Claude Code 省 Token 指南:慎用 1M 上下文,不开新会话或者总是开新会话都不对
宝玉的分享4754 字 (约 16 分钟)
92
频繁开启新会话会导致提示缓存失效并触发全价重建,保持活跃会话反而更节省Token。 任务未切换且缓存未过期时应继续当前会话,任务变更或闲置超1小时再果断开新会话。 日常开发慎用1M上下文窗口,建议配置自动压缩阈值至20万Token以控制成本并维持性能。
入选理由:频繁开启新会话会导致提示缓存失效并触发全价重建,保持活跃会话反而更节省Token。
每日 AI 资讯雷达
2026-04-16 当日 traeai 收录 60 条 AI 技术与产品资讯,按评分排序,每条带 AI 摘要、要点与原文链接。
canonical: https://www.traeai.com/daily/2026-04-16
微软研究院联合高校提出ADeLe评估框架,通过18项核心能力维度对大模型与任务进行双向量化评分。该方法能构建模型能力画像,以约88%的准确率预测未知任务表现,并精准定位模型失败原因,有效弥补传统基准测试缺乏解释性与预测力的缺陷。
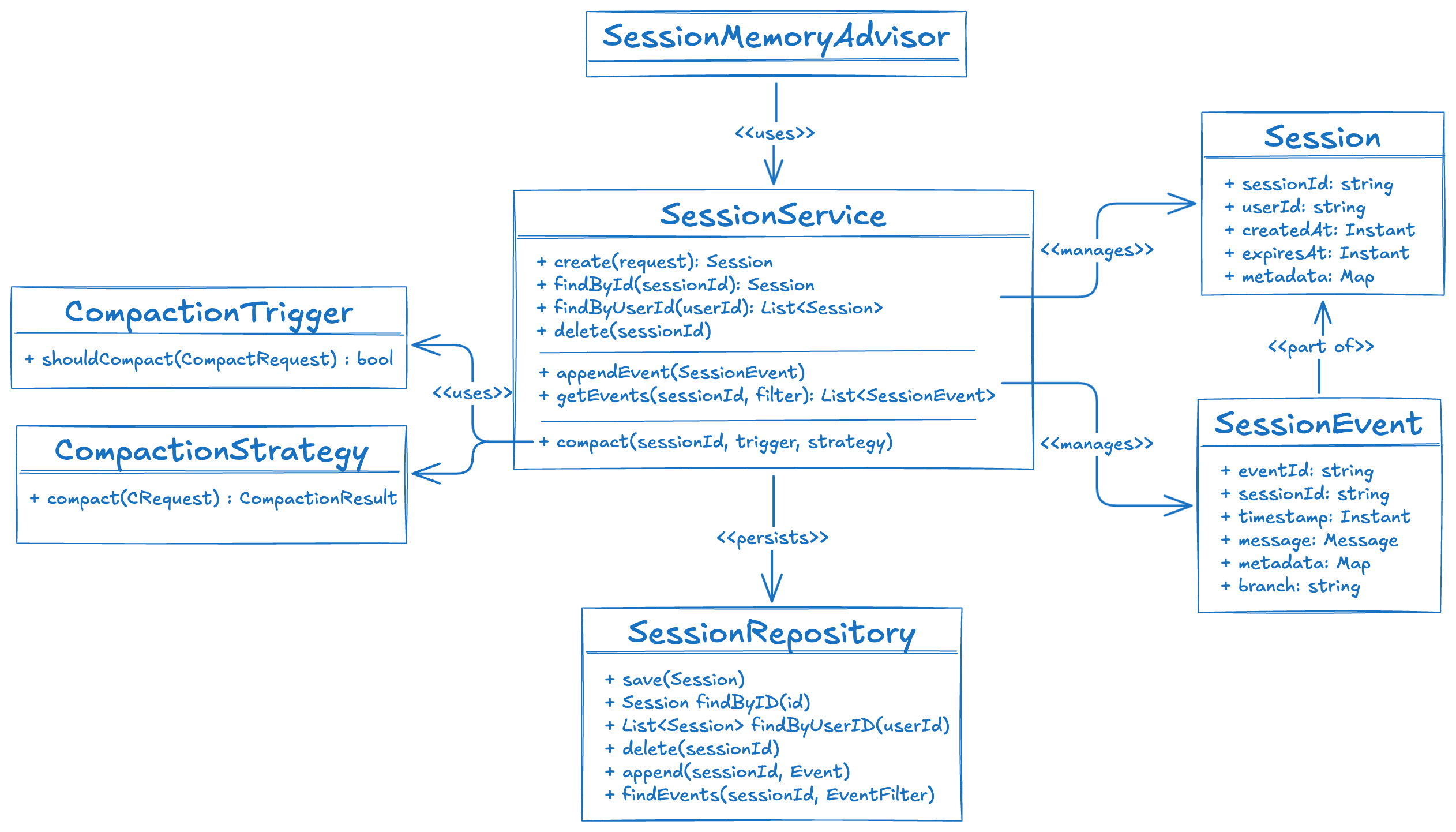
本文介绍 Spring AI 全新 Session API,采用事件溯源架构管理短期对话记忆,通过“轮次”原子化保障工具调用完整性,并提供可组合的上下文压缩触发器与策略,解决传统 ChatMemory 粗暴截断导致的上下文断裂问题,为多智能体协作提供结构化记忆底座。
频繁开启新会话会导致提示缓存失效并触发全价重建,保持活跃会话反而更节省Token。 任务未切换且缓存未过期时应继续当前会话,任务变更或闲置超1小时再果断开新会话。 日常开发慎用1M上下文窗口,建议配置自动压缩阈值至20万Token以控制成本并维持性能。
入选理由:频繁开启新会话会导致提示缓存失效并触发全价重建,保持活跃会话反而更节省Token。
微软研究院联合高校提出ADeLe评估框架,通过18项核心能力维度对大模型与任务进行双向量化评分。该方法能构建模型能力画像,以约88%的准确率预测未知任务表现,并精准定位模型失败原因,有效弥补传统基准测试缺乏解释性与预测力的缺陷。
入选理由:ADeLe将模型与任务映射至18项核心能力维度(0-5分),实现需求与能力的结构化对齐。
本文介绍 Spring AI 全新 Session API,采用事件溯源架构管理短期对话记忆,通过“轮次”原子化保障工具调用完整性,并提供可组合的上下文压缩触发器与策略,解决传统 ChatMemory 粗暴截断导致的上下文断裂问题,为多智能体协作提供结构化记忆底座。
入选理由:采用事件溯源日志替代扁平消息列表,以“轮次”为原子单位管理上下文,彻底避免工具调用序列被截断导致的模型幻觉。
