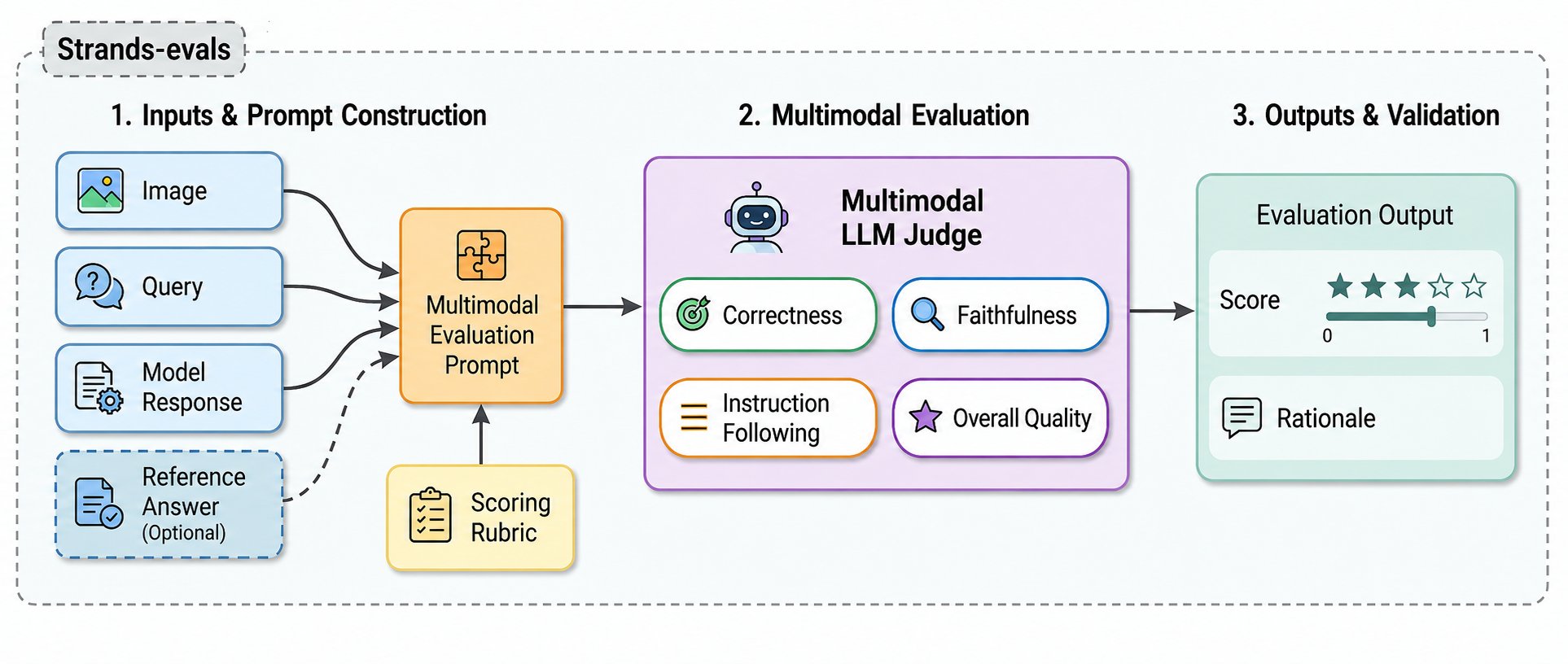
多模态评估器:Strands Evals中图像到文本任务的MLLM-as-a-Judge
AWS Machine Learning Blog2366 字 (约 10 分钟)
85
AWS发布了四种多模态评估器(Overall Quality, Correctness, Faithfulness, Instruction Following),使用MLLM-as-a-Judge方法,通过直接向模型提供图像源数据,评估多模态任务中模型响应是否与图像内容一致,可有效检测视觉幻觉和事实错误。
入选理由:Gartner预测到2030年,80%的企业软件将采用多模态技术,比2024年不足10%大幅增长,凸显自动化多模态评估的重要性。
精选文章#AWS#多模态评估#Strands Evals#MLLM-as-a-Judge#图像理解英文