在 Amazon Bedrock 上实现程序化工具调用

TL;DR · AI 摘要
AWS Bedrock 现在支持程序化工具调用(Programmatic Tool Calling),允许大语言模型生成 Python 代码来批量执行工具调用,而非传统方式的逐次往返调用,可将多工具工作流的延迟和 token 消耗大幅降低,AWS 提供三种实现方案:自托管 Docker 沙箱、Bedrock AgentCore 代码解释器,以及通过代理兼容 Anthropic SDK。
核心要点
- 传统工具调用在多工具场景下存在三重问题:每个中间结果都消耗 token、每次调用增加一次推理延迟、用自然语言处理大量数据容易出错
- PTC 通过让模型生成单次 Python 代码块来批量执行工具调用,仅采样一次模型,执行环境处理所有调用,仅返回最终结果到上下文窗口
- AWS Bedrock 提供三种 PTC 实现路径:ECS 上的自托管 Docker 沙箱(最大控制力)、Bedrock AgentCore 代码解释器(托管方
结构提纲
按章节快速跳转。
PTC 是一种新范式,模型生成代码而非逐次调用工具,可大幅降低多工具工作流的延迟和 token 消耗。
传统工具调用存在三重问题:token 消耗大、延迟高、用自然语言处理大量数据准确率低。
PTC 让模型生成单次 Python 代码块批量执行工具调用,仅最终结果返回上下文,显著提升效率。
AWS 提供三种 PTC 实现方案:自托管 Docker 沙箱、Bedrock AgentCore 代码解释器、Anthropic SDK 兼容代理。
通过费用审计场景展示 PTC 代码示例,包含并行获取数据、条件过滤和预算比较逻辑。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- Programmatic Tool Calling on Amazon Bedrock
- Problem with Traditional Approach
- Token consumption
- Latency (multiple round trips)
- Accuracy issues with natural language processing
- PTC Solution
- Model generates Python code once
- Sandboxed execution environment
- Only final output returns to context
- AWS Implementation Options
- Self-hosted Docker on ECS
- Bedrock AgentCore Code Interpreter
- Anthropic SDK compatible proxy
金句 / Highlights
值得收藏与分享的关键句。
程序化工具调用采用不同方法:模型编写代码(通常是 Python),在沙箱执行环境中程序化地调用多个工具。
模型仅采样一次生成代码。执行环境处理工具调用,仅最终处理结果返回到模型上下文。
PTC 特别适用于大规模数据处理、精确数值计算、多步骤流程编排,以及原始数据不应进入模型上下文的隐私敏感场景。
要求语言模型用自然语言过滤、聚合和比较数千条记录容易出错,这些操作用几行 Python 代码就能精确处理。
底层模式——模型生成代码、沙箱执行、仅最终输出返回上下文——是模型无关的。
在 Amazon Bedrock 上实现可编程工具调用 | Amazon Web Services
可编程工具调用(PTC)是大语言模型(LLM)与外部工具交互方式的一种范式转变。在传统的工具调用工作流中,每次工具调用都需要完整地往返模型一次。模型调用工具,接收结果,进行推理,调用下一个工具,以此类推。对于涉及多次工具调用的工作流,这会导致延迟和 Token 消耗的累积增加,因为每个中间结果都必须经过模型的上下文窗口。
PTC 采用了不同的方法。它不再一次编排一个工具调用,而是由模型编写代码(通常是 Python),在沙箱执行环境中以编程方式调用多个工具。代码可以包含循环、条件判断、过滤和聚合逻辑。模型只需采样一次即可生成代码。然后,执行环境负责处理工具调用,仅将最终处理后的结果返回给模型的上下文。这极大地减少了多工具工作流的延迟和 Token 使用量。PTC 特别适用于大数据处理、精确的数值计算、多步骤流程编排,以及原始数据不应进入模型上下文的隐私敏感场景。

PTC 最初是作为特定提供商的功能出现的,但其底层模式——即模型生成代码,沙箱执行代码,仅最终输出返回上下文——是与模型无关的。在本文中,我们将介绍在 Amazon Bedrock 上实现 PTC 的三种方式:在 ECS 上部署自托管的 Docker 沙箱以实现最大控制权;使用 Amazon Bedrock AgentCore Code Interpreter 的托管解决方案;以及通过代理实现的 Anthropic SDK 兼容路径,供偏好该开发体验的团队使用。
**传统工具调用的瓶颈**
考虑这个例子:“哪些工程团队成员超出了他们的第三季度差旅预算?”使用传统工具调用(假设没有并行函数调用),模型必须:
- 调用工具获取团队成员列表——20 人。
- 调用工具获取每个人的费用记录——20 次单独的工具调用,每次返回 50–100 个行项目。
- 调用额外工具以获取预算阈值。
