[AINews] 所有模型实验室现在都是智能体实验室
![[AINews] 所有模型实验室现在都是智能体实验室](/api/img-proxy?url=https%3A%2F%2Fsubstackcdn.com%2Fimage%2Ffetch%2F%24s_!TLyU!%2Cw_1456%2Cc_limit%2Cf_auto%2Cq_auto%3Agood%2Cfl_progressive%3Asteep%2Fhttps%253A%252F%252Fsubstack-post-media.s3.amazonaws.com%252Fpublic%252Fimages%252F348d0573-16b0-46d0-a852-ccaae2b6ff4f_1122x534.png)
TL;DR · AI 摘要
主流大模型公司正从纯模型研发转向构建‘模型+智能体+工作流’的完整产品体系,OpenAI、AI21、DeepSeek等均在组建Agent/Harness团队,表明行业共识已从‘模型即产品’转向‘系统即产品’。
核心要点
- OpenAI 正通过 Codex Thursday #6 推出 appshots、/goal 改进、远程锁定计算机使用等新功能,强化其 coding-agent
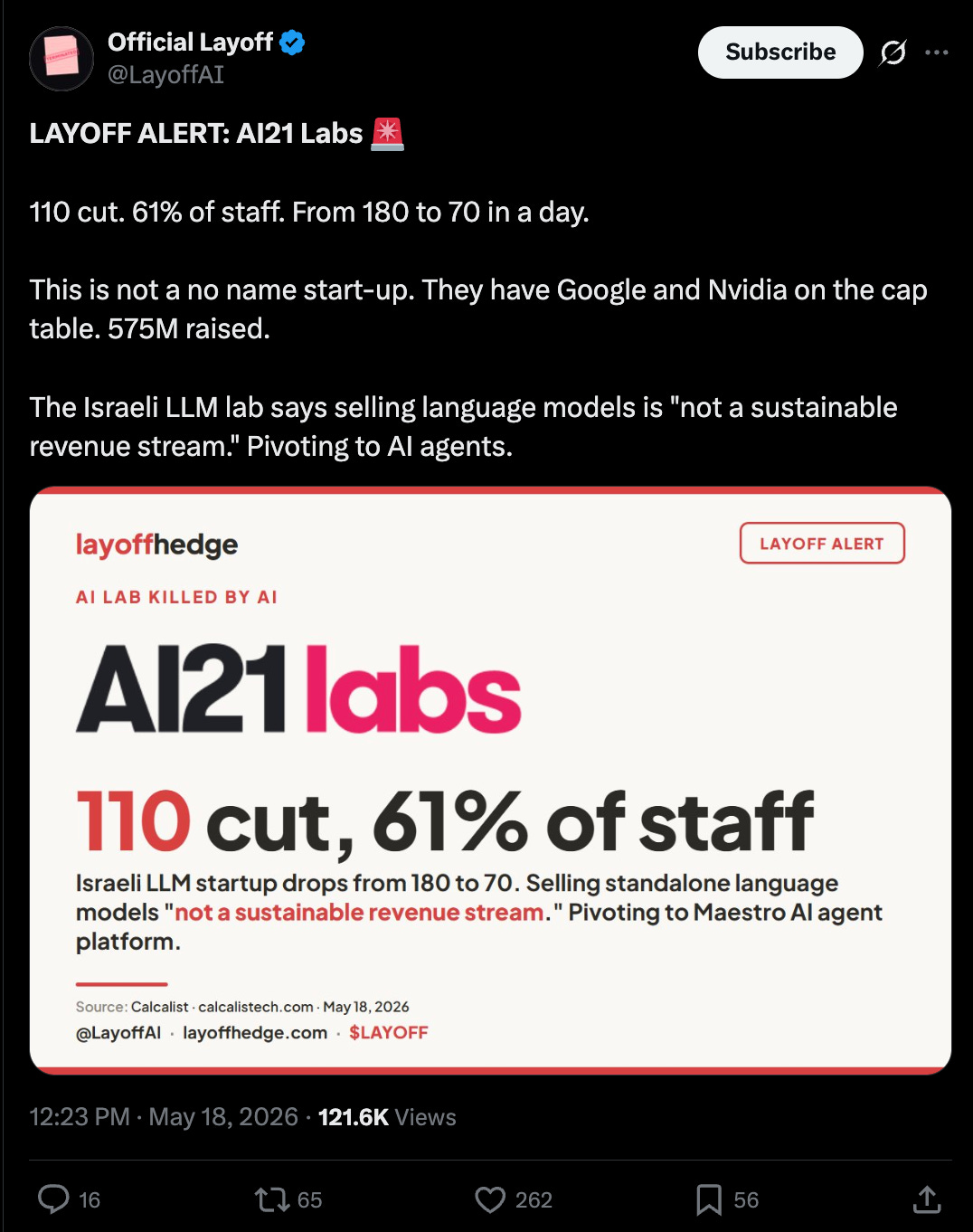
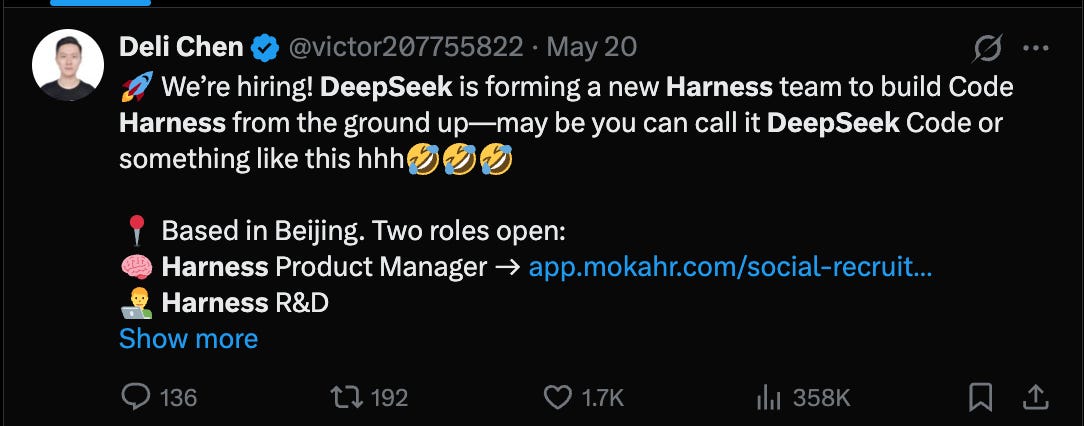
