Chinese AI Company Breaks Bottleneck to Run 60 Billion Parameter Model on Mobile
爱范儿2653 字 (约 11 分钟)
92
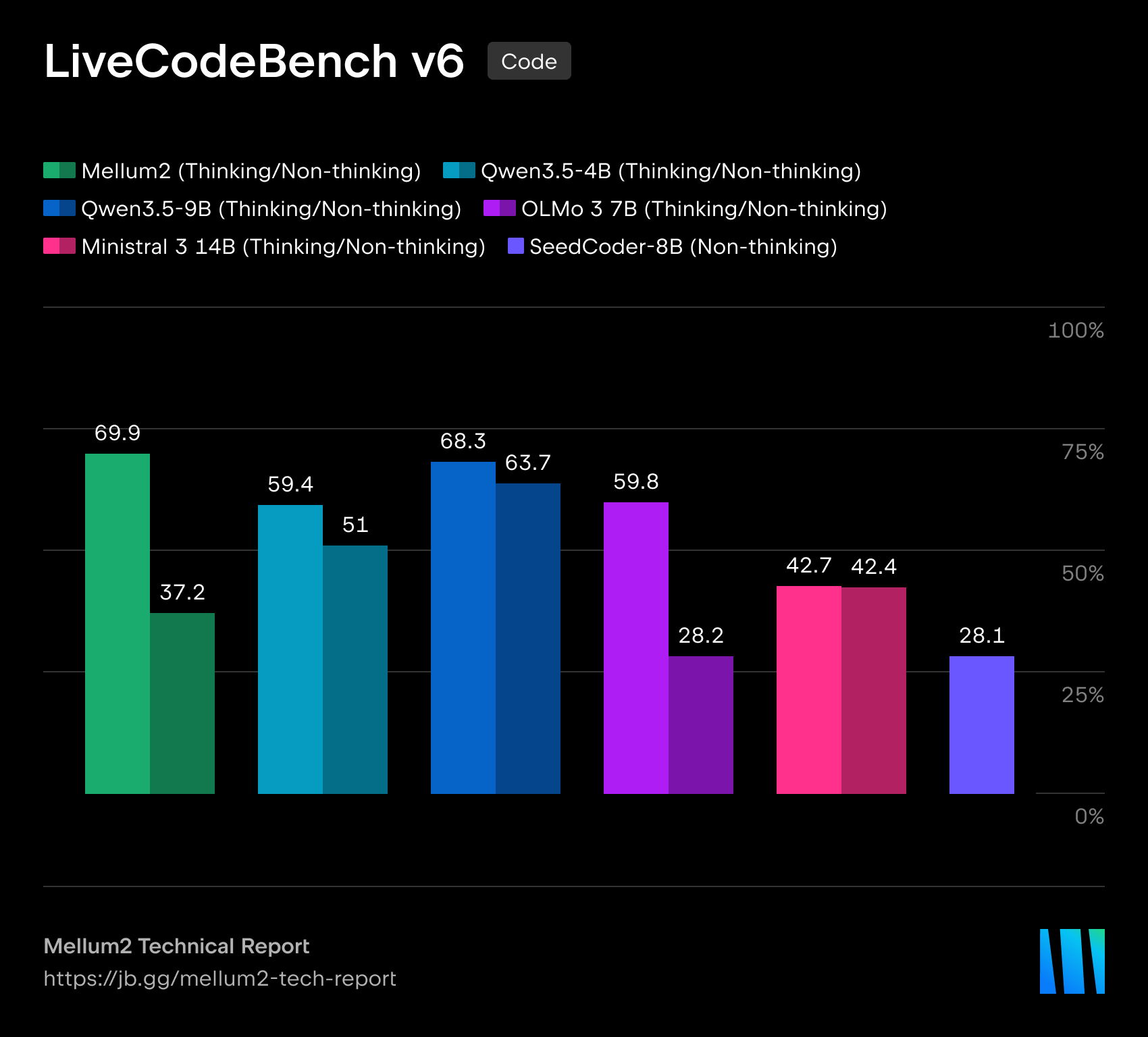
A Chinese AI company has broken the bottleneck of running a 60 billion parameter model on mobile devices using ternary quantization, saving 6x memory with minimal performance loss.
入选理由:三值量化可节省6倍显存,保留97%模型能力,支持在8GB内存手机运行600亿参数模型。
FeaturedArticle#AI Model#Ternary Quantization#Ascend Chip#Edge AI#Model Compression中文


![[AINews] Thinking Machines' Native Interaction Models - TML-Interaction-Small 276B-A12B - advances SOTA Realtime Voice and kills standard VAD](https://substackcdn.com/image/fetch/$s_!LR03!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F02190942-3f50-4067-ae03-97c6b504b3a3_1490x1592.png)