- 在其上下文窗口中接收超过 2,000 条费用记录。
- 用自然语言对整个数据集进行推理,以进行过滤、比较和汇总。
每次工具调用都需要完整地往返模型一次。模型生成工具调用,暂停,接收结果,进行推理,生成下一个工具调用,以此类推。这造成了三个日益严重的问题:
- Token 消耗: 每个中间结果,包括模型最终会丢弃的数千个费用行项目,都会通过上下文窗口。
- 延迟: 每次工具调用都需要一个完整的模型推理周期。20 次顺序工具调用意味着 20 次推理往返。
- 准确性: 要求语言模型用自然语言过滤、聚合和比较数千条记录容易出错。这些操作只需几行 Python 就能精确处理。
**PTC 如何解决这个问题**
PTC 颠覆了这一模式。模型编写一个 Python 代码块来编排工具调用,处理结果,并仅返回最终输出。


使用同样的费用审计示例,当启用 PTC 时,模型生成的内容如下:
import asyncio
import json
# Step 1: Get team members
team_json = await get_team_members(department="engineering")
team = json.loads(team_json)
# Step 2: Fetch all expense records in parallel
expense_tasks = [
get_expenses(employee_id=m["id"], quarter="Q3")
for m in team
]
expenses_results = await asyncio.gather(*expense_tasks)
# Step 3: Filter and check budgets
exceeded = []
for member, exp_json in zip(team, expenses_results):
expenses = json.loads(exp_json)
total_travel = sum(
e["amount"] for e in expenses
if e["category"] == "travel" and e["status"] == "approved"
)
if total_travel > 5000:
budget_json = await get_custom_budget(user_id=member["id"])
budget = json.loads(budget_json)
limit = budget["budget_limit"]
if total_travel > limit:
exceeded.append({
"name": member["name"],
"spent": total_travel,
"limit": limit,
"exceeded_by": total_travel - limit
})
# Step 4: Only the summary enters the model's context
print(f"{len(exceeded)} members exceeded budget:")
print(json.dumps(exceeded, indent=2))代码
这里有两点需要注意。首先,asyncio.gather() 并行发出所有 20 次费用查询,而不是顺序执行,工具调用几乎同时发生。其次,过滤、聚合和预算比较是在 Python 中完成的,而不是在自然语言中。只有最终的 print() 输出会返回到模型的上下文窗口。超过 2,000 条原始费用记录不会接触到它。模型仅被采样两次:一次用于生成代码,一次用于解释最终输出。中间的所有过程(工具调用、数据处理、过滤)都在容器内发生,无需额外的模型推理。
**第 1 部分:使用 Amazon Bedrock 和 Amazon ECS 的自托管 PTC**
**为什么选择自托管**
托管的 PTC 实现依赖于提供商管理的沙箱环境。但自托管有充分的理由:
- 模型无关: 支持在 Amazon Bedrock 上可用的模型(例如 Claude、Qwen、MiniMax、Llama、Nova 等)。
- 完全控制: 自定义沙箱环境,安装特定领域的 Python 包,并配置安全策略以满足您的需求。
- 私有部署: 将代码执行和中间数据保留在您自己的 AWS 账户中。
**架构**
自托管解决方案包含两个组件:
- 编排器 – 您的应用程序(Amazon Elastic Container Service (Amazon ECS) 任务、AWS Lambda 或计算资源),它使用 Boto3 调用 InvokeModel API,管理 Docker 沙箱生命周期,并处理工具调用循环。
- Docker 沙箱 – 一个隔离的容器,用于执行模型生成的 Python 代码。通过基于 stdin/stderr 的 IPC 与编排器通信。

核心思想很简单:获取通常放在 tool_config 中的工具定义,将它们注入到系统提示词中,并指示模型编写用于编排这些工具的 Python 代码。生成的代码在 Docker 沙箱中运行。编排器充当控制平面,通过 IPC 拦截工具调用,在外部执行它们,并将结果注入回沙箱。
**系统提示词**
系统提示词是关键部分,它使模型表现得像原生支持 PTC 一样。它描述了执行环境、可用工具以及生成代码的规则。这里提供了一个精简版本:
