精选文章#强化学习#奖励函数中文
模型
Language Models
别名:LLMs、GPT、Codex
大型语言模型,如 GPT 或 Codex,用于生成和预测复杂模式。
已跟踪 4 条高相关材料
TraeAI 观察
最近变化
2026-06-02 · 语言模型被用作选择性代理,预测 GPU 内核的最佳配置。
为什么值得关注
Language Models 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
AIAI AccelerationAI 架构Gary MarcusGPU
如果只读 3 篇
1
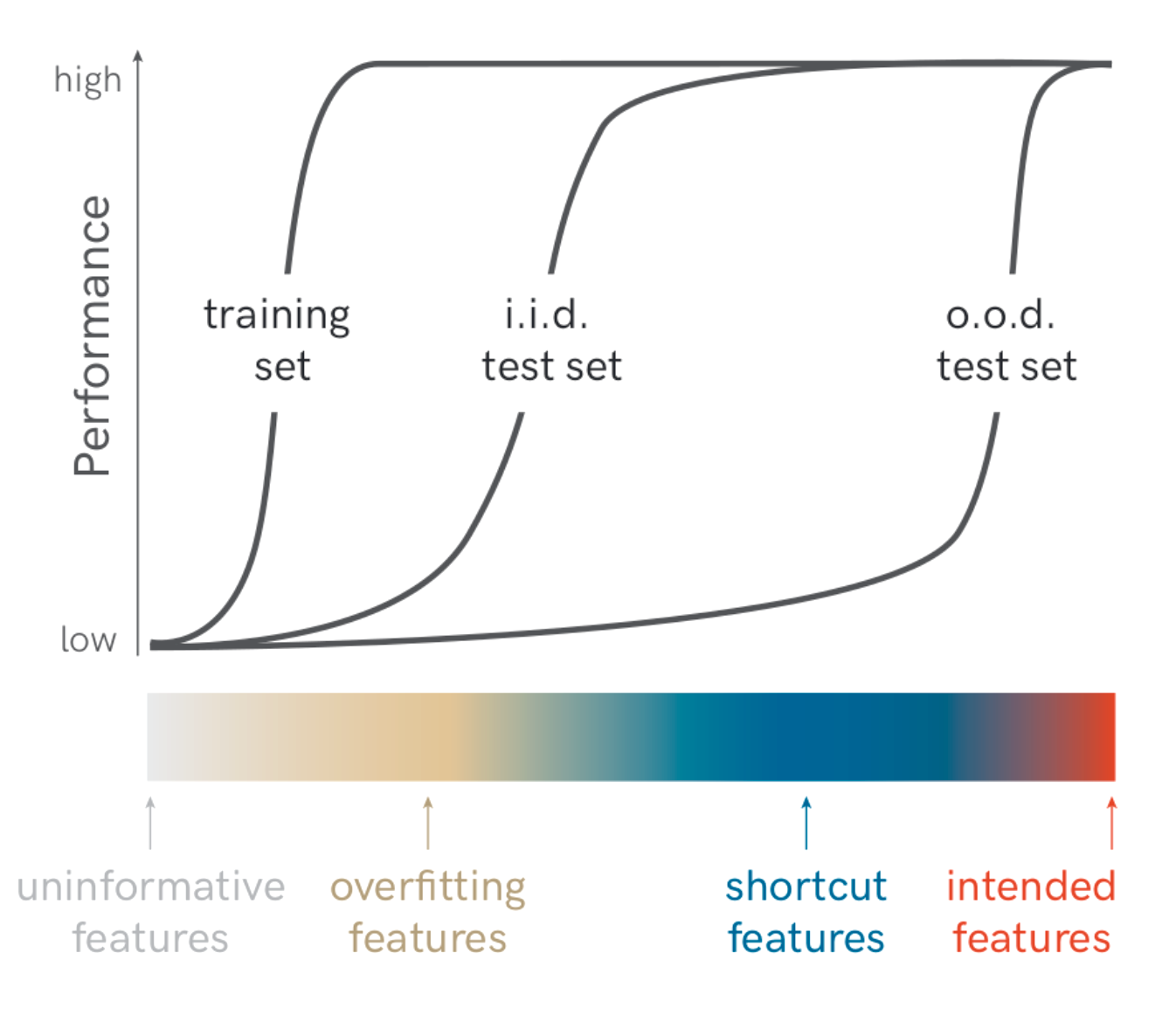
Reward Hacking in Reinforcement Learning
Lil'Log · 8.5 分
文章探讨了强化学习中的奖励黑客问题,分析其成因、影响及潜在解决方案。
2
GPU Forecasters Language Models as Selective Surrogates for Kernel Runtime Optimization
AK(@_akhaliq) · 7.5 分
本文探讨了利用语言模型作为选择性代理进行 GPU 内核运行时优化的新方法,通过预测和选择最优内核配置,显著提升了性能。
3
AI Models That Live in Time
Last Week in AI · 7.5 分
文章指出,传统语言模型缺乏时间感知能力,而最新研究通过将时间作为维度引入多模态模型,实现了模型在时间流中的持续存在,标志着流式模型的重大演进。
相关材料
已收录 4 条与 Language Models 相关的内容,按评分排序。

GPU 预测器:语言模型作为内核运行时优化的选择性代理
AK(@_akhaliq)64 字 (约 1 分钟)
75
本文探讨了利用语言模型作为选择性代理进行 GPU 内核运行时优化的新方法,通过预测和选择最优内核配置,显著提升了性能。
入选理由:语言模型被用作选择性代理,预测 GPU 内核的最佳配置。
精选推文#GPU#语言模型#内核优化#运行时性能#AI 加速英文
生活在时间中的AI模型
Last Week in AI148 字 (约 1 分钟)
75
文章指出,传统语言模型缺乏时间感知能力,而最新研究通过将时间作为维度引入多模态模型,实现了模型在时间流中的持续存在,标志着流式模型的重大演进。
入选理由:传统语言模型缺乏时间上下文,仅在输入文本后输出结果。
精选视频#AI#语言模型#多模态#时间感知#流式模型英文

我六年来一直在说的事。也许现在你们会相信了?
Gary Marcus(@GaryMarcus)129 字 (约 1 分钟)
72
AI真正的未来在于理解物理、感知和空间世界,而非仅依赖语言模型,李飞飞指出行业对大语言模型的过度关注存在战略偏差。
入选理由:李飞飞指出AI产业过度聚焦语言模型,忽视了物理与视觉世界的理解。
精选推文#AI 架构#大语言模型#视觉智能#李飞飞#Gary Marcus英文