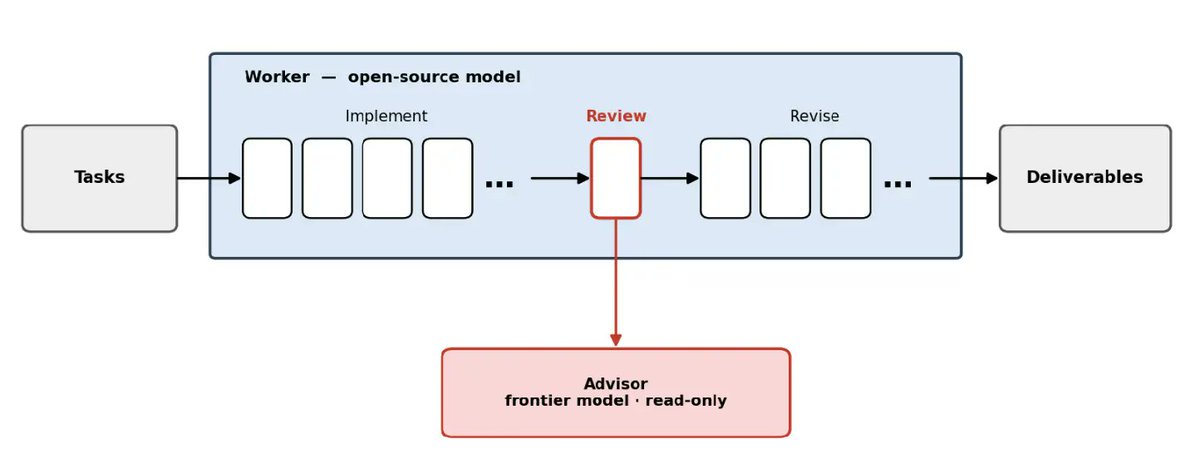
Open-weight models like GLM-5.2 and Kimi K2.6 demonstrate the capability & performance needed fo...
Fireworks AI(@FireworksAI_HQ)165 字 (约 1 分钟)
85
Fireworks AI与ClayRunHQ合作推动开放权重模型在GTM领域的落地,GLM-5.2和Kimi K2.6展现关键性能。
入选理由:GLM-5.2和Kimi K2.6模型已具备实际GTM工作所需的性能
精选推文#AI模型#GTM工具#Fireworks AI#开放权重中英混合