OpenAI如何构建其数据代理

TL;DR · AI 摘要
OpenAI的数据平台存储了1.5 exabytes的数据,涵盖了90,000个数据集,并为大约4,000名内部用户提供服务。团队构建了一个内部代理,帮助分析师找到正确的表并理解如何使用数据。该代理在生态系统中表现出色,使OpenAI能够在两个星期内迁移数千个DAG、90,000个表和600PB数据到云中。
核心要点
- OpenAI的数据平台存储了1.5 exabytes的数据,涵盖了90,000个数据集。
- 团队构建了一个内部代理,帮助分析师找到正确的表并理解如何使用数据。
- 该代理在生态系统中表现出色,使OpenAI能够在两个星期内迁移数千个DAG、90,000个表和600PB数据到云中。
结构提纲
按章节快速跳转。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- OpenAI's Data Agent
- Data Platform
- 1.5 exabytes across 90,000 datasets
- Internal Agent
- Helps analysts find the right tables and understand how to use data
- Reliability
- Migrates thousands of DAGs, 90,000 tables, and 600PB data between clouds in two
金句 / Highlights
值得收藏与分享的关键句。
该代理在生态系统中表现出色,使OpenAI能够在两个星期内迁移数千个DAG、90,000个表和600PB数据到云中。
团队构建了一个内部代理,帮助分析师找到正确的表并理解如何使用数据。
OpenAI的数据平台存储了1.5 exabytes的数据,涵盖了90,000个数据集。
OpenAI 如何构建其数据代理
新的研究。新的公告。GitLab 的新篇章。
6月10日,GitLab Transcend 在伦敦直播 —— 工程师们将在任何人之前首次看到 GitLab 19 和 Duo Agent Platform 的最新进展。 包括对 GitLab Orbit 的现场演示:一个横跨整个 SDLC 的知识图谱,使你的代理了解你的管道、安全待办事项以及上周发布的的内容,而不仅仅是你的仓库。虚拟、免费且即将开始。
OpenAI 的数据平台存储了 1.5 exabytes 数据,并 90,000 个数据集,截至 2026 年 5 月为内部约 4,000 名用户。团队在过去的两年里通过巨大的增长成功扩展了平台。在这个规模下,数据分析最困难的部分不是编写 SQL。 而是找到正确的表并理解如何使用数据。 很多表看起来相似但意义不同。 每张表的粒度是什么?你如何与其他数据连接?分析师可能需要花费数小时来确定使用哪些表以及如何使用它们,然后才写一行代码。 去年,OpenAI 的数据平台团队建立了一个内建代理来解决这个问题。该代理,用他们自己的话来说,“相当普通”,然而它可靠地运行在整个生态系统中。并且相同的 Codex 投资让团队能够做大多数公司认为不可能的事情,比如在两个月内迁移数千个 DAG、90,000 张表和 600 petabytes 数据库之间的云迁移。我们采访了 Emma Tang [Emma Tang](https://www.linkedin.com/in/emmaytang/,OpenAI 数据平台工程主管,关于代理如何工作,为什么简单的架构在这规模足够强大数据基础设施基础。模块化迁移数千个 DAG、90,000 张表和 600 petabytes。 我们与 Emma Tang [Emma Tang] (https://www.linkedin.com/in/emmaytang/),感谢 Emma 花费时间分享团队的工作细节。
这使得团队能够迁移数千个 DAG、90,000 张表和 600 petabytes。 团队已经通过强大的数据基础设施基础。去年,OpenAI 的数据平台团队建立了一个内建代理来解决这个问题。团队通过投资支持代理。 这些公司考虑不可能,像迁移到其他云。 我们会问 Emma Tang [https://www.linkedin.com/in/emmaytang/,Head of Data Platform Engineering at OpenAI,关于这个代理,为什么简单架构足够大的原因,其他团队的教训,以及平台下一步去哪儿?
