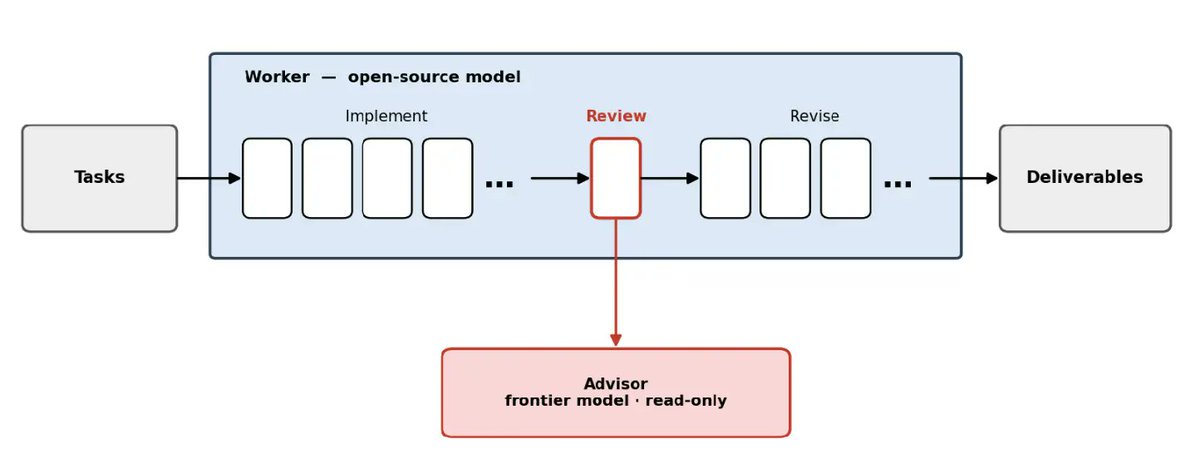
Many still debate open vs closed, and compare cost per token (accounting metric). Better to shift ...
Fireworks AI(@FireworksAI_HQ)170 字 (约 1 分钟)
85
模型成本评估应关注任务完成成本而非每token价格,2400次测试表明按任务难度路由可同时优化成本与覆盖范围。
入选理由:2400次基准测试覆盖10个模型,包括Kimi K3
精选推文#模型评估#成本优化#AI推理#Fireworks AI英文