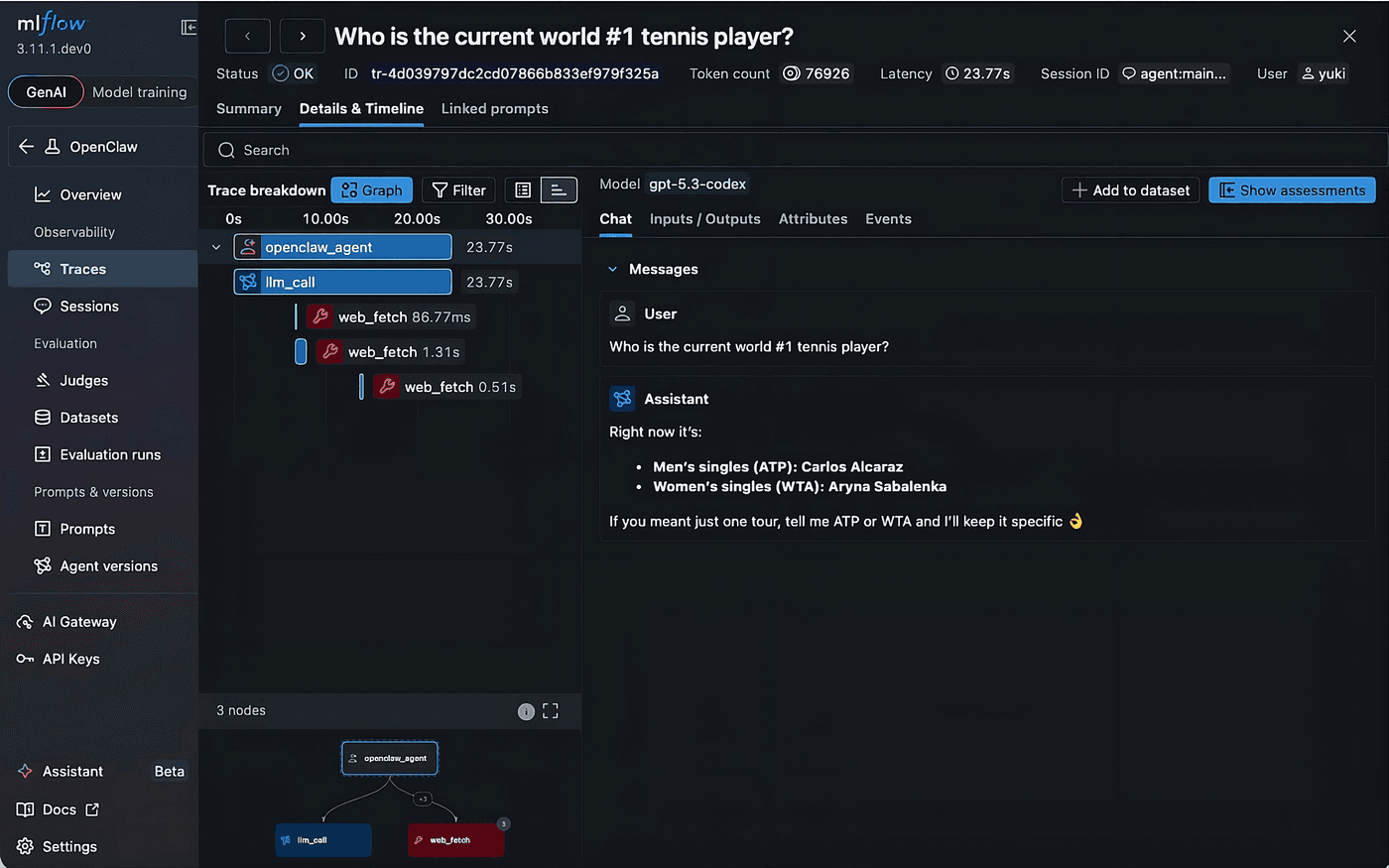
From Black Box to Observability: Tracing OpenClaw with MLflow
MLflow Blog1768 字 (约 8 分钟)
85
MLflow Tracing使OpenClaw个人AI代理的执行过程可追踪,将模糊的调试问题转化为可操作的执行记录。
入选理由:MLflow Tracing捕获每个LLM调用、工具调用和子代理生成的完整执行路径
精选文章#MLflow#OpenClaw#AI代理#可观测性#调试工具英文
公司
别名:Databricks Inc.