在这篇文章中,你将学习:
- OpenAI 的数据平台团队建造了一个内建代理,以解决这个问题。 本体,为什么简单结构足够大到足以处理所有问题。代领用具有的团队,关于代理,为什么简单架构在这规模,许多天后,OpenAI 的数据平台团队建造了一个内建代理,为什么简单架构足够大由于强的数据基础设施基础。 个月。 我们与 OpenAI,关于代理。 问及迁移数千个 DAG、90,000 张表和 600 petabytes 之间 2026 平台是,团队能做什么。 三步。 三个真实 Codex 使用案例里面 OpenAI:一个知识图谱跨整个 SDlc 所以什么? 五个实用教训对于任何团队建造一个领域代理,接下来去哪儿? 五条教训对于任何团队建造一个领域代理,为什么简单? 九万张表和 600 petabytes 之间 两个云。 九万张表和 600 petabytes 之间云。 九万张表和 600 petabytes 之间云。 九万张表和 600 petabytes 之间 云。 九万张表和 600 petabytes 之间 云。 九万张表和 600 petabytes 之间云。 九千个 DAG,90,000 张表和 600 petabytes 之间云。 九千个 DAG,90,000 张表和 600 petabytes 之间云。 九千个 DAG,90,000 petabytes 之间 云。 九千个 DAG,90,000 petabytes 之间云。 九千个 DAG,90,000 petabytes 之间云。 九千个 DAG,90,000 petabytes 之间云。 九千个 DAG,90,000 petabytes 之间云。 九千个DAGs,90,000 petabytes 之间云。 九千个 DAG,90,000 petabytes 之间云。 九千个 DAG,90,000 petabytes 之间云。### OpenAI 的数据代理,为什么简要一个 LLM 成为一个 九千个 DAG,90,000 petabytes 之间云。 九千个 DAG,90,000 petabytes 之间云。 九千个 DAG,90,000 petabytes 之间 九千个 DAG,90,000 petabytes 之间云。 九千个 DAG,90,000 petabytes 之间云。 九千个 DAG,90,000 petabytes 之间云。 九千个 DAG,90,000 petabytes 之间云。 九千个 DAG,90,000 petabytes 之间云。九千个 DAG,90,000 petabytes 之间 九千个 DAG,90,000 petabytes 之间云。 九千个 DAG,9https://substackcdn.com/image/fetch/$s_!jmI_!,w_1456,90,000 petabytes 之间 九千个 DAG,60,000 petabytes 之间云。 九千个 DAG,60,000 petabytes 之间 jhttps://substackcdn.com/image/fetch/s_!jMj_!,w_1456,90,000 petabytes 之间云。 九千个 DAG,90,000 petabytes 之间云。 九千个 DAG,60,000 petabytes_!jmI_!,w_1456,89,000 petabytes 之间云。 九千个 DAG,90,000 pet 之间 https://substack-post-media.s3 之间云。
[图片
**
从