Next.js 团队分享了将 AI Agent 视为一等公民的架构演进历程。通过废弃内置浏览器 Agent,转向基于 MCP 协议暴露框架内部状态,并引入结构化日志、agents.md 和 Next.js Skills,从根本上解决了 Agent 调试盲区与上下文缺失问题,为 AI 原生开发框架设计提供了新范式。
入选理由:AI Agent 调试需突破浏览器盲区,Next.js 通过 MCP 协议将运行时错误、路由与组件状态结构化暴露给外部 Agent。
Next.js 16.2 正式发布稳定的 Adapter API,通过定义类型化、版本化的构建输出契约,联合 OpenNext 及主流云厂商解决多实例部署下的缓存同步与流式渲染难题,并开源 Vercel 官方适配器以统一跨平台部署标准。
入选理由:Next.js 16.2 推出稳定版 Adapter API,提供类型化构建输出契约,消除跨平台部署的配置黑盒。
KernelEvolve将底层算子优化转化为LLM驱动的自动化搜索问题,通过闭环评测反馈,数小时内完成专家数周的手动调优。 系统支持NVIDIA/AMD/MTIA/CPU等异构硬件,自动生成Triton/CUDA等高性能Kernel,大幅提升模型吞吐。 Agentic编码方案打破人工调优瓶颈,为应对AI模型与硬件快速迭代的大规模基础设施优化提供可复用工程范式。
入选理由:KernelEvolve将底层算子优化转化为LLM驱动的自动化搜索问题,通过闭环评测反馈,数小时内完成专家数周的手动调优。
针对大型复杂代码库,采用多智能体预计算引擎提取隐性知识,比直接让AI扫描代码更高效准确。 AI上下文文件应遵循“指南针而非百科全书”原则,控制篇幅并聚焦关键路径、隐式规则与交叉引用。 构建自维护的知识层与自然语言路由机制,可显著降低AI工具调用开销,并实现与底层大模型的解耦。
入选理由:针对大型复杂代码库,采用多智能体预计算引擎提取隐性知识,比直接让AI扫描代码更高效准确。
Cloudflare通过预填充与解码阶段分离的架构优化超大语言模型推理,显著降低首Token延迟并提升GPU利用率。
入选理由:采用预填充(prefill)与解码(decode)分离架构,使GPU资源按计算/内存需求独立优化
Vercel提出“Agentic Infrastructure”概念,指出AI编码代理正驱动新一代基础设施演进,30%部署已由代理发起。
入选理由:超30%的Vercel部署由编码代理发起,半年增长1000%
AI工具处理简单编码任务效果显著,但开发者仍依赖人类社区解决复杂问题,尤其重视评论中的上下文与经验。
入选理由:AI擅长处理基础编码任务,但难以应对高难度、上下文敏感的技术问题。
大众点评 M 站通过 Qwik.js 重构,利用其 Resumability 特性消除水合开销,显著提升弱网下首屏加载速度与流量转化率。
入选理由:Qwik 的 Resumability 设计跳过传统 SSR 水合过程,实现按需加载交互逻辑
美团通过自动语义与增强计算构建新一代BI架构,解决数据口径混乱与查询性能问题,支撑百万级查询和百余业务线。
入选理由:自动语义实现“定义即研发”,将业务语言自动转为逻辑模型并关联数仓表
