【串台 · AI炼金术】和 Mars 聊聊:像设计产品一样,设计 Prompt
奇想驿 by 产品沉思录1684 字 (约 7 分钟)
87
将Prompt视为产品设计,结合私有知识与行为数据,构建AI时代笔记工具的差异化护城河。
入选理由:AI拉平功能赛道,私有知识与行为数据成新壁垒
每日 AI 资讯雷达
2026-04-17 当日 traeai 收录 60 条 AI 技术与产品资讯,按评分排序,每条带 AI 摘要、要点与原文链接。
canonical: https://www.traeai.com/daily/2026-04-17
将Prompt视为产品设计,结合私有知识与行为数据,构建AI时代笔记工具的差异化护城河。
前Meta AI研究总监田渊栋深入剖析大模型效率瓶颈、创新路径与AI洪水下的人类定位,强调自进化、持续学习和科研品位的重要性。
Mario Zechner 批判当前 AI 编程工具过度复杂,主张回归极简设计,仅用读、写、编辑和 Bash 四工具构建高效智能体 Pi。
将Prompt视为产品设计,结合私有知识与行为数据,构建AI时代笔记工具的差异化护城河。
入选理由:AI拉平功能赛道,私有知识与行为数据成新壁垒
前Meta AI研究总监田渊栋深入剖析大模型效率瓶颈、创新路径与AI洪水下的人类定位,强调自进化、持续学习和科研品位的重要性。
入选理由:大模型已陷入资源内卷,扼杀多元创新,需转向效率与持续学习
Mario Zechner 批判当前 AI 编程工具过度复杂,主张回归极简设计,仅用读、写、编辑和 Bash 四工具构建高效智能体 Pi。
入选理由:主流 AI 编程工具因功能堆砌变得不可预测,陷入“宇宙飞船”陷阱
ElevenLabs CEO 揭示语音大模型如何通过神经网络实现情感与韵律的“涌现”,并分享其自服务驱动的高速增长与AI原生组织模式。
入选理由:语音模型近年才实现高拟真度,情感与口音通过大规模训练自然涌现
黄仁勋详解英伟达如何通过“电子到Token”转化构建护城河,并就对华芯片管制、能源瓶颈与GPU架构优势展开深度辩论。
入选理由:英伟达核心价值在于将电子高效转化为高价值AI Token,依赖软硬协同与供应链控制
Cloudflare 推出 Unweight,一种无损压缩技术,在 H100 GPU 上将 LLM 模型体积减少 15–22%,不牺牲推理质量且无需专用硬件。
入选理由:Unweight 实现 LLM 权重无损压缩,节省约 3GB VRAM,提升 GPU 利用率。
Cloudflare 推出共享字典压缩技术,利用浏览器缓存作为字典实现增量传输,显著减少重复部署带来的冗余带宽消耗。
入选理由:共享字典将用户已缓存的旧资源用作压缩字典,仅传输变更部分
Lakehouse多引擎环境下,SQL标识符解析规则不一致导致表和列不可见或查询失败,需通过统一命名规范和数据契约解决。
入选理由:Apache Iceberg等开放表格式未解决SQL方言差异,标识符解析仍依赖各引擎规则。
Medallia工程师分享在支持IE10等旧浏览器约束下,通过AST迁移、Preact替换和差异化加载等手段优化超大规模CX平台前端性能的实战经验。