Codex 现在处理了过去需要调查的部分支持工作。支持机器人首先回答常见问题,并直接解决简单的问题。当机器人无法解决问题时,值班工程师将它转交给 Codex,只需提供最少的背景信息。Codex 进行调查,找到解决方案并应用。工程师审核并批准。
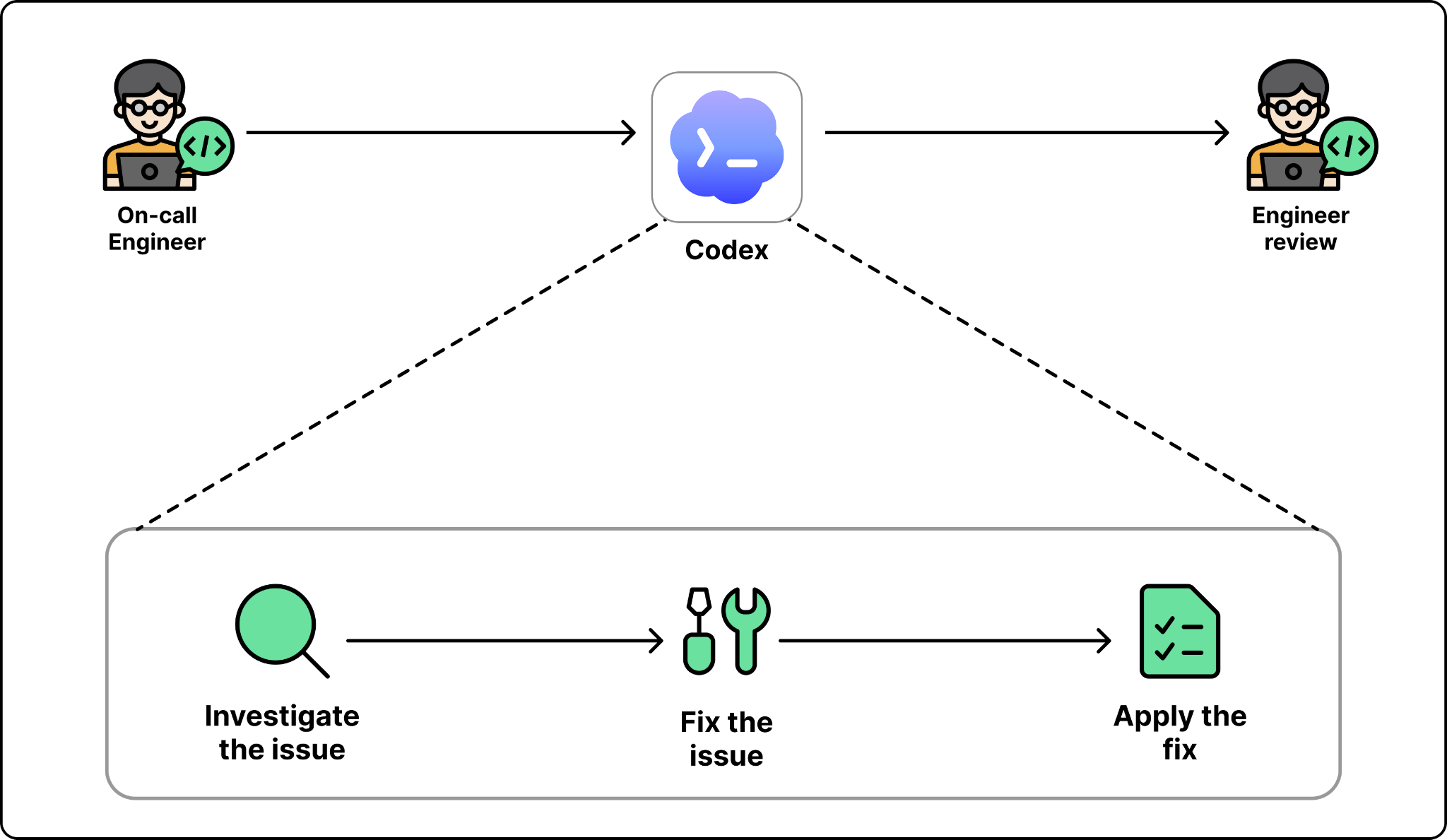](https://substackcdn.com/image/fetch/$s_!O-ZL!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fe430ea00-36cd-46a1-b97b-73084a39ebf7_2048x1189.png)
利用 Codex 关闭支持循环
过去需要工程师每张票花几个小时的循环现在让工程师每天可以处理一百多处修正。这项工作并不轻松。工程师的能力得到了放大。
OpenAI 的数据代理 工作,但本身的架构大多数团队不应照搬。值得借鉴的是团队在构建它时所做的决策集。Emma 分享了五条适用于任何团队建立类似系统的主教训。
一个编码剂有一个单一来源:仓库。一个 data agent 的真实来源是整个公司。每个系统、每个隔离的数据存储、每个团队的惯例、每个定义在外统一代码库外的表。如果模型对这些内容不可见,没有架构将救你。
OpenAI 的数据结构良好。他们建立了最佳行业标准基础设施涵盖计算、编排、元数据管理、存储技术等。 每个平台上的表由单个 monorepo 中的代码生成,数据工程队强制惯例和检查重复或不清列。此外,每个表有强标注,包括所有者、重要性、数据的新鲜度。这不光鲜亮工作,但这是
团队得出的结论是,从 Codex 之前的时间线估计不再适用。如果一个项目听起来需要一年时间,正确的问题是它是否可以在一个季度内完成,一个代理大部分工作。更大的风险不是过度承诺,而是过于谨慎。一个坚持旧时间表的团队永远不知道新工具的可能性。
数据代理和内部 Codex 的用例并不是故事的全部。Emma 说,团队的下一个目标是自定义应用和平台与用户保持同步。
根据问题生成的自定义应用。
当今大多数分析工具为用户提供一组固定的仪表板,如条形图、折线图和透视表。它们很有用,但有限。如果您的问题不符合可用的仪表板,您需要编写自定义脚本或向数据团队提出请求。
OpenAI 想要更进一步。代理已经在需求下构建传统仪表板,但下一步是自由形式的仪表板。 Codex 不再构建图表,而是构建一个完整的 React 应用程序,连接到后端存储,并针对问题进行定制。每个仪表板只需几秒钟即可构建,仅针对单个用户的需求,并基于真实数据和真实限制运行。
当这项功能推出时,用户将不再从固定的一组仪表板中选择。他们将描述他们想要的内容,应用程序将根据问题生成。一个希望使用自定义过滤器和定制布局探索活动表现的营销人员只需询问即可。
用户比平台快。
推动 OpenAI 每个团队前进的 Codex 同时加速了前端工程师的代码编写速度。研究人员可以随时创建自定义管道。平台团队无法以这种速度安全地移动。一个糟糕的 UI 影响少数用户,但对共享基础设施的不良更改可能会使整个公司下线。
这导致了不匹配。现在,用户比团队更快地将代码推送到平台,而一些代码是由那些不了解其功能的人编写的。Emma 提到了一个例子,当一个 Flink 任务导致集群崩溃时,用户回答说:“我不知道,我不知道 Flink 怎么工作,它是 vibe-coded。你能帮我修复它吗?”
这是数据平台团队计划解决的下一个问题。解决方案不是另一个面向用户的代理,而是在平台侧的代理,设计用于处理传入的代码,验证其在运行前,吸收来自 AI 加强的用户的洪流。前几波代理帮助用户做得更多。下一波将帮助平台跟上。