# 代码执行环境描述
## 核心功能
您可以使用 `execute_code` 工具来运行 Python 代码。代码可以调用
异步工具函数。
{tools_doc}
## 关键规则
### 1. 无状态环境
- 每次 `execute_code` 调用都是一个全新的环境。
- 调用之间不保留变量。
- 所有操作必须在单个代码块中完成。
### 2. 基本语法
- 工具调用必须使用 `await`。
- 使用 `print()` 输出结果。
- 允许数据处理、过滤和聚合。
## 最佳实践
### 正确:一个代码块完成所有任务
import json
import asyncio
data = await get_orders(days=7)
orders = json.loads(data)
tasks = [get_detail(id=o['id']) for o in orders]
details = await asyncio.gather(*tasks)
for order, detail in zip(orders, details):
print(f"{order['name']}: {detail}")
### 错误:多个代码块
# 第一次执行
data = await get_orders()
# 第二次执行 - NameError: data 不存在
for item in data:
pass代码
该提示词引导模型生成结构良好的 Python 代码,遵循与原生 PTC 实现相同的模式,即单个代码块、异步工具调用以及使用 print() 进行输出。
**核心组件**
#### SandboxExecutor – Docker 沙箱执行器
SandboxExecutor 是核心组件。它管理隔离 Docker 容器的生命周期,安全执行模型生成的代码,并处理工具调用的 IPC 协议。该系统使用双进程架构。编排器(在您的 ECS 任务中运行)为每个代码执行请求启动一个 Docker 容器。通信通过标准 I/O 流进行,容器将工具调用请求写入 stderr,编排器通过 stdin 注入工具结果。
#### 运行器脚本
运行器脚本由编排器动态生成,并在启动时注入到每个 Docker 容器中。它负责处理:
- 代码执行 – 将模型生成的代码封装在异步上下文中,捕获输出并处理异常。
- IPC 协议 – 使用结构化消息标记(例如
__PTC_TOOL_CALL__、__PTC_END_CALL__、__PTC_OUTPUT__)在文本流中分隔工具调用请求、结果和最终输出。 - 工具函数生成 – 为配置中定义的每个工具动态创建异步 Python 函数。当模型代码调用
await get_team_members(department=”engineering”)时,生成的函数会序列化参数,将工具调用请求写入 stderr,阻塞直到编排器通过 stdin 注入结果,然后返回反序列化的结果。
运行器脚本支持两种执行模式:
- 单次模式 – 执行一次代码并退出。适用于无状态、一次性任务。
- 循环模式 – 保持容器运行以接受多次代码执行,支持会话重用和调用之间的状态保留。
#### IPC 协议
为了在文本流中可靠地分隔不同的消息类型,系统定义了边界标记:
__PTC_TOOL_CALL__/__PTC_END_CALL__– 封装工具调用请求(工具名称 + JSON 格式的参数)。__PTC_OUTPUT__– 标记代码执行的最终输出。
当运行器脚本在执行代码中遇到工具调用时,它会将调用序列化为 JSON,将其写入标记边界之间的 stderr,并在 stdin 上阻塞等待结果。编排器读取 stderr,解析工具调用,执行工具,并将结果写回 stdin。运行器脚本解除阻塞并继续执行。
**编排器循环**
在 Amazon Bedrock 上启用 PTC 需要三个要素:
- 一个 系统提示词,指示模型编写用于工具编排的 Python 代码。
- 一个 execute_code 工具定义,模型使用它将代码提交到沙箱。
- 嵌入在系统提示词中的 业务工具描述(而不是作为单独的 Amazon Bedrock 工具)。
编排器将 Amazon Bedrock 和 Docker 沙箱连接在一起。以下是核心循环:import boto3import json
import subprocess
import tempfile
import os── Configuration ──
MODEL_ID = "us.anthropic.claude-sonnet-4-5-20250929-v1:0" REGION = "us-west-2" SANDBOX_IMAGE = "ptc-sandbox"
SYSTEM_PROMPT = "..." # Full system prompt as shown above
TOOLS = [ { "name": "execute_code", "description": "Execute Python code in a sandboxed environment.", "input_schema": { "type": "object", "properties": { "code": {"type": "string", "description": "Python code to execute."} }, "required": ["code"] } } ]