入选理由:使用AST驱动的codemod实现React 15到现代版本的大规模安全迁移
提出Ecom-RLVE框架,将强化学习与可验证奖励机制引入电商对话代理,支持多轮、工具增强的购物任务。
入选理由:电商对话代理需从流畅性转向任务完成能力,传统微调难以覆盖复杂约束组合
Coding正推动AI从聊天机器人迈向能自主执行任务的Agent,成为AGI第二幕核心驱动力,并重塑硅谷大模型竞争格局。
入选理由:Coding是AGI发展的关键加速器,领先模型通过代码能力放大顶尖人才生产力10-50倍
Meta发布TRIBE v2,一个能高精度预测人脑对视听语言刺激反应的基础模型,支持零样本泛化并开源模型与代码。
入选理由:TRIBE v2基于700+志愿者fMRI数据训练,分辨率比同类模型高70倍
Meta发布SAM 3.1,通过对象多路复用和全局推理实现更快、更高效的实时视频检测与跟踪。
入选理由:SAM 3.1支持单次前向传播同时跟踪最多16个对象,视频处理速度翻倍。
AI体验设计正从提示工程转向约束优先架构,以解决大模型幻觉与可信度问题。
入选理由:提示仅能引导风格,无法保证事实准确性或防止幻觉。
Physical Intelligence发布π0.7模型,首次在机器人领域实现组合泛化,通才性能超越专才,标志VLA迎来GPT-3时刻。
入选理由:π0.7通过多层prompt机制有效利用多样化数据,无需清洗即可提升性能
MiniMax M2.7 实现模型自主迭代,Cursor 通过持续预训练提升编程能力,Cloudflare 将大模型推理嵌入边缘基础设施。
入选理由:M2.7 能自主优化评测系统与工作流,在100轮迭代中提升性能30%
文章探讨智能体工程化趋势,强调通过约束工程、结构化记忆和多智能体协作实现AI可靠编程。
入选理由:智能体工程化核心在于构建Harness约束体系,而非仅依赖模型能力
Anthropic 提出 Managed Agents 架构,通过 session、harness、sandbox 三层解耦,实现可恢复、可扩展、可治理的生产级智能体系统。
入选理由:harness 随模型进化易过时,需设计寿命更长的稳定接口
GitBook 在 Vercel 上托管 3 万文档站点,通过细粒度缓存与按标签失效机制,实现合并后 300ms 内全球内容更新。
入选理由:采用 Next.js 和 Vercel 的 use cache 指令实现函数级缓存,避免整页缓存浪费
文章深入讲解数据库索引原理,结合 PostgreSQL 示例演示如何创建、优化和避免误用索引以提升查询性能。
入选理由:索引通过独立数据结构加速查询,避免全表扫描,显著提升大数据量下的检索效率。
文章系统解析现代稀疏神经检索模型(如SPLADE++),对比关键词与稠密检索优劣,并展示其在Qdrant中的实践应用。
入选理由:稀疏神经检索结合BM25的可解释性与语义理解能力,优于传统关键词匹配
Cloudflare 推出 Artifacts:面向 AI Agent 的 Git 兼容版本化存储系统,支持按需创建仓库、导入现有 Git 项目并提供 REST/Workers API。