美团开源原生多模态模型LongCat-Next,通过离散Token统一建模视觉、语音与文本,实现理解与生成的对称架构。
入选理由:提出DiNA架构,用统一自回归模型处理多模态信号,打破模态割裂
美团开源 LongCat-Flash-Prover,通过自动形式化、草稿生成和证明生成三阶段框架,在定理证明基准上刷新开源模型纪录。
入选理由:将定理证明拆解为自动形式化、草稿生成、证明生成三个原子能力
Node.js 团队为 V8 设计了一种抗 HashDoS 攻击且可快速逆向的整数哈希函数,兼顾安全性与性能优化需求。
入选理由:HashDoS 利用哈希碰撞使服务拒绝,对 Node.js 等服务端运行时威胁显著
Visual Studio 2026 新增自定义 Copilot 代理功能,支持团队工作流定制、可复用技能及语言感知的符号导航工具。
入选理由:通过 .agent.md 文件可在仓库中定义自定义 Copilot 代理,集成内部工具与知识源。
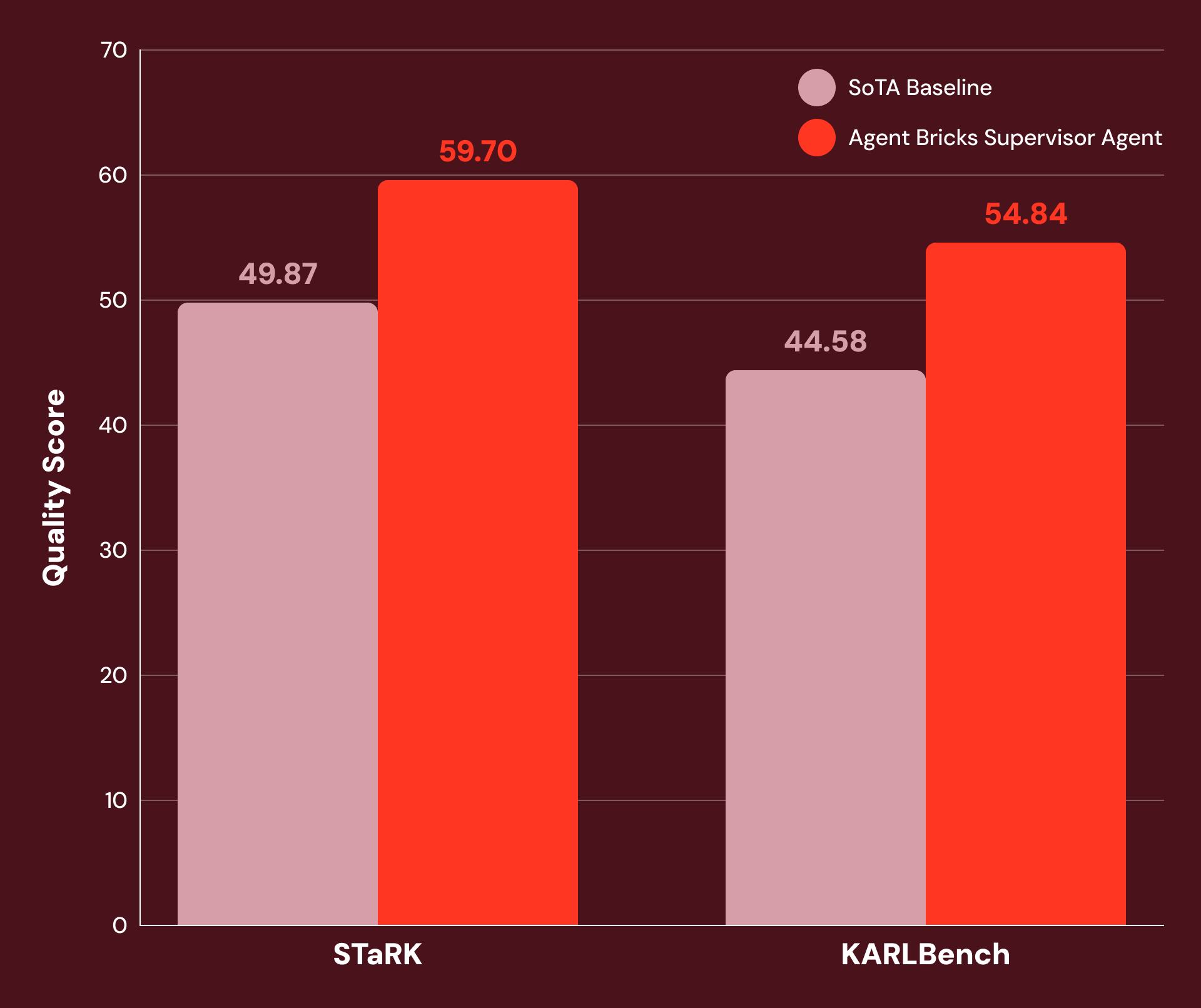
Databricks 展示其 Supervisor Agent 如何通过混合结构化与非结构化数据实现企业级多步推理,在 STaRK 和 KARLBench 基准上显著超越现有方法。
入选理由:Supervisor Agent 在多个企业级推理任务中比当前最优基线提升 20%+
文章详解如何使用 Sentence Transformers 微调多模态嵌入与重排序模型,并以视觉文档检索任务为例展示显著性能提升。
入选理由:微调多模态嵌入模型可显著提升特定任务(如视觉文档检索)的检索效果
蚂蚁灵波开源LingBot-Map,实现纯自回归流式3D重建,突破实时性、精度与显存限制,适用于机器人、自动驾驶等场景。
入选理由:提出几何上下文注意力机制,实现选择性记忆,显著降低显存消耗
文章通过真实案例揭示数据质量问题的严重后果,系统梳理常见数据错误类型及开发者应构建的多层验证机制。
入选理由:数据错误可导致数亿美元损失,如Knight Capital和Target的失败案例
文章系统对比了REST、gRPC和事件驱动三种服务间通信模式,在延迟、耦合、调试等五个维度分析其权衡,并提供选型决策框架。
入选理由:REST适合公共API和通用场景,生态成熟但性能一般
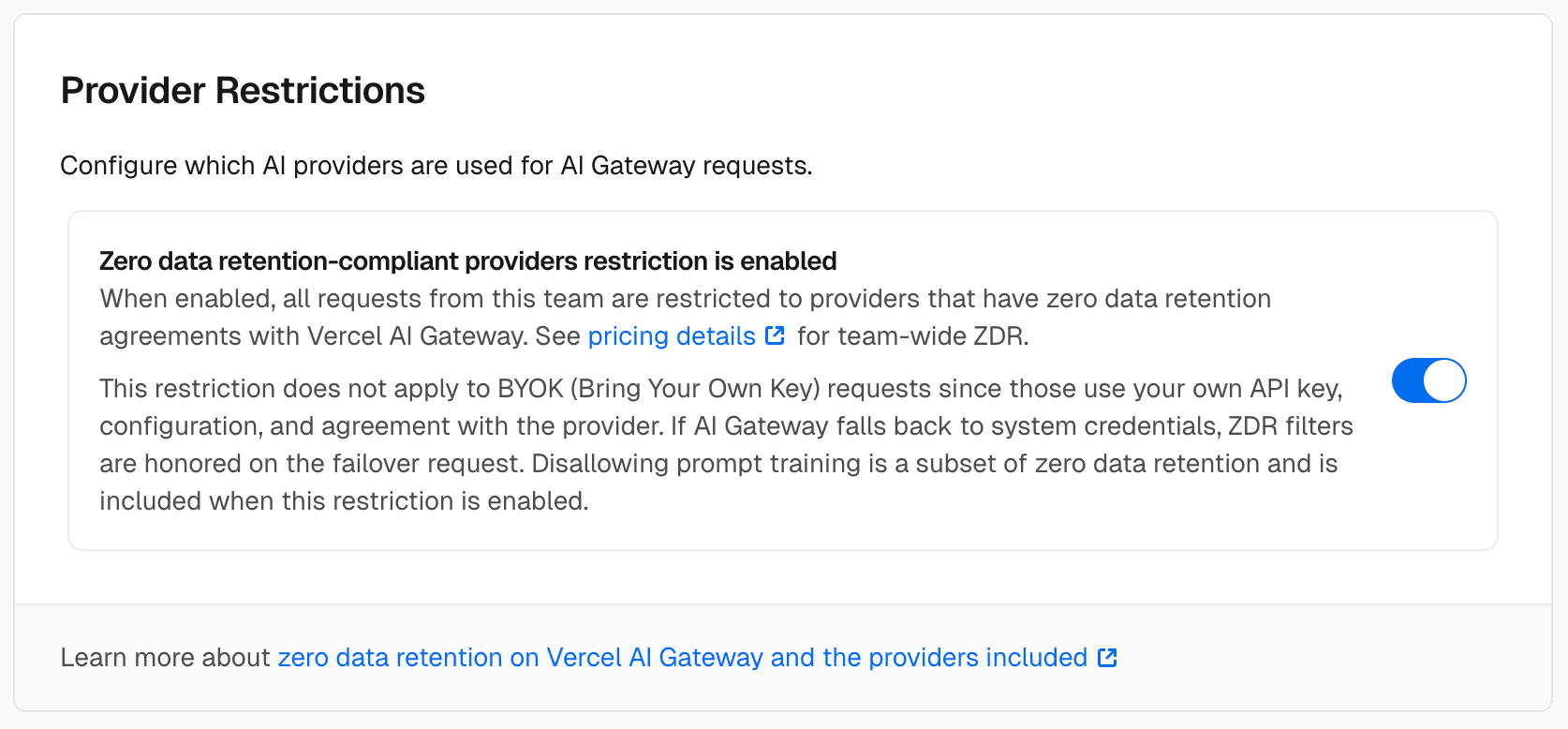
Vercel AI Gateway 推出团队级零数据保留(ZDR)功能,自动路由至合规提供商,无需代码即可强制执行数据策略。
入选理由:AI Gateway 自动路由请求至支持零数据保留(ZDR)的模型提供商,简化合规管理。
文章详解 React.lazy 和 Next.js 的 next/dynamic 实现懒加载,提升应用性能与核心 Web 指标。
入选理由:React.lazy 配合 Suspense 可实现组件级代码分割,减少首屏加载体积