- AI21 已关闭其模型团队并全面转向 agent 产品线,DeepSeek 首次设立‘Harness 团队’,标志行业范式转移加速。
- 行业共识认为:模型 alone 不再是护城河,成功产品需模型、harness、workflow、UI、memory 和 economics 六要素协同(@gdb
结构提纲
按章节快速跳转。
模型质量本身已非核心壁垒,产品竞争力取决于模型+harness+workflow+UI+memory+经济模型的系统级协同。
OpenAI 最新 Codex 更新包含 appshots、/goal 增强、远程锁定计算、注解模式、插件共享与分析功能,体现具体产品演进路径。
AI21 关闭模型团队、DeepSeek 首设 Harness 团队,反映企业资源与人才配置正向 agent 架构倾斜。
模型与 harness 协同训练可能加剧模型封闭化,削弱 API 合作生态,引发 open vs. closed 的长期博弈。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- Model Labs → Agent Labs 转型趋势
- 行业动因
- 模型同质化加剧
- 产品护城河上移
- 代表案例
- OpenAI:Codex 功能迭代
- AI21:关闭模型团队
- DeepSeek:首设 Harness 团队
- 产品新范式
- 模型 + harness + workflow
- UI + memory + economics 协同
- 深层矛盾
- 封闭模型 vs 开放 API
- 合作与竞争(co-opetition)
金句 / Highlights
值得收藏与分享的关键句。
‘模型本身已不再是产品’ — @gdb 明确指出模型已从产品主体降级为系统组件。
OpenAI Codex 更新包含 appshots、/goal 改进、远程锁定计算机使用、annotation mode、plugin sharing 和 analytics 六大功能。
AI21 已关闭其模型团队并全面转向 agent 产品线,DeepSeek 首次设立‘Harness team’,标志行业范式转移加速。
模型与 harness 协同训练虽提升 agent 性能,但也可能使模型厂商通过‘专属微调’限制第三方接入,加剧生态封闭。
标题:[AINews] 所有模型实验室现在都转型为智能体(Agent)实验室
来源链接:https://www.latent.space/p/ainews-all-model-labs-are-now-agent
发布时间:2026-05-23T04:21:17+00:00
Markdown 内容:
就在 OpenAI 可能于下周提交首次公开募股(IPO)申请之际,Greg 发表了其系列言论中的最新一次表态——模型实验室正日益转向构建智能体(Agents),并将之作为核心产品方向:
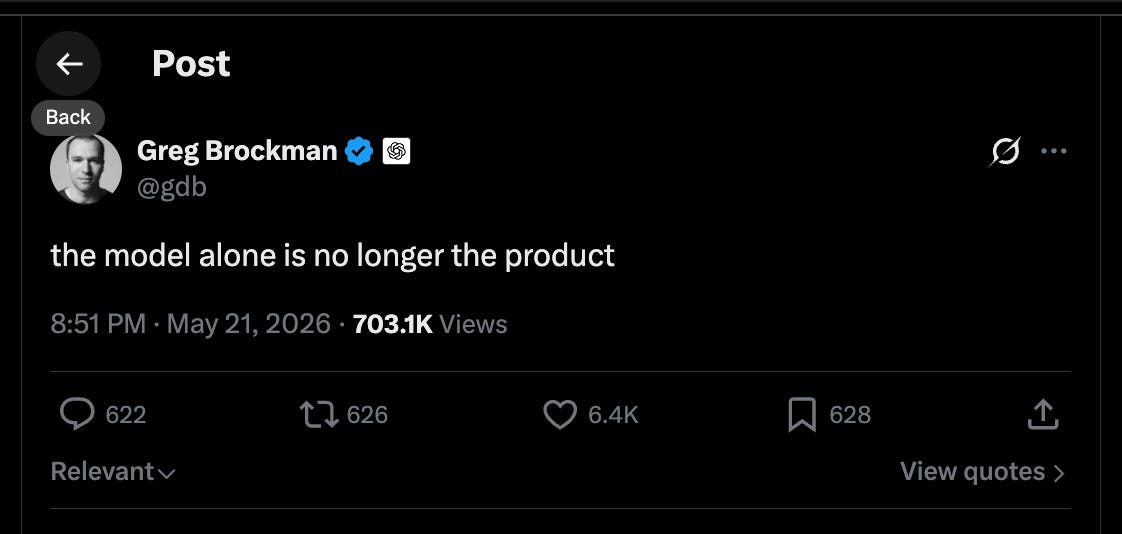
