You should start fine-tuning your own models. For real. You can get better answers with a free ope...
Paul Couvert(@itsPaulAi)229 字 (约 1 分钟)
85
工程师应优先考虑微调本地开源模型以提升特定任务性能,避免云依赖和费用问题。
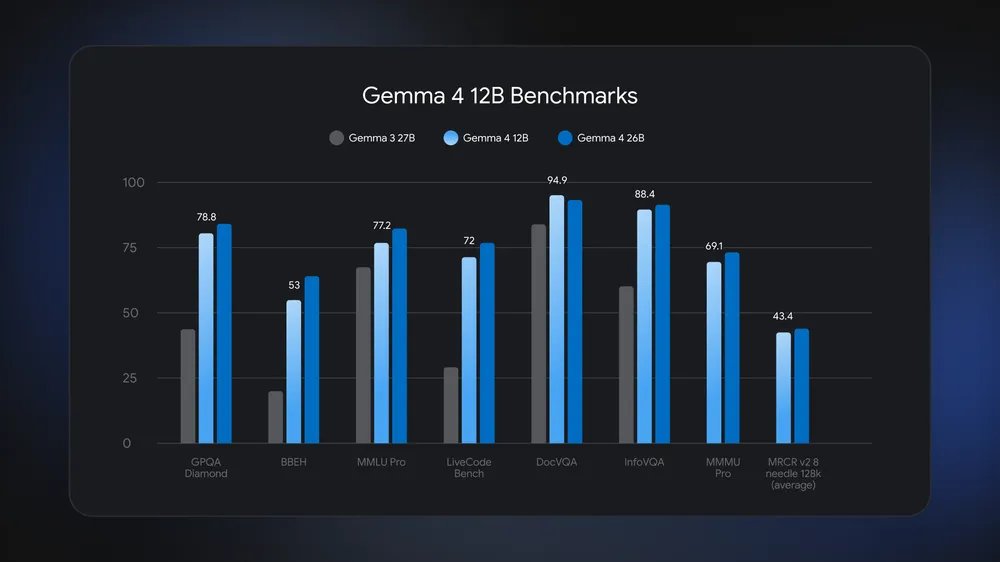
入选理由:使用Gemma 4或Qwen 3.5/3.6作为基础模型进行微调可获得更优结果
精选推文#AI模型#微调#开源#本地部署中英混合