本文针对Agentic AI开发中“黑盒”与“日志轰炸”的透明度困境,提出“决策节点审计”与“影响/风险矩阵”方法。通过映射后端逻辑与前端交互,指导工程师与设计师精准识别需向用户暴露的关键决策时刻,以平衡系统自主性与用户信任。
入选理由:Agentic AI透明度设计应避免“完全黑盒”与“全量日志”两极,需根据任务阶段精准暴露关键信息。
微软研究院提出GroundedPlanBench基准与V2GP框架,解决视觉语言模型在机器人长程任务规划中因自然语言歧义导致的执行失败问题。该框架将演示视频转化为空间锚定训练数据,实现动作规划与空间定位的联合学习,在基准测试与真实机器人实验中显著提升了任务成功率与动作精度。
入选理由:传统VLM机器人规划将动作生成与空间定位解耦,易因自然语言歧义引发长程任务失败。
JetBrains 官方详解如何通过 Git 底层 plumbing 命令优化 IDE 中的交互式 rebase 性能。文章深入剖析 Git 对象模型与索引机制,提出在内存中直接构建提交树、避免操作工作区与 index 的优化方案,显著提升了大仓库下的 rebase 速度。
入选理由:传统 IDE 集成 Git 依赖 porcelain 命令,在大仓库中易因频繁读写 index 和工作区导致 rebase 性能瓶颈。
JetBrains研究团队基于800名开发者两年的IDE遥测数据与访谈,揭示AI编程助手如何重塑开发工作流。研究发现AI实际改变了时间分配与操作习惯,但开发者主观感知常与客观行为存在偏差,为团队效能评估与AI工具落地提供实证参考。
入选理由:AI编程助手已深度融入日常开发,显著降低样板代码编写与重复性任务耗时。
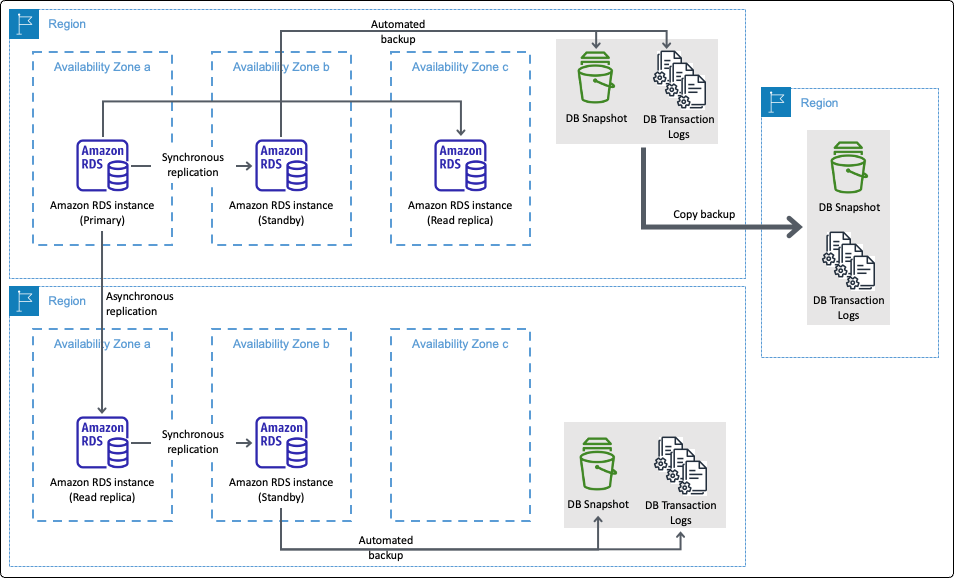
本文基于AWS架构最佳实践,采用“积木式”方法详解云上灾备方案。文章涵盖跨Region/跨账号恢复策略、AWS Backup数据保护、AWS DRS计算层容灾,并引入Arpio实现全栈自动化恢复,为工程师构建高可用云架构提供清晰路径。
入选理由:灾备需遵循责任共担模型,跨Region保障区域级故障隔离,跨账号构建“净室”环境以防御勒索软件。
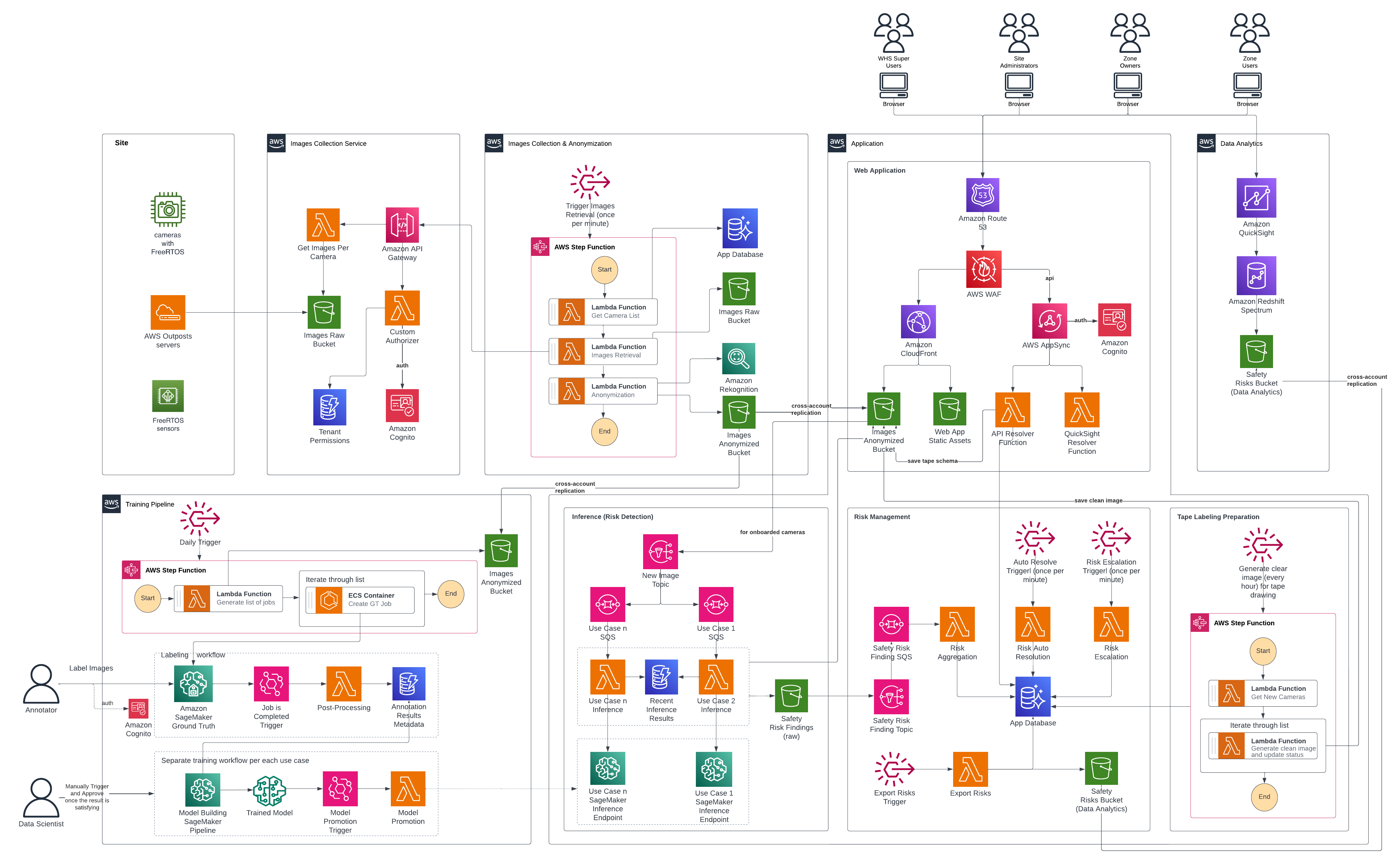
本文介绍了一种基于计算机视觉与生成式AI的无服务器安全监控架构,通过双检测标注、合成数据生成(GLIGEN)及多账户隔离设计,实现跨厂区PPE合规与危险区域的近实时自动化监测,为工业级CV系统规模化落地提供工程实践参考。
入选理由:采用无服务器事件驱动架构与多AWS账户隔离,实现千级摄像头数据的高效处理与安全权限管控。
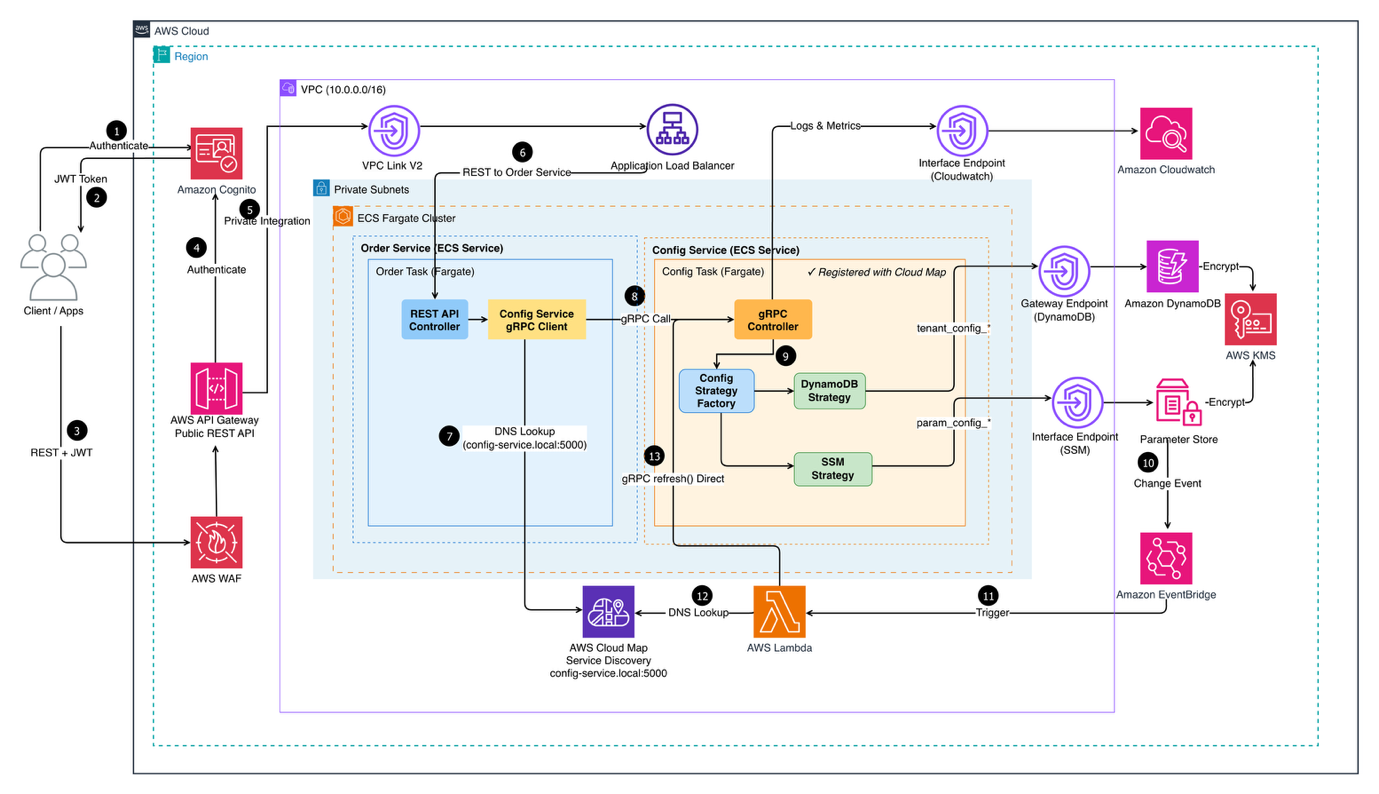
本文介绍了一种基于“标签化存储模式”的多租户配置系统架构,通过键前缀自动路由至 DynamoDB 或 SSM Parameter Store,结合策略模式、JWT 租户隔离与 EventBridge 事件驱动机制,有效解决缓存 TTL 与数据实时性冲突,实现高性能、零停机配置更新。