── Bedrock call ──
def call_bedrock(client, messages): body = json.dumps({ "anthropic_version": "bedrock-2023-05-31", "max_tokens": 4096, "system": [{"type": "text", "text": SYSTEM_PROMPT}], "tools": TOOLS, "messages": messages, }) response = client.invoke_model( modelId=MODEL_ID, contentType="application/json", accept="application/json", body=body, ) return json.loads(response["body"].read())
── Sandbox execution ──
def execute_in_sandbox(code): """Run code in a hardened Docker container. Returns stdout.""" with tempfile.NamedTemporaryFile(mode="w", suffix=".py", delete=False) as f: f.write("import json\n" + code) tmp_path = f.name try: result = subprocess.run( ["docker", "run", "--rm", "--network", "none", "--read-only", "--tmpfs", "/tmp:size=64m", "--user", "sandbox", "--cap-drop", "ALL", "--memory", "256m", "--cpus", "0.5", "-v", f"{tmp_path}:/sandbox/user_code.py:ro", SANDBOX_IMAGE], capture_output=True, text=True, timeout=30, ) return result.stdout.strip() if result.returncode == 0 else result.stderr.strip() finally: os.unlink(tmp_path)
── PTC orchestration loop ──
client = boto3.client("bedrock-runtime", region_name=REGION) query = "Which engineering team members exceeded their Q3 travel budget?"
Step 1: Send user query — model generates Python code
messages = [{"role": "user", "content": query}] response = call_bedrock(client, messages)
Step 2: Extract code from tool_use block
for block in response["content"]: if block["type"] == "tool_use": code = block["input"]["code"] tool_id = block["id"]
Step 3: Execute in Docker sandbox
output = execute_in_sandbox(code)
Step 4: Send sandbox output back as tool_result
messages.append({"role": "assistant", "content": response["content"]}) messages.append({ "role": "user", "content": [{"type": "tool_result", "tool_use_id": tool_id, "content": output}] })
Step 5: Model interprets the result and produces final answer
final = call_bedrock(client, messages) for block in final["content"]: if block["type"] == "text": print(block["text"])
Code
编排器将用户查询发送至 Amazon Bedrock,从 tool_use 响应中提取模型生成的代码,在 Docker 沙箱中运行它,并将输出作为 tool_result 反馈回去。然后模型生成其最终的人类可读答案,总共仅采样两次。
### **Docker 沙箱安全性**
沙箱容器在严格的隔离状态下运行。以下是一个强制执行安全层的 docker run 命令示例:
docker run --rm \ --network none \ --read-only \ --tmpfs /tmp:size=64m \ --user sandbox \ --cap-drop ALL \ --memory 256m \ --cpus 0.5 \ -v /path/to/code.py:/sandbox/user_code.py:ro \ ptc-sandbox