入选理由:Artifacts 是为 AI Agent 设计的分布式版本化文件系统,兼容 Git 协议。
Vercel 推出 Workflows,通过将编排逻辑内嵌于应用代码,实现无需独立 orchestrator 的持久化执行模型。
入选理由:Workflows 消除传统长流程所需的独立编排服务,状态与逻辑统一在应用代码中
Google MaxText 新增单机 TPU 上的监督微调(SFT)和强化学习(RL)支持,集成 Tunix 和 vLLM,简化 LLM 后训练流程。
入选理由:MaxText 现支持在单机 TPU(如 v5p-8)上运行 SFT 和 RL,降低后训练门槛。
OpenAI 发布 Codex 重大更新,支持跨应用操作、图像生成、记忆功能与自动化工作流,覆盖软件开发生命周期。
入选理由:Codex 现可操作系统应用、浏览器和终端,实现跨工具自动化开发任务。
本文详细指导如何基于 RustFS、Iceberg 和 Nessie 等开源组件构建可扩展的批处理数据湖,强调避免厂商锁定并支持未来扩展。
入选理由:使用 Docker 搭建包含对象存储、表格式和目录服务的单节点开源数据湖
GitHub 利用 eBPF 在内核层监控并阻断部署脚本对 github.com 的意外依赖,避免因服务中断导致无法修复的循环依赖问题。
入选理由:部署脚本可能隐式依赖 GitHub 服务,造成灾难性循环依赖
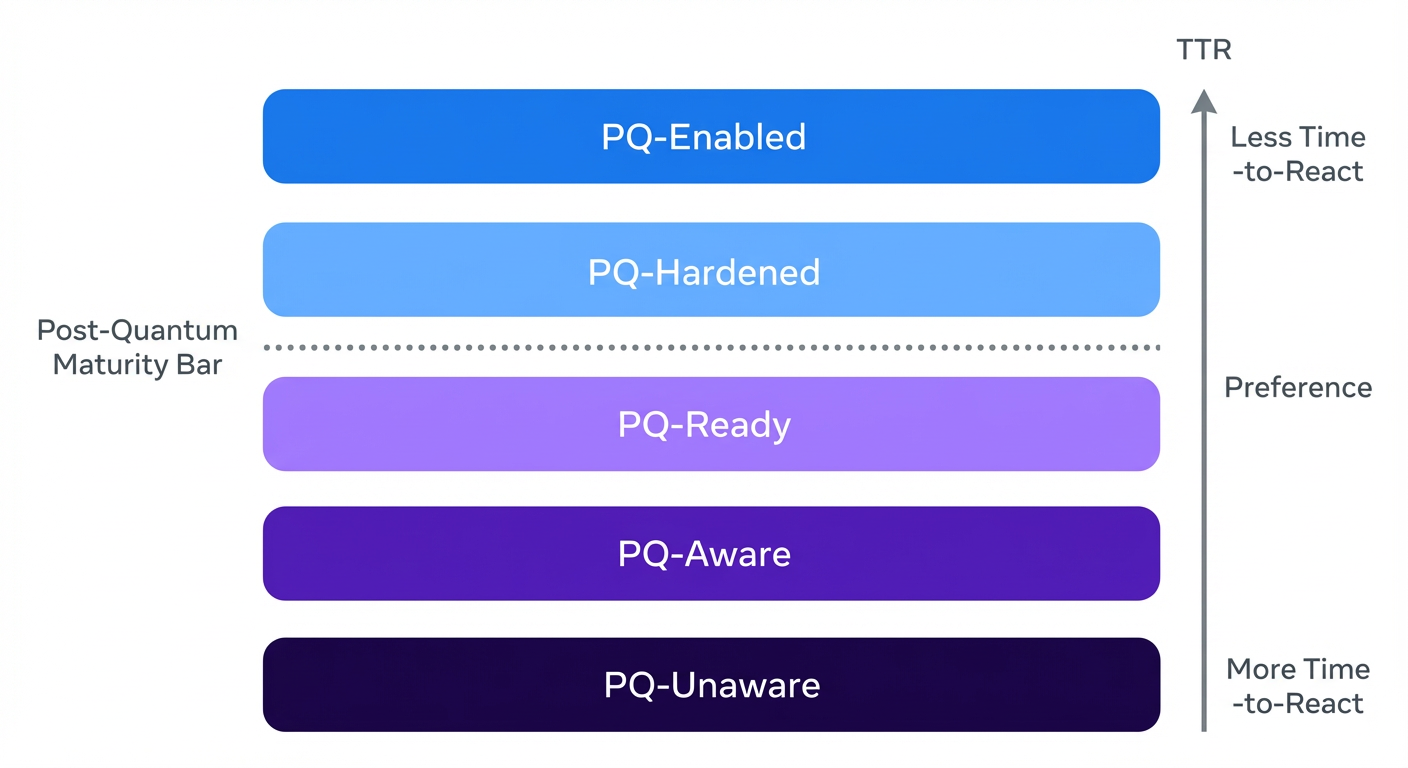
Meta提出PQC迁移框架与成熟度等级,分享其在后量子密码部署中的实践经验,以应对“先存储后解密”威胁。
入选理由:提出PQC迁移等级模型,帮助组织评估和规划后量子密码就绪度
AWS Bedrock 引入基于形式化验证的自动推理检查,将生成式 AI 输出转化为可数学证明、可审计的合规结果。
入选理由:传统 LLM-as-a-judge 方法无法满足监管行业对可审计性的要求
本期具身智能季报梳理26Q1关键进展,聚焦人形机器人、灵巧手与英伟达世界模型三大方向。
入选理由:英伟达推WAM世界动作模型,挑战以语言为中心的VLA范式
技术已过剩,AI时代组织提效的瓶颈在于人;ColaOS探索高情商Agent与深度协作新模式。
入选理由:代码100%由AI生成后,人成为组织效率唯一瓶颈
文章提出AGI已实现,当前关键在于分发,并探讨AI工程化、安全权衡与Agent网络等实战策略。
入选理由:AGI已初步实现,竞争焦点转向产品分发而非模型研发
Cloudflare 推出 Redirects for AI Training,将页面 canonical 标签对 AI 爬虫转为 301 重定向,确保训练数据使用最新内容。
入选理由:AI 训练爬虫常忽略 noindex 和警告横幅,导致摄入过时文档
AirJelly 创始人提出主动式 AI 的核心在于上下文感知而非执行能力,主张通过捕捉用户意图关键节点构建壁垒。
入选理由:主动式 AI 的关键是从理解上下文和意图出发,而非仅提升任务执行能力
