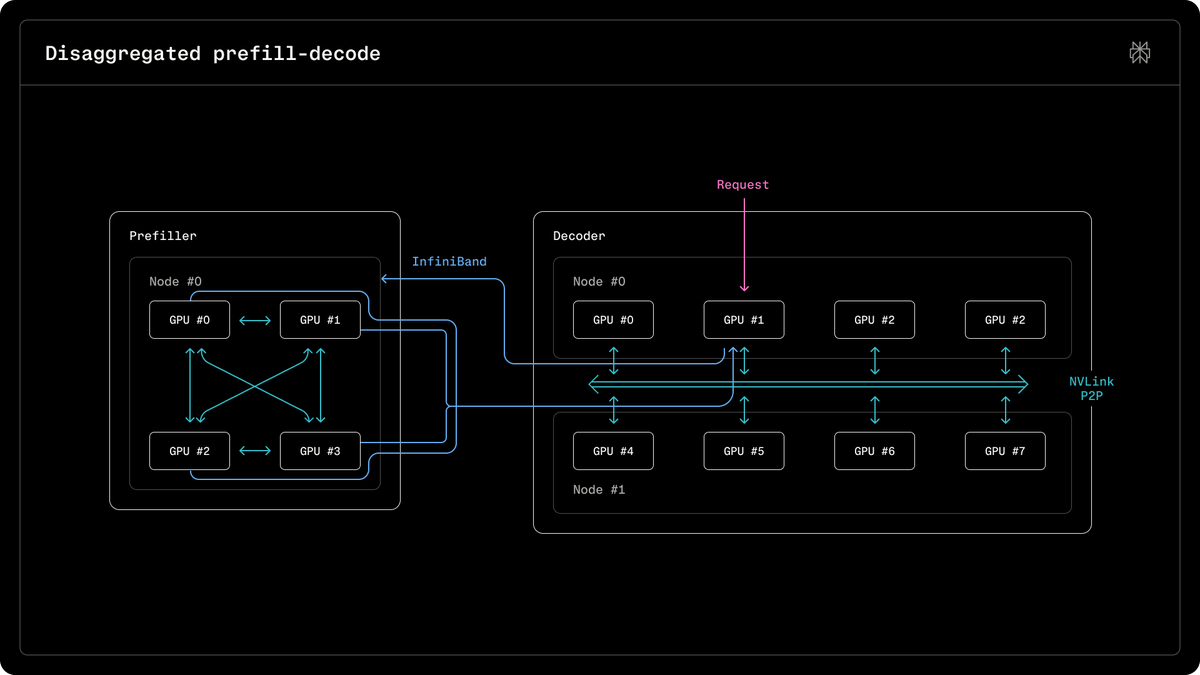
我们在 NVIDIA GB200 NVL72 Blackwell 机架上发布了 Qwen3 235B 模型的部署研究
Perplexity(@perplexity_ai)101 字 (约 1 分钟)
85
Perplexity 发布了关于如何在 NVIDIA GB200 NVL72 Blackwell 机架上部署 Qwen3 235B 模型的研究,GB200 在大规模 MoE 模型的高吞吐量推理方面优于 Hopper。
入选理由:Qwen3 235B 模型在 NVIDIA GB200 上实现了高效的高吞吐量推理。
精选推文#NVIDIA#GB200#Qwen3#MoE#高性能计算中文