提供统一数据平台和AI工程解决方案的公司
已跟踪 30 条高相关材料
最近变化
2026-07-18 · Kimi K3被评价为首个实用的中国顶级模型,但与西方模型仍存在差距
为什么值得关注
Databricks 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
Tech builds on AI. Finance protects the margin.
Databricks · 8.5 分
AI代理重塑单位经济学,财务需通过实时数据监控与自动化工具确保盈利。Databricks案例显示,财务团队使用AI优化合同流程并提升分析效率。
Building a soccer coaching app on Databricks
Databricks · 8.5 分
Databricks构建的足球教练应用通过整合平台工具和AI,实现比赛数据的实时分析,处理5100万行数据生成战术洞察。
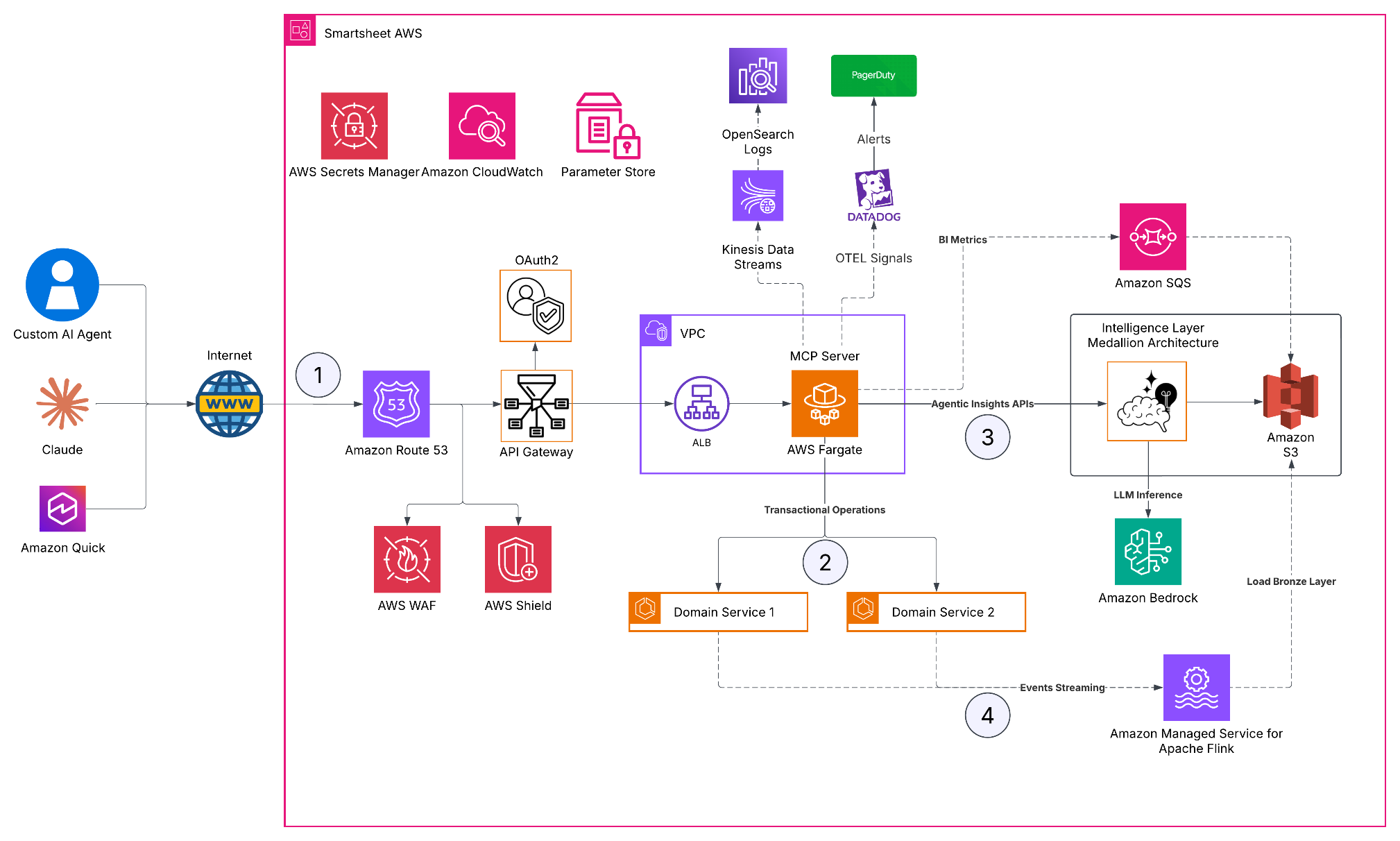
How Smartsheet built a remote MCP server on AWS
AWS Machine Learning Blog · 8.5 分
Smartsheet在AWS上构建远程MCP服务器,通过优化节省30亿token,提升AI代理与企业数据的交互效率。
已收录 30 条与 Databricks 相关的内容,按评分排序。
MLflow Tracing使OpenClaw个人AI代理的执行过程可追踪,将模糊的调试问题转化为可操作的执行记录。
入选理由:MLflow Tracing捕获每个LLM调用、工具调用和子代理生成的完整执行路径
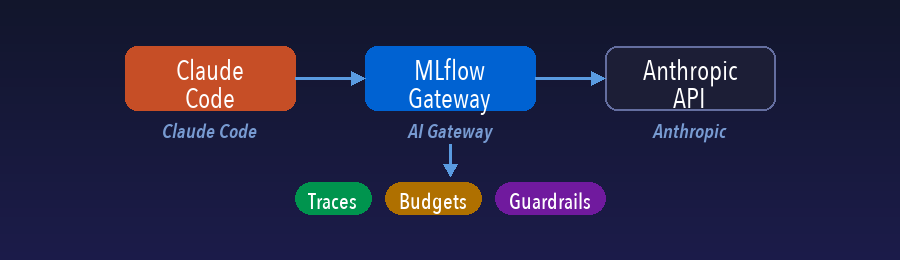
MLflow 3.12.0新增AI Gateway功能,可无缝集成Claude Code,实现请求追踪、预算控制和内容策略管理。
入选理由:通过设置两个环境变量即可实现Claude Code与MLflow的集成,无需修改应用代码
Databricks构建的足球教练应用通过整合平台工具和AI,实现比赛数据的实时分析,处理5100万行数据生成战术洞察。
入选理由:Databricks平台处理5100万行比赛数据,实现亚秒级2D/3D战术分析
AI代理重塑单位经济学,财务需通过实时数据监控与自动化工具确保盈利。Databricks案例显示,财务团队使用AI优化合同流程并提升分析效率。
入选理由:AI代理使计算成本与收入匹配速度提升10倍,需实时监控避免利润损失
Smartsheet在AWS上构建远程MCP服务器,通过优化节省30亿token,提升AI代理与企业数据的交互效率。
入选理由:使用AWS Fargate和Kinesis实现低延迟数据处理
Databricks通过GenAI和LLM技术解决高校咨询电话质量评估难题,实现规模化转录、评分与洞察提取。
入选理由:使用OpenAI Whisper等基础模型可提升电话转录准确率60%以上
数据原生AI代理通过将模型与数据平台集成,解决外部代理导致的治理漏洞、性能损耗和成本问题,成为企业AI架构新方向。
