Amazon SageMaker AI LLM 推理的全面可观测性:从 GPU 利用率到 LLM 质量
AWS Machine Learning Blog2218 字 (约 9 分钟)
92
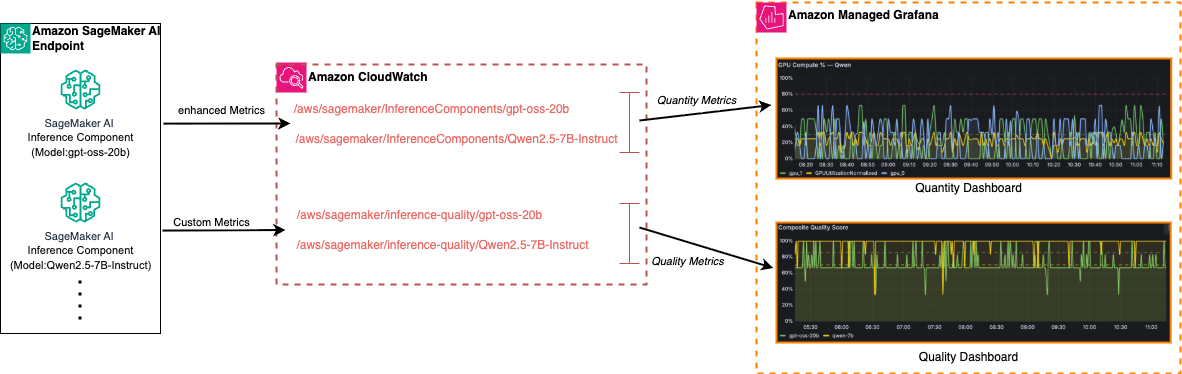
AWS 提出面向 SageMaker LLM 推理的全栈可观测方案,通过 CloudWatch 收集基础设施指标(GPU 利用率、延迟等)与自定义质量指标(响应准确性、合规性),结合 Managed Grafana 实现量(quantity)与质(quality)双维度监控,解决 LLM 推理中“系统健康但输出劣质”或“输出优质但资源浪费”的典型问题。
入选理由:SageMaker AI Inference 支持单 endpoint 多 inference components 部署(如 gpt-oss-20b + Qwen2.5-7B-Instruct),实现模型隔离与共享资源协同。
精选文章#LLM#可观测性#Amazon SageMaker#CloudWatch#Grafana英文