Blazing fast on-device GenAI with LiteRT-LM
Google Developers Blog1574 字 (约 7 分钟)
75
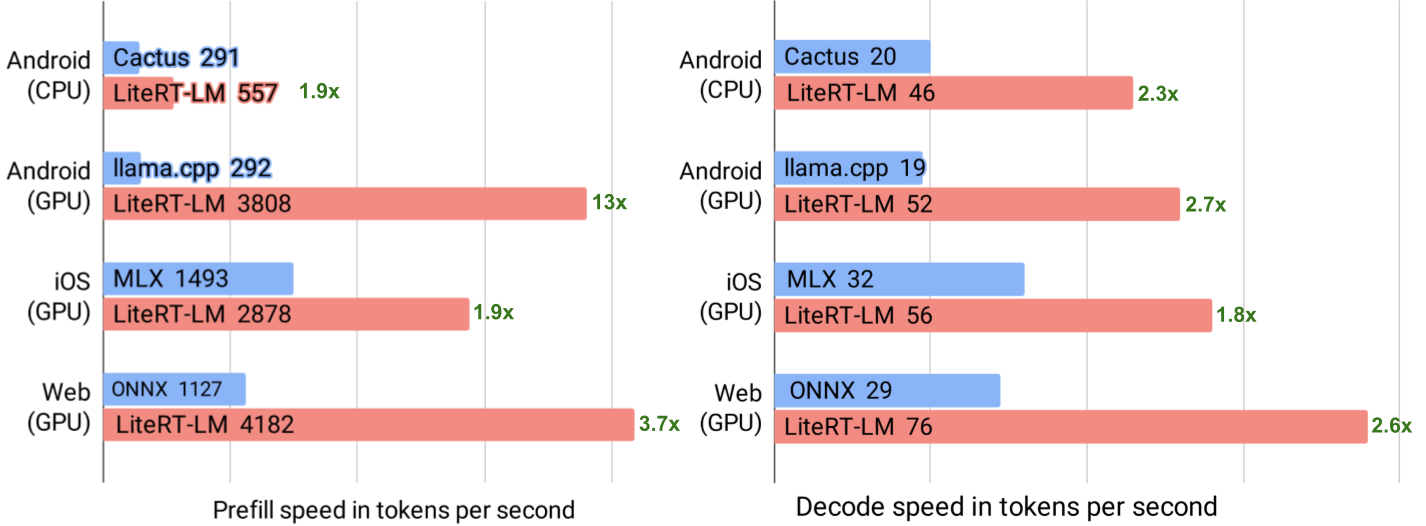
Google AI Edge introduces LiteRT-LM, an optimized inference engine for deploying Gemma 4 models on edge devices, supporting Android, iOS, and web platforms with GPU inference reaching 76 tokens/sec and Multi-Token Prediction delivering up to 2.2x speedup.
入选理由:LiteRT-LM 在 Android GPU (OpenCL) 上实现 52 tokens/sec 解码速度,iOS (Metal) 达 56 tokens/sec,WebGPU 在 MacBook Pro 上可达 76 tokens/sec
FeaturedArticle#Google AI Edge#LiteRT-LM#Gemma 4#Edge AI#On-device Inference英文