该言论标志着其立场发生了重大转变——此前,几乎所有曾任职于 [大模型团队(Team Big Model)](https://www.latent.space/p/oai-v-langgraph?utm_source=publication-search) 的人都持统一观点,包括他此前领导 OpenAI 实验室的负责人:
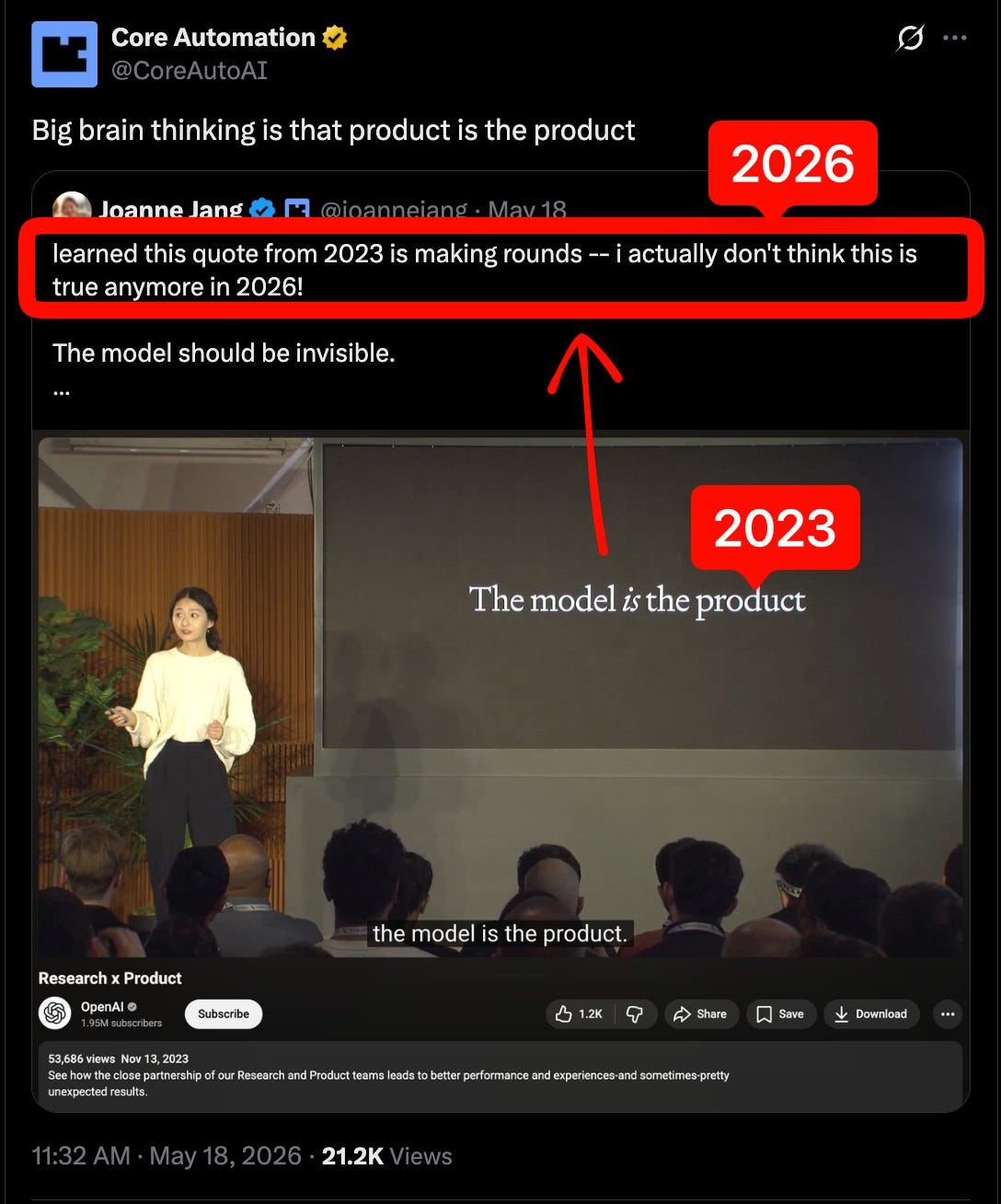
这一转变也伴随着 AI21 的模型团队关闭,该公司现已转向聚焦智能体方向:
就连久负盛名的 DeepSeek 也首次成立了专门的“支撑系统(Harness)团队”:
“系统优先于模型(Systems over Models)”派系将此视为对其长期主张的有力佐证…… 但需注意一个关键细节:若模型与支撑系统协同训练,反而可能进一步限制模型的开放访问——一旦你能有效对模型进行后训练(posttrain),使其仅在你的闭源智能体中才能发挥真正价值,那么你便能将绝大多数用户引导至你的智能体,从而牺牲模型/API 的“合作与竞争并存”(co-opetition)关系。
但这已属于更宏大议题的范畴……
2026 年 5 月 4 日至 5 月 5 日 AI 新闻汇总。我们监测了 12 个 Reddit 社区、544 个 Twitter 账号,未包含 Discord 讨论。您可通过 AINews 网站 搜索所有往期内容。提醒一下,AINews 现已并入 Latent Space 栏目。您可随时订阅/退订邮件推送频率!
