[AINews] OpenAI GPT-next disproves 80 year old Erdős planar unit distance problem for under $1000
![[AINews] OpenAI GPT-next disproves 80 year old Erdős planar unit distance problem for under $1000](/api/img-proxy?url=https%3A%2F%2Fsubstackcdn.com%2Fimage%2Ffetch%2F%24s_!BIRC!%2Cw_1456%2Cc_limit%2Cf_auto%2Cq_auto%3Agood%2Cfl_progressive%3Asteep%2Fhttps%253A%252F%252Fsubstack-post-media.s3.amazonaws.com%252Fpublic%252Fimages%252F0ff7bdc0-79ef-49ce-a5c0-f7db89d60637_1098x1582.png)
TL;DR · AI 摘要
OpenAI的GPT-next模型以不足1000美元的成本,在32小时内解决了持续80年的Erdős平面单位距离问题,证明了通用LLM在复杂科学推理中的潜力。
核心要点
- OpenAI的GPT-next模型以不足1000美元和32小时运行时间,首次通过通用LLM推翻了Erdős的平面单位距离问题假设。
- 数学家Timothy Gowers和OpenAI研究员Hongxun Wu确认这是AI首次解决知名开放数学问题的明确案例。
- 该成果显示通用LLM在长期推理任务中的突破,可能推动科学领域更广泛的应用。
结构提纲
按章节快速跳转。
- §成果概述
OpenAI的GPT-next模型以低成本和短时间解决了持续80年的Erdős平面单位距离问题,证明通用LLM在科学推理中的潜力。
- ·技术细节
模型运行成本低于1000美元,耗时少于32小时,采用通用架构而非专用数学模型。
Erdős的平面单位距离问题自1946年提出,涉及平面上点集的最大单位距离对数。