阿里云百炼负责人于文渊指出,AI Agent引爆Token消耗,算力需求激增,企业应优先选择MaaS而非自建GPU,并强调高质量生产代码仍需人工把控。
入选理由:AI Agent推动Token消耗指数级增长,算力成为关键瓶颈
中国动力电池产业通过政策引导、极致工程能力和完整供应链,实现从手工作坊到全球主导的逆袭。
入选理由:早期‘十城千辆’和白名单政策有效培育了本土电池产业链
英伟达冲刺1万亿收入依赖推理业务爆发,但面临CoWoS产能、竞争加剧与生态护城河挑战。
入选理由:推理业务正成为英伟达核心增长引擎,Vera Rubin平台性能大幅提升
GTC 2026揭示AI竞争重心正从模型训练转向推理系统,开源模型与Agent爆发推动推理层成为关键战场。
入选理由:推理层因Agent爆发和Token消耗激增成为AI新竞争焦点
OpenClaw 维护者与安全专家深入剖析 Agent 爆火背后的能力释放机制与安全风险,强调权限控制与协议优化的紧迫性。
入选理由:OpenClaw 通过移除模型限制释放能力,核心在于“不做什么”而非新增功能
中国主导全球动力电池产业,固态电池5-10年有望商用,储能与AI成新增长点。
入选理由:磷酸铁锂凭成本和安全优势重回主流,三元锂侧重高能量密度场景
谷歌DeepMind发布Gemini Robotics-ER 1.6,赋予波士顿动力Spot机器狗高精度仪表识别与空间推理能力,任务成功率显著提升。
入选理由:ER 1.6通过Pointing机制实现精准空间理解,物体计数和定位错误大幅减少
文章探讨大模型竞争从“推理式思考”转向“智能体式思考”,强调AI需在真实环境中持续行动,并介绍Anthropic与Cursor提升Agent可靠性的工程方案。
入选理由:智能体式思考关注AI在动态环境中的持续行动能力,而非仅深度推理。
JetBrains 正重构 IntelliJ 平台架构,将写操作移出 UI 线程以提升响应性,已使 UI 线程持有写锁时间减少约三分之二。
入选理由:IntelliJ 平台依赖单一读写锁,导致 UI 线程易因写操作阻塞而卡顿。
GetX 因作者删库彻底消失,暴露了其单点维护、过度耦合和隐式依赖等架构风险。
入选理由:GetX 全生态仓库被作者删除,项目失去源码与社区支持
Clawdbot(OpenClaw)通过赋予AI实际操作系统权限,将个人助理从对话推向执行层,引发对安全边界与实用性的深度探讨。
入选理由:Clawdbot的核心突破在于让AI真正操作用户系统,而非仅提供对话。
员工因官方工具效率低下而私下使用未经批准的AI工具,形成“影子AI”现象,带来数据与决策风险。
入选理由:影子AI源于员工追求效率,而非故意违规
Notion团队揭秘自研AI智能体历经5次重构,强调产品需围绕人机协作设计,而非仅封装大模型。
入选理由:Notion Custom Agents历经4-5次重建,因早期模型能力与工具调用标准不足
文章对比传统网页抓取与AI驱动抓取的技术原理、工具链和适用场景,强调前者依赖结构化选择器而后者通过语义描述实现更高鲁棒性。