智能体产品、支撑系统,以及超越“仅模型”的范式迁移
- 产品形态正向上游迁移:一个反复出现的主题是,模型性能本身已不再是护城河;真正胜出的产品正日益成为 模型 + 支撑系统 + 工作流 + 用户界面 + 记忆机制 + 经济模型 的组合体。@gdb 直言不讳:“模型本身已不再是产品”;而 @dzhng 则指出,顶级产品必须实现 模型 ↔ 支撑系统 ↔ 产品之间的协同共生。这一趋势在实践中亦有体现:@signulll 将环境式 AI 与自主式 AI 视为新一代计算接口的突破口;@teortaxesTex 则指出,支撑系统研究仍面临风险——最终可能趋同于“复刻 Claude Code”,而非探索更广泛的人机交互界面。
- 代码类智能体产品的差异化正逐步落地:OpenAI 通过 “Codex 周四第 6 号更新” 推出了另一轮重大 Codex 升级,新增功能包括:应用快照(appshots)、/goal 指令优化、锁定状态下远程电脑使用、标注模式、插件共享、以及分析仪表盘。@gdb 单独强调了 Appshots 功能;用户也报告了显著的工作流变革:@gdb 表示“已难以回忆起 Codex 之前是如何编程的”,@reach_vb 则称自己已超过一个月未打开过 IDE。但产品体验仍存瑕疵:@theo 赞扬 T3 Code 的远程功能领先于竞品,随后在后续帖子中对比指出 Codex 的远程工作流存在明显 Bug。在 Claude 方面,@ClaudeDevs 将 自动模式(auto mode) 扩展至 Pro 订阅计划,并新增 Sonnet 4.6 模型支持;@_mohansolo 则需在用户强烈反馈后紧急澄清并修复 Antigravity 2.0 的 IDE 兼容性问题。
模型性能、成本曲线与前沿竞争格局
- DeepSeek 的定价策略是迄今为止最强烈的市场信号:@deepseek_ai 将 DeepSeek-V4-Pro 的 75% 折扣永久化,引发强烈反响,因其实质性地改变了 成本/性能边界。@ArtificialAnlys 估算其官方定价为 $0.435/M 输入 token、$0.87/M 输出 token、$0.0036/M 缓存输入 token,综合成本约为 $0.18/M,使 V4 Pro 在“智能水平 vs 运行成本”维度上位于帕累托前沿。他们估计,使用 V4 Pro 运行其 Intelligence Index 的成本约为 Gemini 3.1 Pro Preview 的 1/3、GPT-5.5 的 1/12、Claude Opus 4.7 的 1/19。社区普遍聚焦于 DeepSeek 推出的“智能便宜到难以计量”(“intelligence too cheap to meter”)愿景,如 @scaling01 所言。@Yuchenj_UW 与 @kimmonismus 均强调此次降价幅度之大。
- Gemini Flash 性能有所提升,但用户反馈褒贬不一:@OfficialLoganK 报告称 Gemini 3.5 Flash 在 GDPval 指标上大幅超越 3.1 Pro,称其已“跻身前沿模型行列”;@Designarena 将其排在 Design Arena 总榜第 16 名,较 Gemini 3 Flash Preview 的排名 跃升 16 位。但多位开发者对实际效用提出质疑:@Alezander907 发现其在浏览器代理任务中仅带来微弱改进,但成本更高;@giffmana 认为若“Flash”标签仍意味着廉价定位,则不能算真正进步;@jeremyphoward 指出该模型似乎被优化用于 最大化评测指标,而非与人类协作。这与 @HamelHusain 对当前评测体系的普遍质疑相呼应——其认为现有工具过度依赖量化指标,而低估了定性判断与人类-交互式学习(HITL)的价值。
- 通义千问与国产大模型持续拉近与国际前沿的距离:@Alibaba_Qwen 的官方预热与 @ZhihuFrontier 的第三方长文评测均指出,Qwen3.7-Max 在 指令遵循、上下文可靠性与稳定性 方面显著进步,但仍存在 冗长与高 token 消耗 问题。此外,@scaling01 称 ALE-Bench 最新测试显示,包括 Kimi-K2.6、DeepSeek-V4、GLM-5.1 在内的国产模型在该场景下已超越多个西方主流模型。@ArtificialAnlys 还报告称,Cursor Composer 2.5 在编码代理基准测试中成本仅为 Opus 4.7 的 1/3–1/18、GPT-5.5 的 1/5–1/32,且 token 使用量显著更低。