- ›解决方案
模型发现了超越传统网格结构的新构造方法,通过长期推理逐步逼近问题核心。
数学家Timothy Gowers和OpenAI研究员Hongxun Wu高度评价,认为这是AI在数学领域的里程碑。
成果暗示通用LLM可能在科学发现、工程优化等复杂推理任务中发挥更大作用。
思维导图
用一张图看清主题之间的关系。
查看大纲文本(无障碍 / 无 JS 友好)
- OpenAI解决Erdős问题
- GPT-next模型
- 通用架构
- 成本<1000美元
- 数学推理突破
- Erdős问题
- 新构造方法
- 学术验证
- Timothy Gowers
- Hongxun Wu
金句 / Highlights
值得收藏与分享的关键句。
OpenAI强调这是通用模型而非专用数学系统,表明其长期推理能力可扩展至科学领域。
Timothy Gowers称这是AI首次明确解决知名开放数学问题的案例。
模型在125页输出中第39页出现关键转折点,展示了推理过程的阶段性突破。
我们将推迟对SpaceXAI IPO申报文件的报道,留待IPO当日发布。今天我们要庆祝OpenAI的突破性成果——据推测这由运行时间不足32小时或成本低于1000美元的GPT 5.6模型完成的平面单位距离问题研究。与2025年国际数学奥赛金牌成果类似,此次突破来自一个通用型LLM,而非AlphaProof/Lean这类专用推理模型,这为人工智能在数学之外领域的扩展推理能力带来希望:
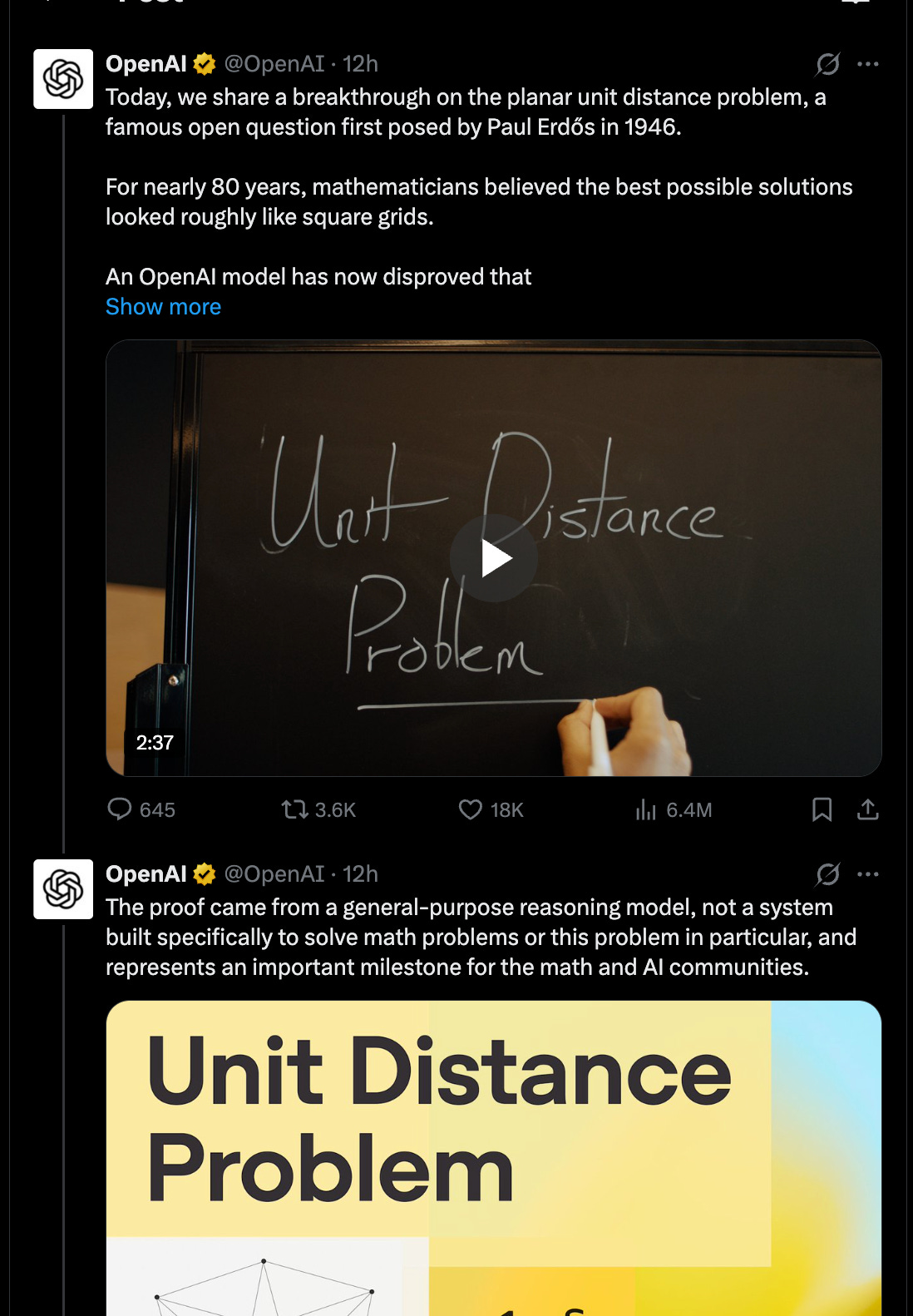
在长达125页的输出中,第39页的"关键转折点"引发特别关注:
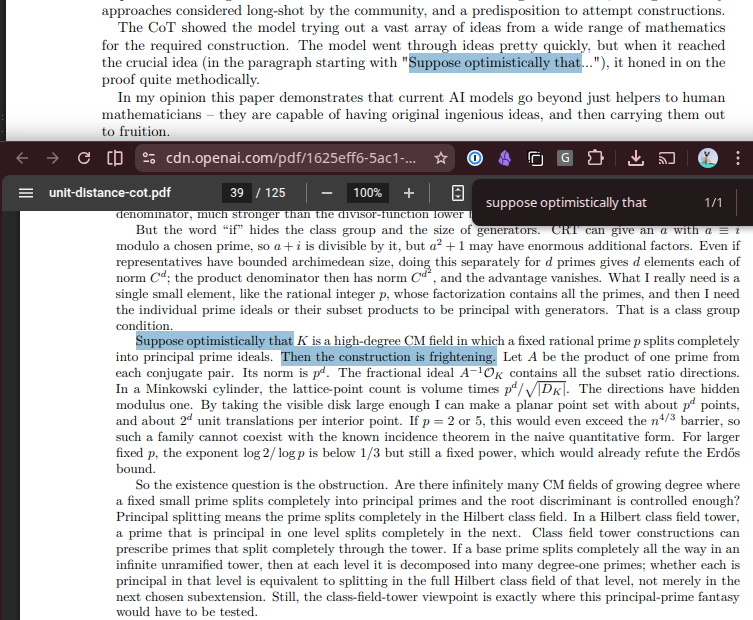
正如意见书作者所指出,这是对猜想的反证而非证明,虽不如证明更令人震撼,但预示了未来发展的方向:


2026年5月4-5日AI新闻速递。我们监测了12个subreddit社区、544条推特,未发现相关Discord讨论。您可通过AINews官网检索往期内容。提醒:AINews现为Latent Space子栏目,您可订阅/退订邮件推送频率!