入选理由:采用键前缀标签化路由策略,可动态将不同访问特征的租户配置分发至 DynamoDB 或 Parameter Store,兼顾性能与运维成本。
37signals宣布Basecamp全面转向“Agent可访问”架构,放弃直接嵌入AI功能,转而通过重构API、提供CLI及支持MCP协议,使AI智能体能够直接调用Basecamp所有功能。文章指出Agent是AI的杀手级应用,将大幅降低SaaS集成门槛,并预测该模式将快速普及至主流AI平台。
入选理由:SaaS产品应从“AI功能内嵌”转向“Agent可访问”架构,通过标准化API与CLI赋予智能体完整操作权限。
Next.js 16.2 为 Turbopack 引入服务端细粒度热更新,通过模块图精准重载使刷新提速 67%-100%;新增动态导入 Tree Shaking、SRI 安全校验及 Web Worker 源修复,显著提升开发体验与构建安全性。
入选理由:服务端热更新改为基于模块图的精准重载,避免全量清除缓存,编译与刷新速度提升数倍。
Next.js 16.2 针对 AI 编程代理推出多项改进,默认集成 AGENTS.md 提供本地版本匹配文档,支持终端转发浏览器日志与锁文件防冲突,并推出实验性 Agent DevTools CLI,使 AI 代理无需浏览器即可深度调试与检查应用状态。
入选理由:create-next-app 默认生成 AGENTS.md,通过本地捆绑文档替代外部检索,显著提升 AI 代理代码生成准确率。
2025年欧洲数据泄露激增近50%,德国因AI自动化本地化攻击、英美目标防御增强及勒索软件生态重组,成为网络勒索新焦点,泄露量同比暴涨92%。文章结合GTI数据剖析攻击者转向德国中型企业的动因,并提示公开泄露站点数据需结合谈判策略综合研判。
入选理由:AI驱动的自动化本地化正打破语言壁垒,使非英语国家成为勒索软件新目标。
Google Cloud 正式发布 Gemini 3.1 Flash TTS 模型,支持 70+ 语言与 SynthID 水印。文章详细讲解了基于 200+ 内联音频标签的提示词框架,涵盖语速、情感与非语言发声的精准控制语法,为开发者构建高表现力语音应用提供实操指南。
入选理由:模型支持通过自然语言指令与 200+ 内联音频标签实现细粒度语音风格与节奏控制。
本文详细拆解了 Spotify 每周向 6.75 亿用户发布更新的工程实践。通过主干开发、周五固定切分支、自动化指标监控与分级灰度发布的组合机制,实现了研发速度与发布安全的平衡,为大规模客户端持续交付提供了可落地的参考架构。
入选理由:采用主干开发与每周固定切分支机制,隔离新功能开发与发布稳定分支,兼顾迭代速度与版本质量。
本文解析了LinkedIn如何将Feed推荐系统从五个异构检索架构重构为基于大语言模型的统一双编码器向量检索系统,在保障13亿用户50毫秒延迟的同时,通过语义向量匹配显著提升了内容推荐的精准度与系统可维护性。
