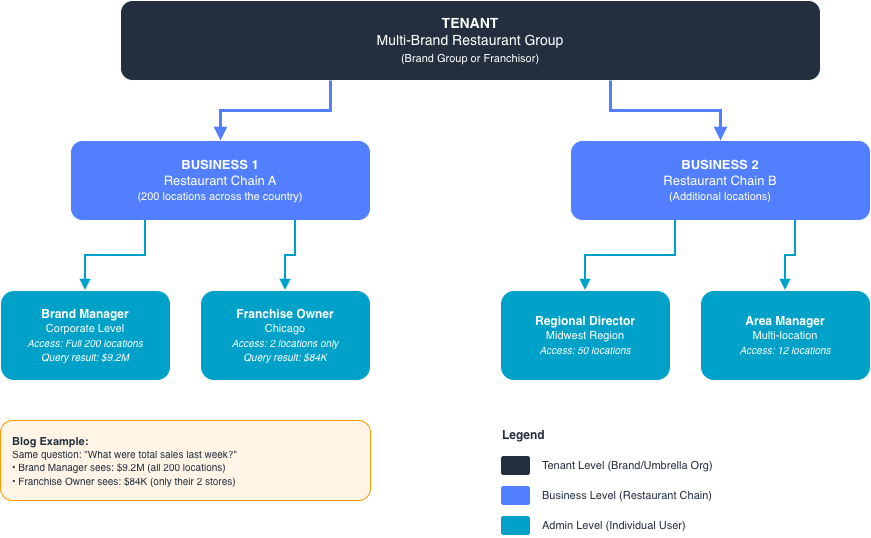
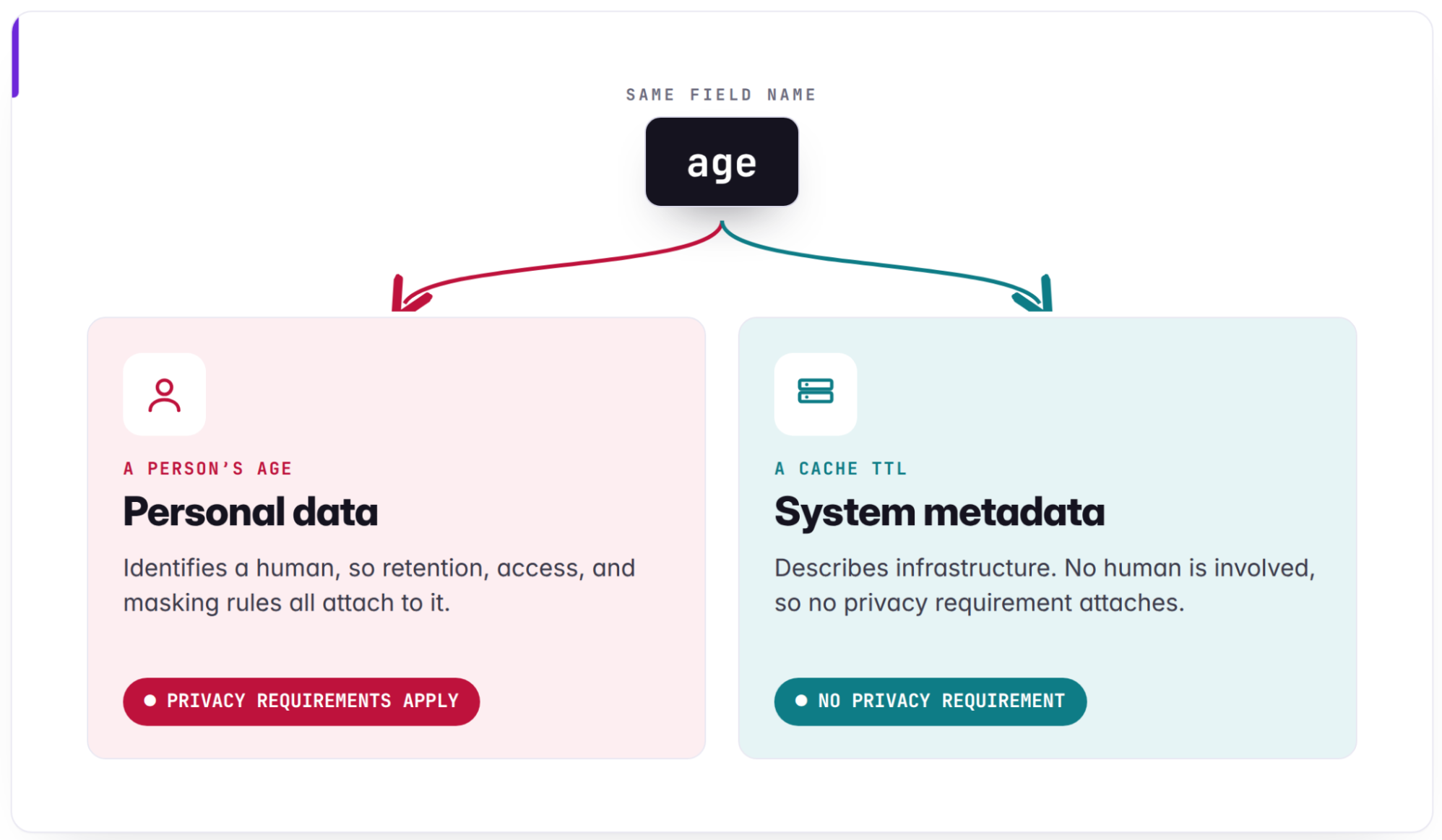
NEW POST LLMs generate code incredibly fast, but to ensure they generate exactly what is intended, ...
Martin Fowler(@martinfowler)125 字 (约 1 分钟)
85
DSL和良好抽象能显著提升LLM代码生成的可靠性和可审查性,Martin Fowler推荐该实践。
入选理由:DSL为LLM代码生成提供明确边界,降低意外输出风险
精选推文#LLM#DSL#代码生成#软件工程中英混合