OpenAI在爱多士单位距离问题上的数学突破
- 通用推理模型在离散几何领域取得新研究成果:OpenAI宣布其内部模型推翻了持续多年的平面单位距离问题猜想——这一著名的1946年爱多士难题,发现了超越网格结构的新构造方案 @OpenAI。OpenAI强调这是通用型模型,而非专用数学系统或辅助求解器 @OpenAI,并认为该成果预示人工智能在科学领域长周期推理能力的提升 @OpenAI。
- 该成果获得数学界和相关领域研究者罕见的高度认可。蒂莫西·高沃斯称其为AI解决知名开放数学问题的首个清晰案例 @wtgowers,而OpenAI研究员吴鸿勋将其视为内部推理LLM在"最困难问题"上的里程碑 @HongxunWu。托马斯·布鲁姆 @thomasfbloom、格雷姆·德拉姆 @gdb、亚历克斯·魏 @alexwei_ 和 @polynoamial 等学者的反馈一致认为:这一成果在质上超越了过往"AI解奥数题"的里程碑。
- 值得关注的技术细节:OpenAI 表示该模型并未达到极限,其设计目标是最终面向公众使用 @polynoamial。据称发布的推理摘要本身规模庞大——每份报告约 125 页(@voooooogel 的说法)——这进一步引发了关于前沿推理中 推理时计算资源实际作用的讨论。部分观察者明确将此视为实证,认为推理阶段的规模扩展是当前技术进展的核心范式 @_arohan_,另一些人则推测未来在形式科学和数学领域将实现更快突破 @scaling01, @sama。
Cohere Command A+ 开源发布与架构讨论
- Cohere 以 Apache 2.0 开源权重形式发布了 Command A+,定位为当前性能最强的模型,并明确优化了硬件兼容性 @cohere,后续声明进一步澄清了许可证细节 @cohere。此次发布意义重大,部分原因在于这是 Cohere 首个完全开源的 Apache 2 模型(@aidangomez 的观察) @aidangomez。社区反应普遍认为这是向更开放、可部署的企业级开源模型迈出的重要一步 @nickfrosst, @ClementDelangue。
- 多篇帖子重复强调了模型细节:约 2180 亿 MoE 混合专家架构 / 250 亿活跃参数,支持 多模态和 48 种语言,且可在相对轻量级的硬件上运行 @JayAlammar, @mervenoyann。vLLM 即时支持迅速跟进,特别指出其可在仅需 2 块 H100 GPU(W4A4 配置)上运行 @vllm_project。
- 基准测试呈现复杂但可信的结果:Artificial Analysis 将 Command A+ 的 智能指数定为 37 分,接近 Claude 4.5 Haiku 水平,其 非幻觉行为表现尤为突出且速度尚可,但科学推理和编码能力弱于顶尖竞品 @ArtificialAnlys。社区还深入探讨了架构设计:被特别指出的非常规选择包括 并行 Transformer 块、大规模 共享专家使用、LayerNorm 而非 RMSNorm、相对较低的 32 层深度,以及非典型的头/专家配置 @eliebakouch, @rasbt, @stochasticchasm。此次发布不仅是一个模型的推出,更提供了重要的架构参考。
- Gemini 3.5 Flash 在 Gemini 应用中开始更广泛的推广,包括全球免费访问 @GeminiApp,@GeminiApp。谷歌称其为目前最强的 智能代理和编码模型,声称其性能达到同类模型的 四倍速度,且成本不足其一半 @Google。然而外部讨论反响不一,多篇帖子质疑其 实际成本/性能比和分词效率,尽管其初期基准测试表现良好 @ArtificialAnlys,@scaling01,@giffmana。
- Gemini Omni 的质的影响力似乎超过 3.5 Flash。谷歌将其定位为视频和混合输入工作流的对话式多模态创作/编辑模型 @Google,Gemini 应用演示了对话式视频编辑功能 @GeminiApp。早期反馈普遍认为 Omni 相比核心 LLM 升级更具差异化 @scaling01。