协议、基础设施与智能体运行时工具
- MCP 新版发布候选版实现了协议层面的重大简化:@dsp_ 宣布 MCP 2026-07-28 候选版,核心变更在于协议变为 无状态:无需握手、无会话 ID,任意请求可路由至任意服务实例。该候选版还引入了 原生扩展支持(如 MCP Apps 与 Tasks),并加强了认证机制、明确了弃用策略。对基础设施团队而言,无状态化是一次重大运营变革:更易扩展、负载均衡更简单、减少会话粘连问题。
- 沙箱与托管执行正成为核心基础设施原语:@_philschmid 展示了 Gemini 托管智能体 + 交互 API,为智能体提供安全托管的 Linux 沙箱环境,支持内存与代码执行。@CoreWeave 推出 CoreWeave 沙箱 公测版,面向强化学习(RL)、智能体工具调用与模型评测;@cnakazawa 发布 Cloudsail,支持为每项任务动态创建 Cloudflare 沙箱,提供 shell、Codex 与 GitHub 访问能力,且无需暴露敏感 token。在编排层,@skypilot_org 指出:现代 RL 无法在 Slurm 上有效运行,因其本质是多服务、异构硬件、需容错恢复的系统。
- 开源框架与记忆层生态快速扩张:@NVIDIAAI 开源了 AI-Q 智能体技能库,支持构建可移植的深度研究流水线,可接入任意框架。@Teknium 为 Hermes 增加 Bitwarden 密钥管理支持,并在 Hermes 中为 Grok Build v0.1 重新启用 256K 上下文长度(链接)。@shannholmberg 描述了 Hermes 智能体下的 共享内存“gBrain”层,支持类型化文件夹与“读优先”访问策略,便于专业智能体协作。@aakashadesara 更新了 CTOP,新增对 Devin 的支持,并提供 CLI 工具用于列出、搜索与终止智能体会话。
- 强化学习(RL)后训练与奖励设计正受到重新审视:@RyanBoldi 提出了向量策略优化(VPO),指出标量奖励在 RL 中的坍缩问题可能破坏模型在推理阶段的扩展能力。VPO 转而优化向量型奖励,即使在原始标量目标上也能显著提升搜索性能。@lateinteraction 将其解读为一种训练大语言模型以适应更多样化环境与目标的方法;而@FeiziSoheil 则将其与更广泛的“结构化反馈”趋势联系起来,即不再依赖单一标量奖励值。此外,@jsuarez 透露了一种针对长期存在的 RL 稀疏性难题的解决方案,初步实验已在某一内部环境中展现出当前最优(SOTA)性能。
- 智能体编译/蒸馏正成为一种具有现实经济意义的重要思路:@dair_ai 强调了一项研究:一个完整的智能体工作流(包括多步调用、工具使用、草稿本、决策结构等)可被蒸馏进模型权重中,并在推理阶段实现约 100 倍的成本降低,同时保持接近前沿模型的质量。这是迄今为止对“将高开销的运行时智能体循环编译为低成本可部署模型”这一方向最清晰的技术论证之一。
- 超越标准 Transformer 的架构研究依然活跃:@ChunyuanDeng 推出了 LT2——一种线性时间循环 Transformer,结合稀疏与线性注意力机制,使循环结构变得实用,并配套发布了蒸馏版 Ouro-hybrid-1.4B 模型。@ZyphraAI 分享了将平衡传播(Equilibrium Propagation) 从能量模型拓展至更具生物合理性的神经元模型的工作。在 MoE 方面,@Jianlin_S 提出了移动分位数平衡(Moving Quantile Balancing) 方法,实现序列级负载均衡且无损失惩罚。与此同时,@allen_ai 推出了 ArtifactLinker,该工具可在实际运行前预测模型最有可能在哪些基准测试中取得 SOTA——在基准测试日益泛滥的当下,这是一项极具实用价值的元评估工具。
- 数学与推理能力的讨论再次转向:@cozyblaze265065 报告称,使用 gpt-5.5(中等推理能力、未调用工具)在多位数乘法实验中达到了 99.46% 的准确率;而@teortaxesTex 指出,现代 LLM 已能在无工具辅助下完成百位数乘法运算。尽管这尚不能构成完整的推理理论,但它进一步削弱了“自回归模型无法完成算术运算”这类过时观点的说服力。
