其限制了AI模型修复代码漏洞的能力。
入选理由:Fable 5被禁止用于修复代码漏洞,因其被误认为能‘破解’安全措施。
MiniMax M3通过稀疏注意力机制实现长期规划代理,但文章内容不完整,缺乏具体技术细节和实验数据支撑。
入选理由:稀疏注意力机制可降低长序列计算复杂度
该视频展示了基于扩散模型的文本生成技术,可在单设备上实现每秒1,000个token的生成速度,但不适用于大规模云部署。
入选理由:单设备推理速度可达每秒1,000个token,比Opus快11倍。
AI Agent 可能改变设计师的工作方式,但设计系统仍是关键,人工调整仍不可替代。
入选理由:设计系统能减少手动调整字型、字号和颜色的需求。
Anthropic released Opus 4.8 just 42 days after 4.7, and Andrej Karpathy’s joining two weeks ago sparked industry attention — their culture of rapid iteration + public sharing is becoming a top talent magnet.
入选理由:Anthropic 从 Opus 4.7 到 4.8 仅用 42 天,体现极强工程交付能力。
The article summarizes recent AI industry highlights, covering Anthropic’s Mythos/Opus discussion, the formalization of RSI research, and new long‑horizon evaluation benchmarks, underscoring the reliability gaps in frontier models.
入选理由:Anthropic 的 Opus 4.7 在某些化学任务上已匹配或超越专用 NMR 软件,显示模型在专业领域的潜力。
智谱开源 GLM 5.2,其编程能力达到 Opus 水平,已接入 Cola 作为 beta 模型测试。
入选理由:GLM 5.2 是首个编程能力达到 Opus 水平的开源模型。
文章讨论了 Mythos 验证 VM 的过程,但信息密度较低,缺乏深度技术细节。
入选理由:Mythos 用于验证 Opus 编写的 VM。
Claude 产品线以艺术作品命名,包括 Haiku、Sonnet、Opus、Fable 和 Mythos,分别对应不同特性和应用场景。
入选理由:Claude 的产品线使用艺术作品命名,如 Haiku、Sonnet、Opus 等。
Opus 4.7 和 Opus 4.8 之间的权重变化不到 1%,表明版本间调整较小。
入选理由:Opus 4.8 与 4.7 的权重变化小于 1%。
文章链接无法访问,内容缺失,无法提供有效技术信息。
入选理由:文章内容无法访问,无法评估技术价值
DeepSWE’s evaluation shows Opus 4.8 outperforms 4.7 in performance, cost, and efficiency, yet still lags far behind GPT-5.5; the author continues using cheaper 4.6 without deep testing of 4.8 or 5.5, and expresses skepticism toward benchmarks, preferring real user feedback from social media.
入选理由:Opus 4.8 性能强于 4.7,同时具备更低推理成本与更高效率,但未达 GPT-5.5 水平。
![[AINews] SpaceXAI launches Grok 4.5, first Opus-class model post Cursor acquisition](https://substackcdn.com/image/fetch/$s_!beuF!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F3dad0acc-e1ba-4ce4-9196-4ea6e56633a0_1628x1726.png)





![[AINews] Anthropic Claude Fable 5 — Mythos but Safe, with Controversial Terms](https://substackcdn.com/image/fetch/$s_!TXW4!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F7af8f73c-7a20-4f7e-ac83-a05cbc892d8b_2318x1684.png)