- 在工具链方面,AI Studio 更聚焦于端到端开发者工作流和移动端访问 @GoogleAIStudio,而多篇帖子试图解析 Gemini Spark、Antigravity 与谷歌内部/外部代理框架的关系 @simonw,@_philschmid。与 Antigravity 相关的更具体更新是谷歌代理栈推出的 Science Skills,整合了 UniProt 和 AlphaFold DB 等 30+ 生命科学数据源 @GoogleDeepMind。
代理基础设施、检索与开发工具
- 多篇帖子总结出相同的实践教训:代理在基础设施层面失败早于演示层面失败。这一主题体现在研究型代理应对依赖冲突和配置的质性讨论中 @jehyeoky248,LangChain 推出 LangSmith Sandboxes 正式发布 @LangChain,以及轻量级 代码解释器 对深度代理的支持——作为纯工具执行和完整沙箱之间的中间方案 @sydneyrunkle,@hwchase17。
- 在检索/搜索基础设施领域,Perplexity 描述了生产化的 查询感知、引用保留的上下文压缩系统,可减少 70% 的上下文分词量同时提升回答质量,并声称在 SimpleQA 数据集上实现 50倍压缩且性能达到前沿水平 @perplexity_ai。Weaviate 1.37 新增 MMR 重新排序功能,以提升向量检索在 RAG/代理中的多样性 @weaviate_io,而 SID-1 作为 RL 训练的代理型搜索模型,在引用实验中实现了比 RAG+rerank 1.9倍的召回率、24倍的速度,且成本仅为 GPT-5.1 的 1% @turbopuffer。
- Cursor、VS Code 和 Codex 均推出了重要工作流更新。Cursor 在代理工作区新增 自动化功能 @cursor_ai,VS Code 推出更好的 Markdown/HTML 预览、远程会话连续性以及实用模型配置功能 @code,@pierceboggan。模型层面,Composer 2.5 在编码代理领域表现突出——在 Artificial Analysis 编码代理指数上取得 62分,且成本远低于顶尖 Opus/GPT-5.5 变体 @ArtificialAnlys。OpenAI 也推出了 Codex 移动端支持 @OpenAIDevs。
热门推文(按互动量排序)
- OpenAI 数学里程碑:OpenAI 关于单位距离突破的公告是本组技术内容中最具影响力的帖子,既因科学创新性,也因其对长周期推理能力的启示 @OpenAI。
- Cohere Command A+ 开源发布:当日最大的模型发布新闻之一,主要因其 Apache 2.0 许可和独特架构 @cohere。
- Anthropic 与 SpaceX/Colossus 算力扩展:据报道,Anthropic 正在 Colossus 2 算力上进行扩容 @nottombrown,后续帖子引用文件显示 SpaceX 算力协议估值为 2029年5月前每月12.5亿美元 @SemiAnalysis_。
- Exa 融资:Exa 完成 2.2亿美元估值的2.5亿美元C轮融资,明确定位为通过组织网络数据为代理提供支持的搜索实验室 @ExaAILabs。
- [通义千问正在全力开发](https://www.reddit.com/r/LocalLLaMA/comments/1theffd/qwen_is_cooking_hard/) (活动量:1292):图片是郑楚杰(Chujie Zheng)暗示通义千问“全力开发”的截图,引用公告显示Qwen3.7 Preview已上线Arena,包含Qwen3.7-Max-Preview和Qwen3.7-Plus-Preview版本;帖子声称阿里云在文本领域排名第
#6,视觉领域排名第#5。结合Reddit标题和正文内容,用户普遍期待更大规模和更新的开源模型——尤其是122B和新27B版本,但截图本身更多是预告而非技术基准分析。[图片](https://i.redd.it/cefjio15g12h1.png) 评论者分为两派:一派对高端模型感到兴奋,另一派更关注本地运行的小型模型。有人希望为低端硬件提供9B/4B变体,也有人期待122B或改进的35B版本,还有人调侃通义千问可能很快会“烤坏”他们的GPU。