Code
这实现了以下功能:无网络访问、只读文件系统(带有用于临时空间的小型 tmpfs)、非 root 用户、丢弃 Linux 能力,以及严格的内存/CPU 限制。模型生成的代码无法逃逸出沙箱、持久化数据或消耗过多资源。
## **第 2 部分:使用 Amazon Bedrock AgentCore 代码解释器实现托管式 PTC**
对于不想管理 Docker 容器和 ECS 基础设施的团队,Amazon Bedrock AgentCore 提供了一个实现相同 PTC 模式的托管式代码解释器。模型编写代码,托管式沙箱执行它,只有最终输出会返回到模型上下文中。以下是使用 AgentCore 代码解释器进行代码执行的修改后的相同架构:
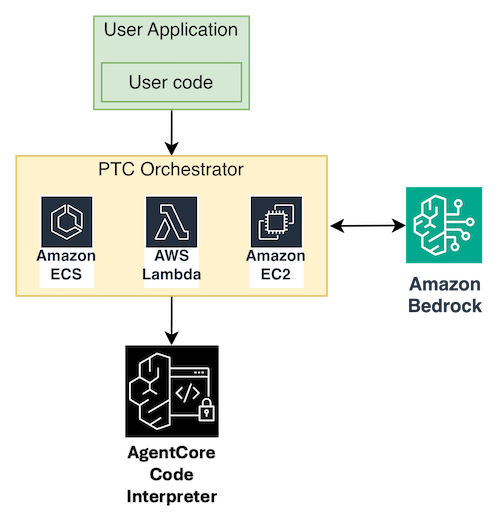
与自托管方法的主要区别在于,工具是预加载*到*沙箱会话中,而不是通过 IPC 调度回客户端。您启动一个代码解释器会话,将工具函数定义作为 Python 代码注入,然后让模型生成直接调用这些预加载函数的代码。
AgentCore 使用 bedrock-agentcore boto3 客户端:
import boto3 import json
bedrock = boto3.client("bedrock-runtime", region_name="us-west-2") agentcore = boto3.client("bedrock-agentcore", region_name="us-west-2")
Start a Code Interpreter session
session = agentcore.start_code_interpreter_session( codeInterpreterIdentifier="aws.codeinterpreter.v1", name="ptc-tools", sessionTimeoutSeconds=900, ) session_id = session["sessionId"]
Pre-load tool functions into the sandbox.
Replace this string with your actual tool function definitions.
tool_functions_code = """ def get_team_members(department):
Your implementation here — return JSON string
pass
def get_expenses(employee_id, quarter="Q3"):
Your implementation here — return JSON string
pass
def get_custom_budget(user_id):
Your implementation here — return JSON string
pass
print("Tools loaded.") """
agentcore.invoke_code_interpreter( codeInterpreterIdentifier="aws.codeinterpreter.v1", sessionId=session_id, name="executeCode", arguments={"language": "python", "code": tool_functions_code} )
Code
### **自托管与托管式对比**
| 方面 | 自托管 (第 1 部分) | AgentCore (第 2 部分) |
| :--- | :--- | :--- |
| 基础设施 | 您管理 ECS + Docker | 完全托管 |
| 自定义 | 对沙箱拥有完全控制权 | 标准运行时 |
| 工具执行 | 客户端 (IPC) | 沙箱内部 |
| 网络访问 | 可配置 | 默认关闭,可用 PUBLIC 模式 |
对于希望获得 PTC 带来的 Token 节省和准确性提升,但又不想承担运行 Docker 容器运营开销的团队,推荐使用托管方式。当您需要自定义 Python 包、特定的安全配置或需要对执行环境拥有完全控制权时,自托管方式更为合适。
## **第 3 部分:通过代理实现 Anthropic SDK 兼容性**
如果您的团队更倾向于 Anthropic SDK 的开发体验,并希望以 Amazon Bedrock 作为后端使用它,您可以构建一个轻量级的 API 转换代理,将其部署在 Anthropic SDK 和 Amazon Bedrock 之间。
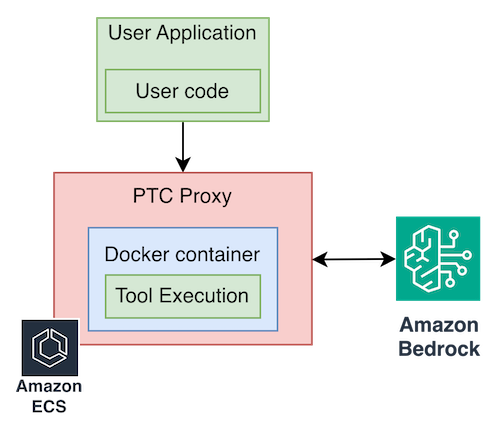
该代理部署在 Amazon ECS 上,将 Anthropic API 调用转换为 Amazon Bedrock InvokeModel 调用。它还透明地管理 Docker 沙箱生命周期和完整的 PTC 协议。要进行迁移,只需将 `base_url` 更改为指向该代理:
import anthropic
Point the Anthropic SDK at the proxy deployed on ECS.