入选理由:外部代理导致治理漏洞、多跳延迟和成本碎片化,企业需承担隐藏的扩展税
Databricks平台现支持Thinking Machines Lab的Inkling开放权重模型,企业可借此构建AI代理和编码应用,提升定制化与成本控制能力。
入选理由:Inkling模型通过Unity AI Gateway提供,支持多模态输入和编码优化。
Apache Spark 4.2通过metric views、Spark Connect和Auto CDC等特性,强化了数据治理与AI原生分析能力,提升跨生态数据处理效率。
入选理由:Metric Views统一业务指标定义,避免多系统重复计算导致的语义偏差
Databricks推出Feature Views,通过统一定义特征逻辑消除训练/服务偏差,实现高效实时推理。
入选理由:Feature Views通过单一定义消除训练/服务偏差,提升模型性能。
现代化数据层是构建智能营销堆栈的关键,Acxiom通过迁移到Databricks实现性能提升80-90%。
入选理由:Acxiom迁移到Databricks后性能提升80-90%
从Azure Synapse迁移到Databricks Lakehouse可简化架构、提升性能并降低成本。
入选理由:Databricks统一平台减少30%治理成本(基于客户案例)
Barracuda通过Databricks Genie实现自然语言日志搜索,使安全分析效率提升并保障多租户数据隔离。
入选理由:Genie将日志查询从SQL转换为自然语言,查询结果秒级返回
自动化数据科学流程的5种代理工作流可节省45%时间,Databricks已集成相关功能,核心依赖ReAct循环与LLM工具。
入选理由:数据科学家45%时间消耗在数据清洗,代理可自动化处理
无服务器数据库是AI应用的新基准,但并非所有产品都实现了计算与存储分离的创新。
入选理由:选择无服务器数据库时,应优先考虑计算与存储分离的架构。
AVL 使用 Databricks 的 Impulse 框架,将测量数据分析从传统工具迁移到湖仓一体架构,显著提升效率并实现数据治理。
入选理由:Impulse 通过 Python 表达式实现时间序列分析,无需 Spark 专业知识。
英国学生办公室通过Databricks平台提升数据分析效率,显著缩短处理时间并优化学生监管决策。
入选理由:Databricks将3亿条记录数据处理时间从8小时缩短至几分钟。
Databricks 提供了一种 ETL 迁移决策框架,建议根据工作负载选择 Lakehouse、Spark Declarative Pipelines 或 PySpark,并采用分阶段迁移策略。
入选理由:Lakehouse 适合 SQL 为主的团队,支持 Serverless 和 Classic 模式。
Databricks 利用 VLMs 和无服务器 GPU 技术,将视频转化为可搜索、可操作的智能数据。
入选理由:Databricks 使用 VLMs 和无服务器 GPU 技术实现视频的自动分析与摘要。