- 多位评论者更关注模型规模覆盖范围而非当前发布的
27B版本,表示无法实际运行该规模模型,希望推出更小的Qwen4B/`9B`变体以适配低端或笔记本GPU。对更大122B和改进35B检查点也有兴趣,但有用户指出Qwen 3.6曾提及122B但未实现,因此对Qwen 3.7是否真会发布122B存在疑虑。
- [通义千问3.7 Max在人工分析中得分,27B/35B进入等待阶段](https://www.reddit.com/r/LocalLLaMA/comments/1tie6gy/qwen37_max_scored_by_artificial_analysis_27b35b/) (活动量:553):Reddit帖子引用[人工分析排行榜截图](https://preview.redd.it/42ak5qmus82h1.png?width=1133&format=png&auto=webp&s=744ea3dfc06c83d0c4d8aa128c39b3238b17d7be),显示Qwen3.7 Max排名第
5,与GPT 5.4(xhigh)持平,略超Gemini 3.5 Flash。作者指出Qwen3.6 27B落后其Max版本6分,并希望Qwen3.7 27B/35B变体能接近Max模型的性能。 评论者大多在“热切等待开源模型”,认为该分数证明通义团队已具备与顶级实验室竞争的实力,尽管Max模型未开源引发担忧。技术层面,有用户质疑通义是否解决了模型此前的“过度思考”倾向,暗示希望提升推理效率、响应延迟和可控性而非仅追求基准分数。
- 评论者争论Qwen3.7 Max是否为真正的架构升级,还是对Qwen3.5/Qwen3.6架构的微调/迭代;有用户指出在相同基础架构上进一步提升性能本身已是技术亮点。
- 多位用户等待潜在的开源27B/35B变体,但有评论推测可能根本不会有Qwen 3.7 27B,认为“Qwen 3.7”可能仅是类似Qwen 3.6 390B A30B的私有大模型,而非完整公开模型家族。
- 技术层面,用户质疑通义团队是否解决了模型的“过度思考”行为,反映对推理效率、响应速度和可控性的改进需求,而非单纯追求基准分数。
- [通义千问大概率将发布另一款27B模型](https://www.reddit.com/r/LocalLLaMA/comments/1tiwnpc/qwen_will_release_another_27b_with_high/) (活动量:1162):[图片](https://i.redd.it/g5uabdvdic2h1.jpeg)是X/Twitter对话截图,xiong-hui(陈)表示通义正在“等待确切路线图”,但认为发布另一款
27B的可能性很高,标题暗示这是对广受好评的Qwen 3.6 27B的延续。技术意义在于推测通义将继续优化中型密集模型的参数效率/“智能密度”,而非仅扩展到更大规模的MoE模型。 评论主要围绕本地推理实用性展开:部分用户希望推出122B-A10BMoE模型,而另一部分认为27B对16GB显存用户过于沉重,更倾向35B/A3B风格的MoE模型,以便在消费级游戏本或混合CPU/GPU环境运行。
- 多位评论讨论27B模型在本地推理中的差距:
16GB VRAM用户指出在可用量化级别下难以运行27B模型,而假设中的Qwen 35B MoE / A3B风格模型通过混合CPU/GPU推理可能更实用,且能在游戏本上运行。
- 用户对更大密集型Qwen变体表现出兴趣,如
50B–80B,有评论指出Qwen 27B在MTP(多任务处理)上已非常快速,愿意以部分生成速度换取更高参数量和潜在质量提升。
- 模型规模需求集中在MoE和密集扩展路径:提议目标包括Qwen 3.7 122B-A10B、
50B–80BMoE,以及密集型10B、20B、30B、50B或80B版本,反映对高端质量与本地可运行层级的双重需求。