The proxy translates these calls to Bedrock InvokeModel under the hood.
client = anthropic.Anthropic( api_key="your-proxy-api-key", # API key configured in the proxy base_url="http://your-proxy-url.com" # Your proxy's ECS endpoint )
Define PTC tools — same format as Anthropic's native PTC API
ptc_tools = [ {"type": "code_execution_20250825", "name": "code_execution"}, { "name": "get_team_members", "description": "Get department team member list", "input_schema": { "type": "object", "properties": {"department": {"type": "string"}}, "required": ["department"] }, "allowed_callers": ["code_execution_20250825"] }
Add get_expenses, get_custom_budget similarly
]
response = client.beta.messages.create( model="claude-sonnet-4-5-20250929", # Proxy routes to Bedrock model betas=["advanced-tool-use-2025-11-20"], tools=ptc_tools, messages=[{"role": "user", "content": "Which team members exceeded Q3 travel budget?"}] )
The proxy handles sandbox execution and tool call interception transparently.
代码
这种方法推荐给那些更喜欢 Anthropic SDK 接口,同时希望利用 Amazon Bedrock 进行模型推理并享受在其 AWS 账户内运行所带来的好处的团队。该代理透明地处理模型转换、沙箱管理和完整的 PTC 协议。
## **实验结果**
为了验证自托管 PTC 解决方案,我们在 Amazon Bedrock 上提供的多个模型上运行了相同的费用审计任务。
**业务设置:**
1. **团队数据:** 不同级别的八位工程团队成员。
2. **费用数据:** 每人每季度 20-50 条记录,每条记录包含 15 个以上字段(expense_id、date、amount、category、status)。
3. **预算规则:** 标准季度差旅预算为 5,000 美元,高级职位有自定义例外。仅计算 _已批准_ 的费用。
**任务提示词:** “哪些工程团队成员超过了他们的第三季度差旅预算?标准季度差旅预算为 5,000 美元。但是,部分员工有自定义预算限额。对于任何超过 5,000 美元标准预算的人员,请检查他们是否有自定义预算例外。”
**预期正确答案:**
| **姓名** | **预算** | **实际** | **超出** |
| :--- | :--- | :--- | :--- |
| Alice Chen | $5,000.00 | $9,876.54 | +$4,876.54 |
| Emma Johnson | $5,000.00 | $5,266.02 | +$266.02 |
| Grace Taylor | $5,000.00 | $6,474.46 | +$1,474.46 |
### **PTC 与非 PTC 对比**
| **模型** | **PTC tokens** | **非 PTC tokens** | **Token 减少** | **PTC 准确** | **非 PTC 准确** |
| :--- | :--- | :--- | :--- | :--- | :--- |
| Claude Sonnet 4.6 (adaptive thinking) | 12,739 | 128,043 | 90.1% | Yes | Yes |
| Claude Opus 4.6 (adaptive thinking) | 13,043 | 126,152 | 89.7% | Yes | Yes |
| Qwen3-Coder-480B | 34,159 | 305,114 | 88.8% | Yes | No |
| Qwen3-Next-80B | 28,878 | 233,332 | 87.6% | Yes | No |
| deepseek.v3.2 (thinking) | 19,543 | 245,967 | 92.1% | Yes | No |
| MiniMax M2.1 (thinking) | 11,787 | 101,990 | 88.4% | Yes | No |
| Kimi 2.5 (thinking) | 10,875 | 148,085 | 92.7% | Yes | No |
| GLM 4.7(thinking) | 11,550 | 115,829 | 90.0% | Yes | No |