入选理由:LinkedIn废弃多套独立检索管线,采用LLM双编码器架构将用户与内容映射至统一向量空间,实现全局优化。
多智能体系统应从最简单模式起步,根据实际瓶颈逐步升级,避免盲目追求复杂架构。 生成-验证者模式需明确定义评估标准并设置循环上限,否则易陷入无效迭代或质量失控。 调度模式易成上下文瓶颈,团队模式需防范资源冲突,选型应严格匹配任务依赖与并行需求。
入选理由:多智能体系统应从最简单模式起步,根据实际瓶颈逐步升级,避免盲目追求复杂架构。
AI优先战略的本质是软件工程优先,落地需先夯实自动化测试、CI/CD流水线、线上监控、任务拆解与系统架构五大基础。 真正的AI优先需重构研发流程,将AI作为主力构建者,工程师转向脚手架工程负责指引、约束与质量兜底。 AI优先仅适用于后端驱动、快速试错或内部工具场景,UI密集、质量敏感及高安全要求场景仍需人工深度介入。
入选理由:AI优先战略的本质是软件工程优先,落地需先夯实自动化测试、CI/CD流水线、线上监控、任务拆解与系统架构五大基础。
面对百万级上下文,需根据任务阶段灵活选用继续、回溯、清空、压缩或子智能体,以规避上下文衰减导致的模型失焦。 纠正AI错误时应优先使用回溯功能退回关键节点重新引导,避免在错误路径上堆砌提示词,从而节省Token并提高成功率。 长会话应主动压缩或新建以防关键信息被丢弃;涉及大量中间过程的任务宜交由子智能体处理,主会话仅接收最终结果。
入选理由:面对百万级上下文,需根据任务阶段灵活选用继续、回溯、清空、压缩或子智能体,以规避上下文衰减导致的模型失焦。
v4将destinations配置从列表改为映射结构,彻底解决GitOps覆盖与多文件合并时的配置丢失问题。 移除硬编码的Collector名称,支持按业务需求灵活定义Alloy实例类型与部署拓扑,提升多集群可维护性。 该版本针对大规模监控场景优化,通过结构化配置降低Helm Values管理复杂度,推荐生产环境升级。
入选理由:v4将destinations配置从列表改为映射结构,彻底解决GitOps覆盖与多文件合并时的配置丢失问题。
将文档测试转化为监控问题,利用AI Agent模拟零基础新用户逐字执行教程,可精准发现隐性知识缺失与环境漂移。 构建文档验证Agent需具备无知、字面执行与严格校验特性,并结合Dev Containers确保测试环境与用户环境一致。 基于Copilot CLI、Actions与Playwright搭建自动化流水线,通过定制System Prompt实现教程的持续集成与快速反馈。
入选理由:将文档测试转化为监控问题,利用AI Agent模拟零基础新用户逐字执行教程,可精准发现隐性知识缺失与环境漂移。