入选理由:传统抓取依赖CSS/XPath选择器,页面结构变动易导致失效
向量量化通过压缩高维向量(如OpenAI嵌入)显著降低内存占用和搜索成本,Qdrant支持标量、乘积和二值化三种主要方法。
入选理由:1536维float32向量占6KB,百万级数据需GB级内存,量化可大幅压缩存储
向量数据库专为高效处理高维向量数据而设计,支持基于语义相似性的检索,适用于推荐系统、RAG等AI场景。
入选理由:向量数据库专用于存储和检索高维向量,支持语义相似性搜索
Qdrant 新增 Distance Matrix API,支持高效计算高维数据距离矩阵,结合 UMAP 实现直观的无监督数据探索。
入选理由:Qdrant 1.12 引入 Distance Matrix API,避免重复计算,提升相似性分析效率
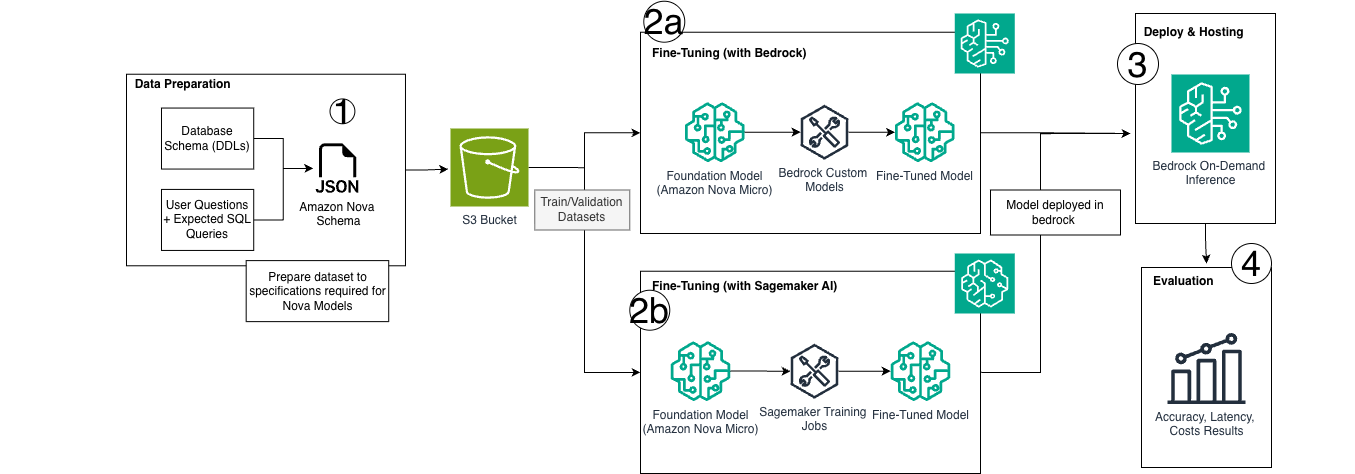
AWS 展示使用 Amazon Nova Micro 和 Bedrock 按需推理,通过 LoRA 微调实现低成本、高准确率的定制化 text-to-SQL 方案。
入选理由:LoRA 微调结合按需推理可显著降低定制 text-to-SQL 的持续托管成本
群核科技历经15年深耕空间数字化,从SaaS工具酷家乐转型为AI时代物理世界数据与空间智能基础设施提供商。
入选理由:长期积累的物理空间数据成为AI训练稀缺资源
真格基金与Koji对谈复盘2025 AI爆发,提出2026是“Year of R”:关注商业回报、研究突破与用户记忆。
入选理由:2025验证了Agent元年,Manus等产品标志AI应用真正落地
2026年Q1 AI竞争焦点从模型转向Agent系统,OpenClaw引爆本地智能体热潮,Anthropic与OpenAI在编码产品和平台生态展开三重对阵。
入选理由:OpenClaw凭借本地运行、聊天集成和长期记忆成为Agent标杆
马斯克推Terafab计划建太空数据中心,目标年产1TW算力;英伟达重拾CPU并推统一平台;AI算力基础设施催生新创业机会。
入选理由:马斯克Terafab计划将80%算力部署太空,年耗电达1TW,远超当前全球AI算力总和
教育老兵李可佳提出“送AI Agent去读书”理念,通过BotLearn构建面向Agent的学习社区,强调原子化、可组合的协议优于传统产品设计。
入选理由:学习非人类刚需,但“送别人学”的市场巨大
AI正引发智能领域的“哥白尼时刻”,投资人应寻找真正理解底层逻辑的“天庭下凡”者,而非套用旧互联网思维创业。
入选理由:人类需接受不再是智能中心,以AI为中心重构业务逻辑
Anthropic 推出的 Agent Skills 通过新抽象层重构大模型调用方式,推动工程标准化,但未解决确定性与可控性问题。
入选理由:Agent Skills 是比 Tool Calling 更高层的抽象,封装业务逻辑提升复用性
播客探讨AI Agent(“小龙虾”/OpenClaw)如何重塑软件交互、存储与安全,预测SaaS将被数据库+LLM架构颠覆。
入选理由:未来软件将优先为Agent设计,而非人类用户,推动CLI和文件系统复兴。