注意:标记为 _thinking_ 或 _adaptive thinking_ 的模型在代码生成期间使用了各自的推理模式。
### **主要发现**
1. **Token 消耗量下降了 87–92%**。在 PTC 模式下,所有模型的 Token 消耗量均有所下降。不再有数十万个 Token 流经上下文窗口,只有代码和最终摘要会到达模型。
2. **准确性显著提高。** 在 PTC 模式下,所有八个模型都给出了正确答案(姓名和金额完全匹配)。在非 PTC 模式下,只有 Claude 模型(Sonnet 4.6 和 Opus 4.6)给出了完全正确的答案。其他模型对大型表格数据的自然语言处理在筛选、聚合或这两方面都引入了错误。
3. **跨模型兼容性得到确认。** Claude、Qwen、DeepSeek、MiniMax、Kimi、GLM 模型都在 PTC 模式下取得了正确结果,证明了这一范式在不同的模型系列中都能有效工作。Token 节省率在 87% 到 92% 之间。
4. **自托管解决方案在不同模型间表现一致。** 使用相同的 Docker 沙箱、相同的 IPC 协议和相同的编排器,测试之间仅更改了 `model_id` 参数。
关键结论:作为一种范式,PTC 并不局限于任何单一模型。通过自托管沙箱方法,任何支持工具使用的模型都可以受益于代码编排的工具调用。
## **成本和价值分析**
### **规模化下的 Token 节省**
以 Claude Sonnet 4.6 为例,费用审计任务显示 PTC 模式相比非 PTC 模式的 Token 消耗量减少了约 90%。原因很简单:在非 PTC 模式下,每个中间工具结果都会进入上下文窗口。而在 PTC 模式下,只有代码和最终摘要会进入。
**成本预测**(基于 Claude Sonnet 每 100 万输入/输出 Token 3 美元/15 美元的价格):
如果此任务在生产环境中每天执行 1,000 次:
| **指标** | **非 PTC 模式** | **PTC 模式** |
| :--- | :--- | :--- |
| 预估每日成本 | ~$520 | ~$52 |
| 预估每月成本 | ~$15,600 | ~$1,560 |
| 每月节省 | ~$14,040 (90%) | |
这些数字会因任务复杂度和数据量而异,但规律是一致的:PTC 降低成本的比例大致与其排除在上下文窗口之外的中间数据量成正比。
## **结论**
程序化工具调用标志着 AI 代理与工具交互方式的转变,从对话式的、一次一个的调用转变为代码编排的、并行的、经过过滤的执行。我们的测试结果证实了其核心价值主张:
1. Token 消耗量下降了 87–92%,因为中间数据被排除在模型上下文之外。
2. 准确性得到提高,因为数据处理发生在 Python 中,而非自然语言中。
3. 延迟降低,因为工具调用可以并行运行,且模型仅需采样两次。
我们介绍了在 Amazon Bedrock 上实施 PTC 的三种方式:
1. **在 ECS 上自托管** – 使用 Boto3 和 Docker 沙箱拥有完全控制权,推荐给需要自定义环境和最大灵活性的团队。
2. **通过 AgentCore Code Interpreter 托管** – 一个完全托管的沙箱,适合希望减少运营开销的团队。
3. **兼容 Anthropic SDK** – 一种基于代理的路径,适合在 Amazon Bedrock 上运行但偏好 Anthropic SDK 接口的团队。
这三种方法都是与模型无关的,在您的 AWS 账户内私有部署,并且随着 Amazon Bedrock 上新模型的推出可扩展到新模型。Amazon Bedrock 提供模型推理后端,采用按需付费定价模式,确保您 AWS 账户内的数据主权,并通过单一 API 访问多样化的模型集。
## **参考**
1. [Anthropic — Programmatic Tool Calling Documentation](https://platform.claude.com/docs/en/agents-and-tools/tool-use/programmatic-tool-calling/)
2. [Anthropic — Introducing Advanced Tool Use](https://www.anthropic.com/engineering/advanced-tool-use)
3. [Amazon Bedrock AgentCore Code Interpreter Documentation](https://docs.aws.amazon.com/bedrock-agentcore/latest/devguide/code-interpreter-tool.html)
4. [AWS sample-ai-possibilities — Programmatic Tool Calling Pattern](https://github.com/aws-samples/sample-ai-possibilities)
5. [Amazon Bedrock — Fully Managed Foundation Model Service](https://aws.amazon.com/bedrock/)
6. [AWS Samples – Anthropic-Bedrock API Proxy](https://github.com/aws-samples/sample-bedrock-api-proxy)
* * *
## 关于作者