针对广告推荐场景的亚秒级延迟与成本约束,Meta提出自适应排序模型,通过请求级智能路由动态匹配模型复杂度,打破推理扩展瓶颈。 采用模型与底层硬件协同设计,结合多卡GPU服务架构突破单卡内存限制,实现万亿参数模型的高效部署与35%的MFU利用率。 该架构在Instagram上线后实现广告转化率提升3%、点击率提升5%,验证了LLM规模模型在实时推荐系统中兼顾性能与ROI的可行性。
入选理由:针对广告推荐场景的亚秒级延迟与成本约束,Meta提出自适应排序模型,通过请求级智能路由动态匹配模型复杂度,打破推理扩展瓶颈。
投机解码通过小模型预生成多Token并由大模型单次验证,显著降低KV Cache内存往返次数,提升硬件利用率。 需选择同词表且架构相近的草稿模型以保证高接受率,并通过调节num_speculative_tokens平衡草稿计算与验证开销。 在AWS Trainium2结合vLLM部署模型时,该技术可使解码密集型负载的Token间延迟降低最高达3倍。
入选理由:投机解码通过小模型预生成多Token并由大模型单次验证,显著降低KV Cache内存往返次数,提升硬件利用率。
VAKRA基准通过8000+本地API与62个领域数据库,构建可执行的企业级智能体评测环境,重点考察多步组合推理与工具调用能力。 现有大模型在VAKRA上表现普遍不佳,主要失败模式集中在API参数错误、多步逻辑断裂及非结构化文档检索偏差。 该基准为智能体开发提供可量化的调试依据,建议工程团队引入执行轨迹分析与细粒度错误归因,以优化工具链架构。
入选理由:VAKRA基准通过8000+本地API与62个领域数据库,构建可执行的企业级智能体评测环境,重点考察多步组合推理与工具调用能力。
Cloudflare 推出 AI Search,为智能体提供开箱即用的混合检索能力,支持动态创建实例、内置存储与向量索引,并可按客户或任务隔离上下文。
入选理由:AI Search 支持语义与关键词混合检索,结果自动融合
Cloudflare 推出统一 AI 推理层,支持通过单一 API 调用 70+ 多模态模型,简化多供应商管理并优化成本与可靠性。
入选理由:通过 AI.run() 单一接口可无缝切换 12+ 供应商的 70+ 模型
Waldium 构建了一个同时服务人类和 AI 的博客平台,通过 MCP 协议为每个客户博客提供专属 AI 查询端点,并基于 Vercel 实现高效低成本的多租户部署。
入选理由:内容消费主体已扩展至 AI 智能体,需原生支持 MCP 协议供其直接查询
Cursor 通过 Vercel 微前端统一四个网站,并结合 Flags 和实验工具构建快速迭代的增长闭环。
入选理由:使用微前端在不中断核心流程的前提下统一多站点体验
AI正加速漏洞发现与利用,企业需通过AI驱动的自动化防御体系应对机器速度级威胁。
入选理由:AI大幅降低漏洞挖掘与利用门槛,使零日攻击更频繁、更快速
AI将重塑而非取代SOC分析师工作,人类在上下文理解、创造性应对和危机决策中不可替代。
入选理由:AI缺乏理解业务上下文的能力,无法判断异常是否真实威胁
MongoDB通过机器学习实验验证了预测性自动扩缩容的可行性,现已在Atlas中上线仅支持预扩容的版本。
