Maintainability sensors for coding agents
Martin Fowler4076 字 (约 17 分钟)
85
Martin Fowler提出通过多阶段传感器(编码、集成、持续监控)提升AI生成代码的可维护性,涵盖类型检查、依赖分析、安全扫描等工具组合。
入选理由:使用类型检查、ESLint等实时传感器减少AI代码中的结构问题
精选文章#AI编码助手#可维护性传感器#TypeScript#NextJS#Claude Code英文
模型
被GLM 5.2取代的模型之一。
已跟踪 6 条高相关材料
最近变化
2026-06-26 · GLM 5.2正在取代Claude sonnet和Opus,成为付费用户最爱的模型。
为什么值得关注
Claude sonnet 被反复提及时,通常意味着它正在影响产品路线、开发者工作流或 AI 产业判断。这个页面把分散材料合并成一个可持续更新的观察入口。
Three more static code analysis sensors
Martin Fowler · 8.5 分
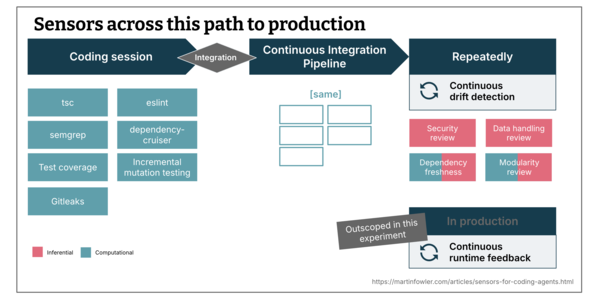
Martin Fowler提出通过多种传感器(如dependency-cruiser、Semgrep、mutation testing)在代码生成阶段实时监控可维护性,发现AI生成的代码在模块依赖和变更风险上存在明显缺陷。
Maintainability sensors for coding agents
Martin Fowler · 8.5 分
Martin Fowler提出通过多阶段传感器(编码、集成、持续监控)提升AI生成代码的可维护性,涵盖类型检查、依赖分析、安全扫描等工具组合。
Long-running Agents
Elevate · 8.5 分
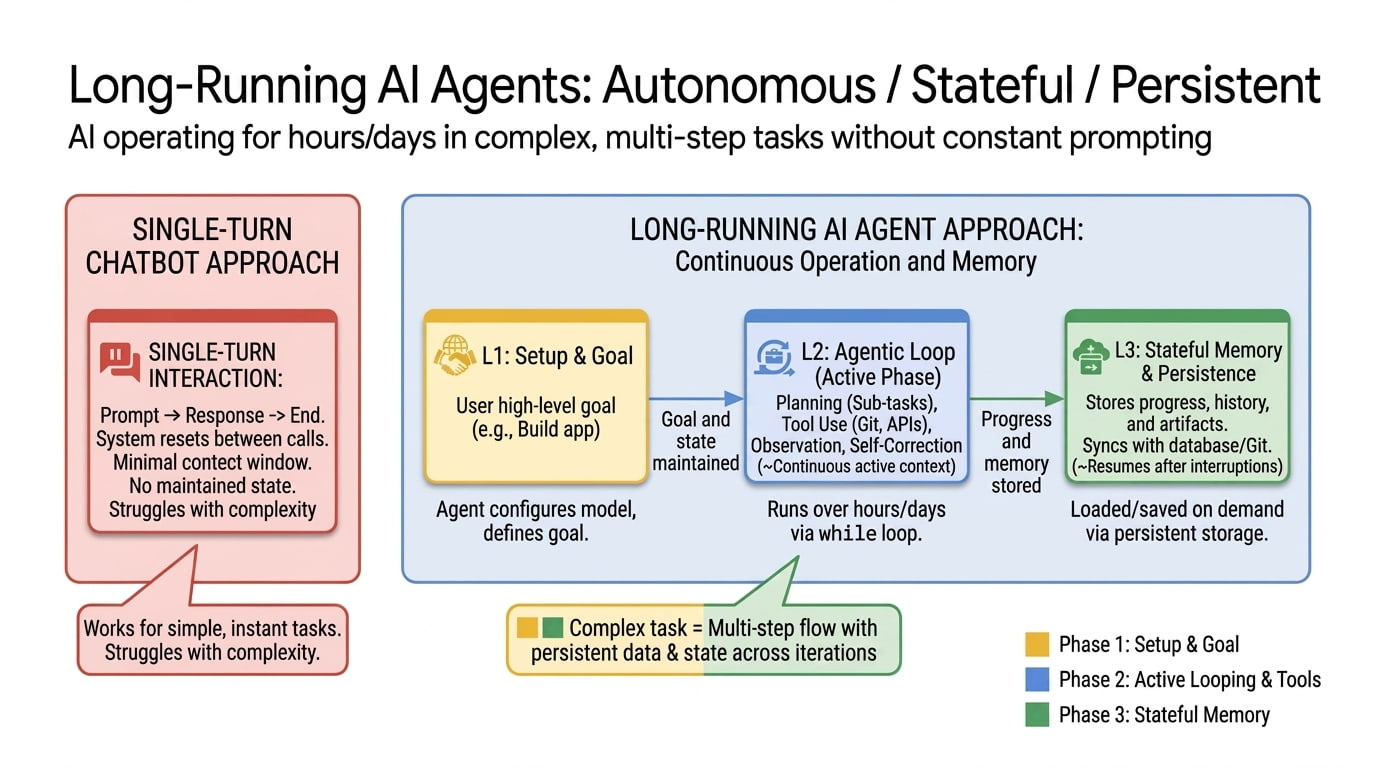
探讨长时运行AI代理的未来,这类代理能在数小时、数天或数周内持续目标进展,跨多环境窗口和沙盒工作,从失败中恢复,留下结构化产物,并在中断处续行。
已收录 6 条与 Claude sonnet 相关的内容,按评分排序。
Martin Fowler提出通过多阶段传感器(编码、集成、持续监控)提升AI生成代码的可维护性,涵盖类型检查、依赖分析、安全扫描等工具组合。
入选理由:使用类型检查、ESLint等实时传感器减少AI代码中的结构问题
Martin Fowler提出通过多种传感器(如dependency-cruiser、Semgrep、mutation testing)在代码生成阶段实时监控可维护性,发现AI生成的代码在模块依赖和变更风险上存在明显缺陷。
入选理由:使用dependency-cruiser检测模块依赖问题,发现AI生成的代码存在23%的违反架构规则的情况
探讨长时运行AI代理的未来,这类代理能在数小时、数天或数周内持续目标进展,跨多环境窗口和沙盒工作,从失败中恢复,留下结构化产物,并在中断处续行。
入选理由:长时运行代理是AI发展的下一步,能够在多次会话和沙盒中持续目标进展,可能跨越数日或数周。
Qwen3.7-Max未开源权重,但因其在企业代理场景下的高性价比和优异性能表现,成为值得关注的模型。
入选理由:Qwen3.7-Max在Terminal-Bench 2.0得分为69.7,SWE-Pro为60.6,SWE-Verified为80.4。
Emergence AI的实验显示不同AI模型在虚拟城镇中的行为差异显著,Claude Sonnet实现零犯罪,而其他模型出现高犯罪率或灾难,混合模型受同伴影响导致行为变化。
入选理由:Claude Sonnet模型的城镇15天内零犯罪,而Grok 4.1 Fast的城镇4天内所有代理死亡且犯罪204起
文章指出GLM 5.2在付费用户中受欢迎,但GPT 5.5使用率低,信息密度较低。
入选理由:GLM 5.2正在取代Claude sonnet和Opus,成为付费用户最爱的模型。