高效推理MiniMax-M3:解锁1M令牌上下文和多模态能力
Together AI Blog1686 字 (约 7 分钟)
87
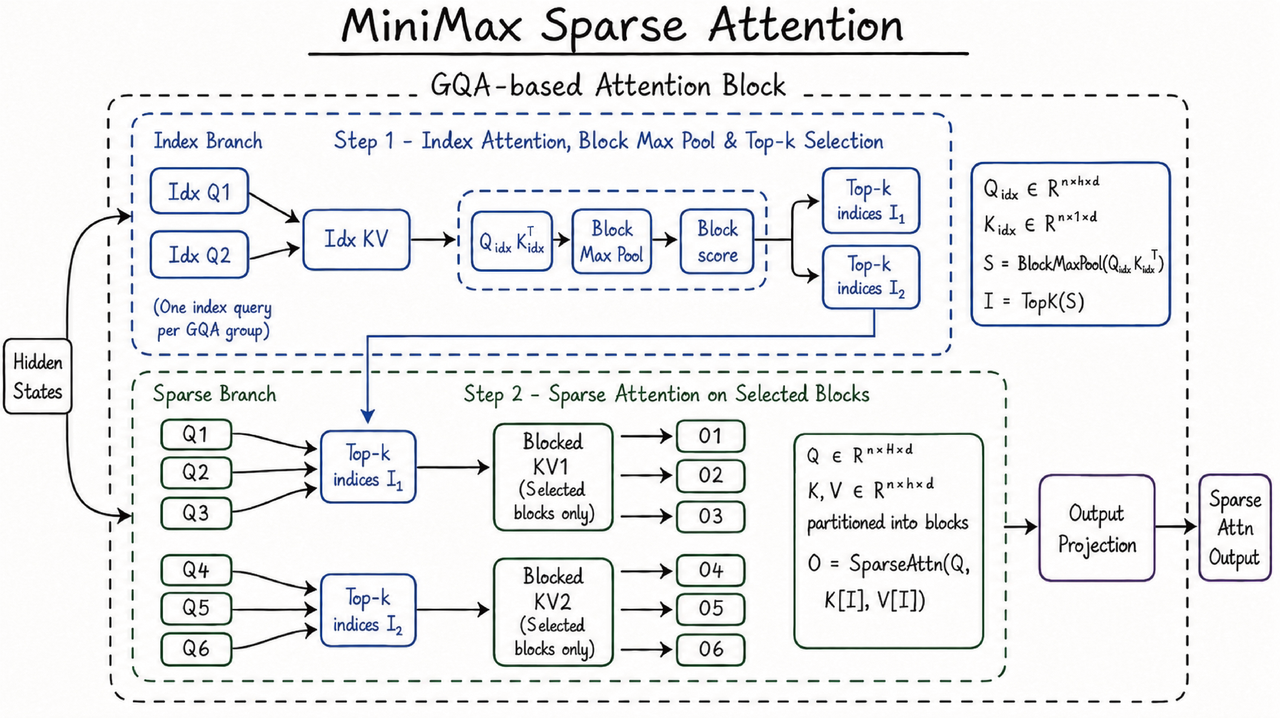
Together AI优化了MiniMax M3模型的部署,通过架构和工程创新实现81–125%吞吐量提升。
入选理由:MiniMax M3 supports 1M-token context and native multimodality, making it suitable for complex real-world tasks.
精选文章#MiniMax#M3#稀疏注意力#多模态#推理优化英文