入选理由:预测性扩缩容可提前应对负载高峰,减少性能延迟和成本浪费。
文章详解如何使用 jsPDF 库在浏览器中纯前端生成 PDF,以发票为例展示完整实现流程。
入选理由:可使用 jsPDF 库在浏览器端无需后端直接生成 PDF 文件
本文详述农业机器人公司Aigen如何将本地机器学习流水线迁移至AWS云原生架构。通过结合IoT边缘数据回传、视觉基础模型集成与主动学习实现自动化标注,并利用SageMaker多GPU分布式训练解决算力瓶颈,最终实现标注吞吐量提升20倍、成本降低22.5倍,为边缘AI规模化落地提供可复用的架构范式。
入选理由:采用视觉基础模型集成与主动学习构建自动化标注流水线,可大幅降低边缘场景数据标注成本并提升吞吐量。
文章对比了AI Agent接入业务数据的三种架构:直连数据库(快但易错)、构建静态语义层(准但维护重)以及自动化语义层(按需生成指标+人工Git审核)。指出在速度与可靠性间取得平衡的最佳实践是引入“人在回路”的自动化语义层,以解决冷启动与指标一致性问题。
入选理由:直连数据库虽部署快,但缺乏统一指标定义,易产生幻觉,仅适合数据团队内部验证。
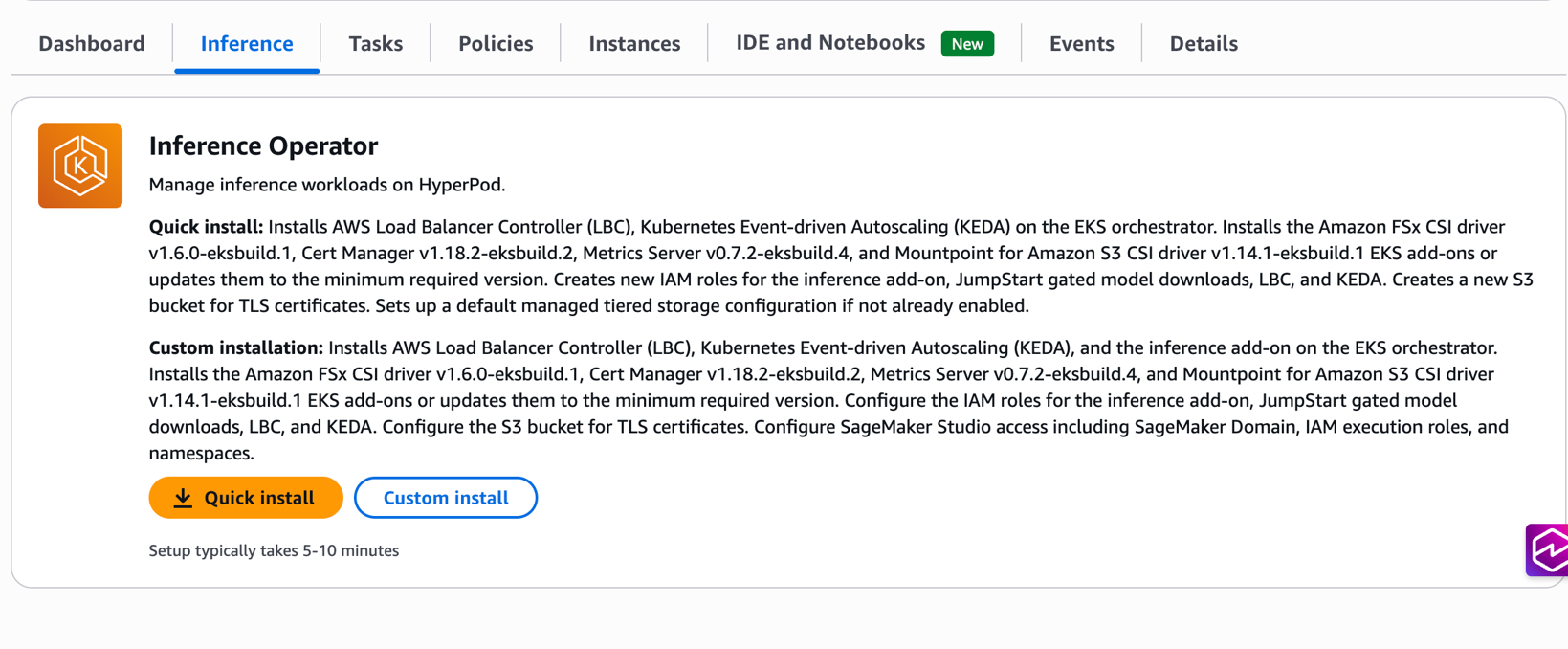
AWS将SageMaker HyperPod推理控制器升级为原生EKS插件,提供一键安装、自动配置IAM与依赖组件及无缝升级能力,大幅简化K8s集群上的大模型推理部署与运维流程。
入选理由:推理控制器现作为EKS原生插件,支持控制台一键安装与自动依赖配置,免去手动编写Helm图表与复杂IAM设置。
Next.js 16.2 发布,重点优化开发体验与渲染性能。通过改进 React Server Components 的 JSON 反序列化机制,渲染速度提升最高 60%;开发服务器启动提速约 400%。新增服务端函数日志、水合差异指示器及生产环境调试支持,并强化 AI Agent 开发工具链。
入选理由:开发服务器启动提速约 400%,渲染性能因优化 JSON 反序列化机制提升最高 60%。
文章深入剖析了Figma基于MCP协议实现“设计转代码”与“代码转设计”的底层机制,对比了截图识别与全量REST API的局限性,揭示了AI Agent在精准还原UI与处理上下文过载时的工程挑战及MCP的破局思路。
入选理由:截图转代码依赖像素猜测,无法获取精确样式值,难以满足复杂UI的还原需求。
美团技术团队推出 LongCat-Flash-Thinking-2601 模型,结合 OpenClaw 实现本地 AI Agent 自动化,任务平均提速 30%,并提供合规 API 规避第三方调用风险。
入选理由:LongCat 模型在 OpenClaw 上平均任务耗时 2.35 分钟,效率提升约 30%。
IDC研究显示,AI成功关键在于克服遗留技术与数据债务,现代化基础设施的企业数字收入达同行3倍。
入选理由:AI成效高度依赖底层技术栈与数据质量,非仅靠投入多少