Databricks 正在构建企业代理的基础设施层,通过 Omnigent、LTAP 和 Lakebase 等技术推动前沿生态系统的开放。
入选理由:Databricks 正在进入企业代理的基础设施层,以支持更广泛的 AI 应用。
Databricks 强调开放生态对构建 Agent Clouds 的重要性,并介绍了其在数据与 AI 操作系统方面的创新。
入选理由:Databricks 推出 Omnigent,一个开源的元控制平台,用于整合和管理多个 AI 代理。
Meta-Harness架构正在成为AI基础设施的核心,Omnigent等开源项目推动标准化、安全、可扩展的系统集成。
入选理由:Omnigent是一个开源、可插拔的Meta-Harness架构,支持标准化集成各类AI代理。
Databricks 和 NVIDIA 合作推出 Genesis Workbench,为生命科学领域提供基于 GPU 的 AI 解决方案,支持药物研发全流程。
入选理由:Genesis Workbench 支持 Genomics、Single Cell、Large Molecule 等模块化部署。
Databricks 连续两年在 Gartner 魔力象限中排名第一,因其在 AI 平台执行能力和愿景完整性方面的卓越表现。
入选理由:Databricks 在 Gartner 2026 魔力象限中被评为领导者,执行能力和愿景完整性均排名第一。
Databricks 通过 Kythera Labs 的 AI 平台,使医疗系统能快速获取战略决策所需的数据洞察,提升效率并减少损失。
入选理由:Kythera Labs 使用 Databricks 的 AI 代理,可在 10 天内上线并实现 150% 的患者接触可见性提升。
Daikin Applied Americas 使用 Databricks Genie Code 通过结构化方法和 AI 工程提高数据管道构建效率。
入选理由:Genie Code 可将数据管道构建时间从数天缩短至数分钟。
企业级AI代理部署需关注模型选择、数据治理与规模化架构,而非仅聚焦于技术演示。
入选理由:选择模型时应优先考虑企业数据兼容性,而非单纯追求最新技术。
GLM-5.2的发布标志着开源大模型市场进入价格战阶段,企业将加速基于开源模型的二次开发。
入选理由:开源LLM的采用率将因价格战显著提升
当前主流文档格式如Markdown和HTML各有缺陷,亟需一种更适合AI代理协作的新型文档格式。
入选理由:Markdown易于人类阅读但缺乏丰富的视觉输出和交互性。
汇总AI领域近期动态,包含Kimi K3发布、Databricks融资及技术讨论,但缺乏深度分析。
入选理由:Kimi K3被评价为首个实用的中国顶级模型,但与西方模型仍存在差距
![[AINews] It's Meta-Harness Summer](https://substackcdn.com/image/fetch/$s_!LH6a!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fd1a3d909-a54b-4acd-aa2c-33823f9e032e_878x674.png)