多模态系统:视频、语音、世界模型与成像
- 谷歌 I/O 技术栈聚焦于持久化智能体与世界模拟器:@Google 推出了 Gemini Spark——一款7×24 小时运行的个人 AI 智能体,用于处理重复性任务、技能与工作流。@GoogleDeepMind 同步发布了 Project Genie + 街景(Street View),允许用户将美国真实地点转化为交互式虚拟世界;后续推文确认该功能将通过 Google Labs 向 Google AI Ultra 订阅用户开放。多模态能力方面,@Google 宣布推出 Gemini Omni,支持对话式视频创作与编辑及自定义虚拟人像;而@emollick 则强调了全模态原生系统(可原生编辑视频)的重要意义。
- Runway 及图像/视频编辑工具持续提升可编辑性:@runwayml 发布了 Aleph 2.0,支持最长 30 秒、1080p 分辨率的多镜头序列生成,并能实现局部编辑,同时保持场景其余部分不变。@CuriousRefuge 推荐了 SeeDance 2 Stitcher,该工具可利用 Omni 生成的续段无缝拼接 AI 制作的电影级视频片段。
- 语音与图像生成取得显著进展:@ArtificialAnlys 在其 Speech Arena 中将 Cartesia Sonic-3.5 评为新的 #1 语音合成(TTS)模型,其 Elo 评分为 1218,支持42 种语言,且自然度与文本遵循能力表现强劲。Cartesia 宣称其生产环境中端到端首帧音频延迟低至 82 毫秒(详情)。在图像生成领域,@wildmindai 指出腾讯的 Z-Image 6B 是一款像素空间生成器,无需 VAE,支持 1K 分辨率,并具备将 Flux/SD 模型转换为自身格式的迁移框架;相关生态进展还包括:@victormustar 展示的 Pixal3D 演示,以及@ostrisai 在 AI Toolkit 中对 Z-Image L2P 1k 的训练支持。
安全、网络与政策压力
- 网络安全正迅速成为高级智能体的“试金石”:@AnthropicAI 表示,“Project Glasswing”项目及其合作伙伴在一个月内于关键软件中发现了逾一万条高危或严重级别漏洞,并明确警告业界:随着像 Claude Mythos Preview 这类模型所能发现的漏洞数量激增,整个行业必须随之调整适应。安全产品的商业化进程也已启动:@perplexity_ai 开源了 Bumblebee——一款仅读取、适用于 macOS/Linux 的扫描工具,用于检测高风险软件包、扩展插件及 AI 工具配置;@AravSrinivas 指出,企业级部署将依赖智能体沙箱环境与持续的安全工程实践。
- 美国移民政策调整引发 AI 领域领袖强烈反对:多条高互动量推文指出,一项拟议中的法规——要求绿卡申请人必须在美国境外提交申请——将直接冲击 AI 人才输送渠道。参见 @Nick_Davidov、@AndrewYNg、@theo、@garrytan 和 @togelius 的相关评论。核心观点一致:该政策惩罚的是合法高技能移民,损害初创企业与科研能力,并削弱美国在 AI 领域的全球竞争力。
高互动量热门推文(按互动量排序)
- @deepseek_ai 关于永久保留 V4-Pro 折扣 —— 本轮中最清晰体现 LLM 推理经济性 的单一市场信号。
- @gdb 关于“模型本身已不再是产品” —— 对当前 智能体/框架型产品理念 的精炼概括。
- @AnthropicAI 关于 Glasswing 发现 1 万+ 严重漏洞 —— 支撑 AI 驱动的网络攻防能力进入实战阶段 的最强实证之一。
- @dsp_ 关于 MCP 2026-07-28 RC —— 重要协议升级:引入无状态 MCP 与原生扩展支持。
- @GoogleDeepMind 关于 Project Genie + 街景 —— 向面向消费者的全局世界模型迈出的重要一步。
- @cursor_ai 关于开放 Cursor SDK 以支持自定义智能体 —— 对构建在代码智能体基础设施之上的团队具有重要参考价值。